
To drive future innovation, research organizations increasingly seek to develop advanced platforms that enhance the findability and connectivity of their knowledge, data, and content–empowering more efficient and impactful R&D efforts. However, many face challenges due to decentralized information systems, where critical data and content remain siloed, inaccessible, and opaque to users. Much of this content (i.e., publications, reports, technical drawings, etc.) is unstructured or stored in analog formats, making it difficult to discover without proper metadata and search functionality. Additionally, inefficiencies and redundancies abound when there is limited visibility into past work, expertise, and the processes for centralizing and sharing institutional knowledge. These challenges become even more pressing as experienced professionals retire, risking the loss of valuable institutional and tacit knowledge, and leading to gaps in expertise and identifying it.
The semantic layer framework acts as a critical bridge between raw, unstructured data and modern knowledge platforms, enabling seamless integration, organization, and retrieval of information. By leveraging structured metadata, AI-supplemented auto-classification, and knowledge graphs, this framework enhances the discoverability and usability of dispersed content while enabling inference-based relationships to be surfaced. Beyond its technical role, it also provides a strategic foundation for knowledge management by guiding the implementation of process and governance models that ensure consistency, accessibility, and long-term sustainability. In the following section, we will explore two real-world cases that illustrate how this approach has been successfully implemented to address the business challenges outlined above.
Case 1
Challenge: Identifying experts in specific research areas with experience on past projects is complex and time-consuming, requiring extensive institutional knowledge, and relying on informal networks and word of mouth.
Solution: Project and Expert Finder
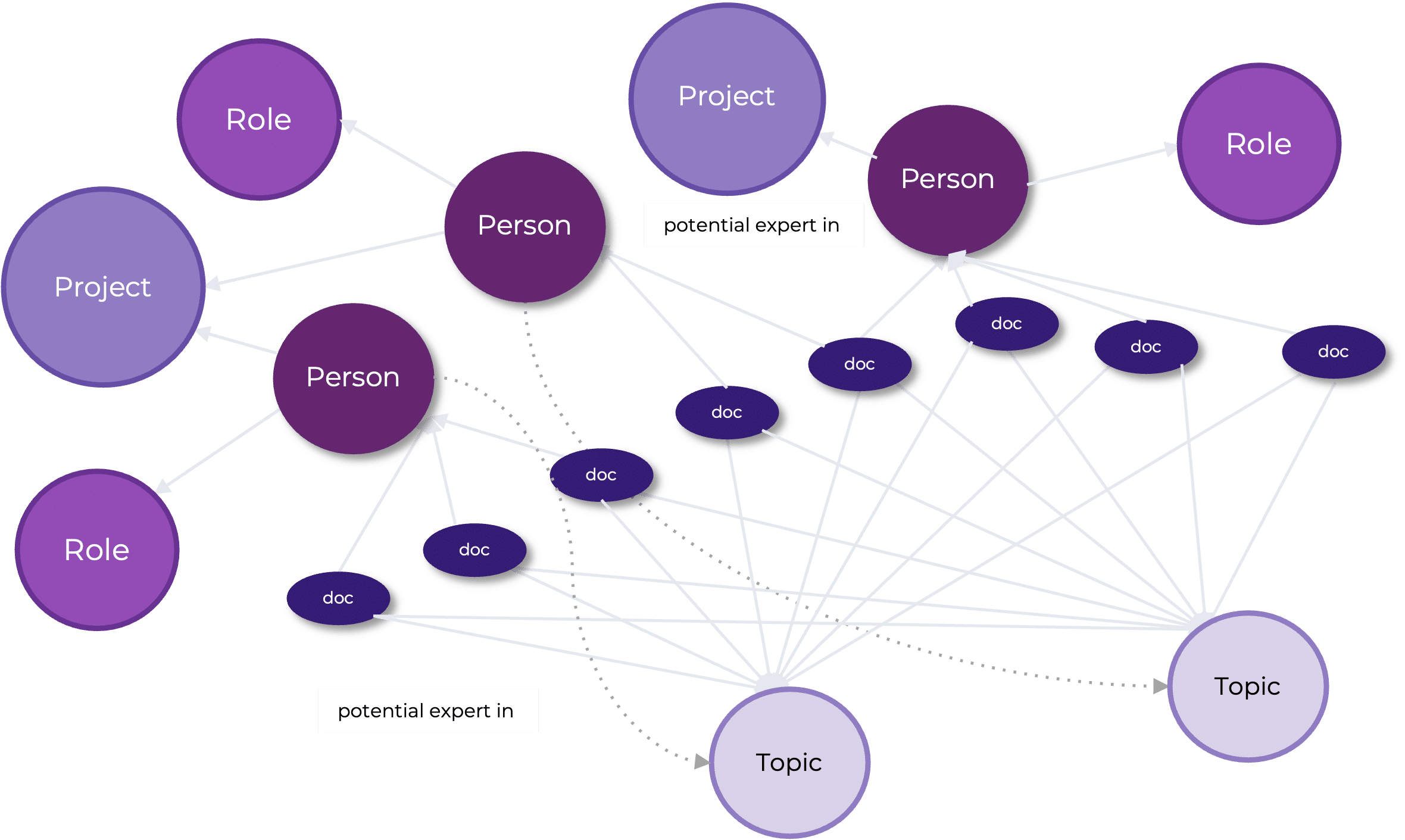
A large, federally-funded engineering research and development center relied heavily on personal networks and institutional memory to find individuals with specific skills and experience. They managed extensive data sources and content repositories, but it was still difficult to leverage organizational knowledge and onboard new employees efficiently. They were not linking critical entities within both structured and unstructured data and content–such as people, projects, roles, and materials. This gap hindered effective project staffing, planning, and research. The issue was further exacerbated by a retiring workforce, leading to a loss of valuable tacit knowledge.
