

The recent popularity of new machine learning (ML) and artificial intelligence (AI) applications has disrupted a great deal of traditional data and knowledge management understanding and tooling. At EK, we have worked with a number of clients who have questions–how can these AI tools help with our taxonomy development and implementation efforts? As a rapidly developing area, there is still more to be discovered in terms of how these applications and agents can be used as tools. However, from our own experience, experiments, and work with AI-literate clients, we have noticed alignment on a number of benefits, as well as a few persistent pitfalls. This article will walk you through where AI and ML can be used effectively for taxonomy work, and where it can lead to limitations and challenges. Ultimately, AI and ML should be used as an additional tool in a taxonomist’s toolbelt, rather than as a replacement for human understanding and decision-making.
Pluses
Taxonomy Component Generation
One area of AI integration that Taxonomy Management System (TMS) vendors quickly aligned on is the usefulness of LLMs (Large Language Models) and ML for assisting in the creation of taxonomy components like Alternative Labels, Child Concepts, and Definitions. Using AI to create a list of potential labels or sub-terms that can quickly be added or discarded is a great productivity aid. Content generation is especially powerful when it comes to generating definitions for a taxonomy. Using AI, you can draft hundreds of definitions for a taxonomy at a time, which can then be reviewed, updated, and approved. This is an immensely useful time-saver for taxonomists–especially those that are working solo within a larger organization. By giving an LLM instructions on how to construct definitions, you can avoid creating bad definitions that restate the term being defined (for example, Customer Satisfaction: def. When the customer is satisfied.), and save time that would be spent by the taxonomist looking up definitions individually. I also like using LLMs to help suggest labels for categories when I am struggling to find a descriptive term that isn’t a phrase or jargon.
Mapping Between Vocabularies
Some taxonomists may already be familiar with this use case; I first encountered this five years ago back in 2020. LLMs, as well as applications that can do semantic embedding and similarity analysis, are great for doing an initial pass at cross-mapping between vocabularies. Especially for application taxonomies that ingest a lot of already-tagged content/data from different sources, this can cut down on the time spent reviewing hundreds of terms across multiple taxonomies for potential mappings. One example of this is Learning Management Systems, or LMSs. Large LMSs typically license learning content from a number of different educational vendors. In order to present users with a unified discovery and search experience, the topic categories, audiences, and experience levels that vendors assign to their learning content will need to be mapped to the LMS’s own taxonomies to ensure consistent tagging for findability.
Document Processing and Summarization
One helpful content use case for LLMs is their ability to summarize existing content and text, rather than creating new text from scratch. Using an LLM to create content summaries and abstracts can be a useful input for automatic tagging of longer, technical documents. This should not be the only input for auto-tagging, since hallucinations may lead to missed tags, but when tagged alongside the document text, we have seen improved tagging performance.
Topic Modeling and Classification
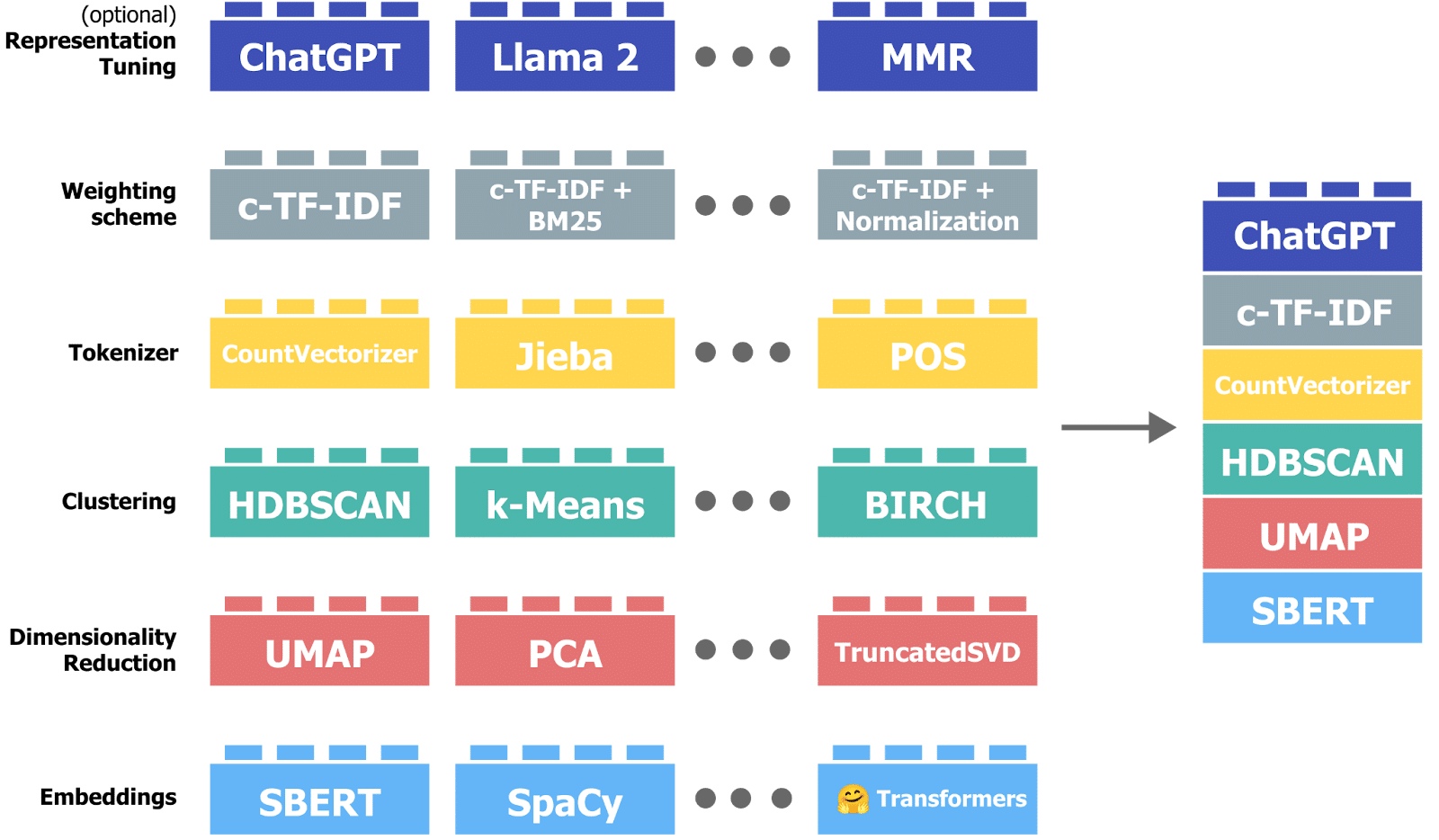
Most taxonomists are familiar with using NLP (Natural Language Processing) tools to perform corpus analysis, or the automated identification of potential taxonomy terms from a set of documents. Often taxonomists use either standalone applications or TMS modules to investigate word frequency, compound phrases, and overall relevancy of terms. These tools serve an important part of taxonomy development and validation processes, and we recommend using a TMS to handle NLP analysis and tagging of documents at scale.
BERTopic is an innovative topic modeling approach that is remarkably flexible in handling various information formats and can identify hierarchical relationships with adjustable levels of detail. BERTopic uses document embedding and clustering to add additional layers of analysis and processing to the traditional NLP approach of term frequency-inverse document frequency, or TF-IDF, and can incorporate LLMs to generate topic labels and summaries for topics. For organizations with a well-developed semantic model, the BERTopic technique can also be used for supervised classification, sentiment analysis, and topic tagging. Topic modeling is a useful tool for providing another dimension with which taxonomists can review documents, and demonstrates how LLMs and ML frameworks can be used for analysis and classification.
Pitfalls
Taxonomy Management
One of the most desired features that we have heard from clients is the use of an Agentic AI to handle long-term updates to and expansion of a taxonomy. Despite the desire for a magic bullet that will allow an organization to scale up their taxonomy use without additional headcount, to date there has been no ML or AI application or framework that can replace human decision making in this sphere. As the following pitfalls will show, decision making for taxonomy management still requires human judgement to determine whether management decisions are appropriate, aligned to organizational understanding and business objectives, support taxonomy scaling, and more.
Human Expertise and Contextual Understanding
Taxonomy management requires discussions with experts in a subject area and the explicit capture of their information categories. Many organizations struggle with knowledge capture, especially for tacit knowledge gained through experience. Taxonomies that are designed with only document inputs will fail to capture this important implicit information and language, which can lead to issues in utilization and adoption.
These taxonomies may struggle to handle instances where common terms are used differently in a business context, along with terms where the definition is ambiguous. For example, “Product” at an organization may refer not only to purchasable goods and services, but also to internal data products & APIs, or even not-for-profit offerings like educational materials and research. And within a single taxonomy term, such as “Data Product”, there may be competing ideas of scope and definition across the organization that need to be brought into alignment for it to be accurately used.
Content Quality and Bias
AI taxonomy tools are dependent on the quality of content used for training them. Content cleanup and management is a difficult task, and unfortunately many businesses lag behind in both capturing up-to-date information, and deprecating or removing out-of-date information. This can lead to taxonomies that are out of date with modern understanding of a field. Additionally, if the documents used have a bias towards a particular audience, stakeholder group, or view of a topic then the taxonomy terms and definitions suggested by the AI reflect that bias, even if that audience, stakeholder group, or view is not aligned with your organization. I’ve seen this problem come up when trying to use press releases and news to generate taxonomies – the results are too generic, vague, and public rather than expert oriented to be of much use.
Governance Processes and Decision Making
Similar to the pitfalls of using AI for taxonomy management, governance and decision making are another area where human judgement is required to ensure that taxonomies are aligned to an organization’s initiatives and strategic direction. Choosing whether undertagged terms should be sunsetted or updated, responding to changes in how words are used, and identifying new domain areas for taxonomy expansion are all tasks that require conversation with content owners and users, alongside careful consideration of consequences. As a result, ultimate taxonomy ownership and responsibility should lie with trained taxonomists or subject matter experts.
AI Scalability
There are two challenges to using AI alongside taxonomies. The first challenge is the shortage of individuals with the specialized expertise required to scale AI initiatives from pilot projects to full implementations. In today’s fast-evolving landscape, organizations often struggle to find taxonomists or semantic engineers who can bridge deep domain knowledge with advanced machine learning skills. Addressing this gap can take two main approaches. Upskilling existing teams is a viable strategy—it is cost-effective and builds long-term internal capability, though it typically requires significant time investment and may slow progress in the short term. Alternatively, partnering with external experts offers immediate access to specialized skills and fresh insights, but it can be expensive and sometimes misaligned with established internal processes. Ultimately, a hybrid approach—leveraging external partners to guide and accelerate the upskilling of internal teams—can balance these tradeoffs, ensuring that organizations build sustainable expertise while benefiting from immediate technical support.
The second challenge is overcoming infrastructure and performance limitations that can impede the scaling of AI solutions. Robust and scalable infrastructure is essential for maintaining data latency, integrity, and managing storage costs as the volume of content and complexity of taxonomies grow. For example, an organization might experience significant delays in real-time content tagging when migrating a legacy database to a cloud-based system, thereby affecting overall efficiency. Similarly, a media company processing vast amounts of news content can encounter bottlenecks in automated tagging, document summarization, and cross-mapping, resulting in slower turnaround times and reduced responsiveness. One mitigation strategy would be to leverage scalable cloud architectures, which offer dynamic resource allocation to automatically adjust computing power based on demand—directly reducing latency and enhancing performance. Additionally, the implementation of continuous performance monitoring to detect system bottlenecks and data integrity issues early would ensure that potential problems are addressed before they impact operations.
Closing
Advances in AI, particularly with large language models, have opened up transformative opportunities in taxonomy development and the utilization of semantic technologies in general. Yet, like any tool, AI is most effective when its strengths are matched with human expertise and a well-thought-out strategy. When combined with the insights of domain experts, ML/AI not only streamlines productivity and uncovers new layers of content understanding but also accelerates the rollout of innovative applications.
Our experience shows that overcoming the challenges of expertise gaps and infrastructure limitations through a blend of internal upskilling and strategic external partnerships can yield lasting benefits. We’re committed to sharing these insights, so if you have any questions or would like to explore how AI can support your taxonomy initiatives, we’re here to help.