EK implemented a scalable, adaptable semantic layer framework to develop a knowledge graph that connects people, projects, engineering components, and technical topics. This institutional knowledge graph aggregates data across 40 applications, eliminating the need for discrete data connectors, reducing costs, and serving as a centralized resource. Integrating with the enterprise search system, it enhances browsability and discoverability, providing a comprehensive view of relationships within the organization. Beyond improving access to information, the unified data within the knowledge graph can also act as a powerful input to artificial intelligence algorithms, enabling predictions and discovery of previously unknown relationships. This enhanced intelligence not only supports decision-making but also drastically reduces the time required to locate critical information–from three weeks to just five minutes–accelerating research, publication processes, and internal collaboration.
Case 2
Challenge: Disorganized and siloed content prevents seamless searchability across repositories, hinders the ability to trace the digital thread responsibly, and complicates long-term information preservation. As a result, answering critical questions about the impact of past and current work on project decisions and deliverables becomes nearly impossible.
Solution: Internal Research Platform
A federally funded energy research and development center relies on past project outcomes and experimental data to advance scientific innovation. However, researchers struggled to find relevant reports due to unstructured metadata and ineffective search capabilities, with manual metadata entry being time-consuming, error-prone, and inconsistent across systems. Analog content, inconsistent metadata standards, and fragmented information systems have created significant barriers to knowledge discovery, records management, and long-term information preservation. This exacerbates information silos, leading to knowledge loss, inefficiencies, and decision-making risks from limited access to reliable research data.
To address these challenges, EK supported the development of 5 metadata and taxonomy models tailored to tag 80,000+ documents with high precision. This was achieved through a custom auto-classification pipeline, which integrates multiple gold data sources with a TOMS (Taxonomy and Ontology Management System). By enriching both analog and native digital documents with semantic metadata, the solution facilitates enhanced content and research material discovery through a knowledge graph underlying a front-end search interface. Standardizing metadata and taxonomy models not only automates classification but also digitizes analog content and integrates several systems, significantly improving searchability and accessibility across the organization. To ensure organization-wide scalability, adoption, and sustainability, governance models were developed with strategies spanning tactical, strategic, operational, and technical domains. These models address key facets necessary for a successful long-term implementation, ensuring the framework remains adaptable and effective over time.
Conclusion
In the research and development space, ensuring that information such as expertise, project history, and past research is easily findable is critical for driving innovation, reducing inefficiencies, and managing knowledge transfer amidst retirement in a highly specialized workforce. Research organizations also benefit from using semantic layers to manage research-focused data products more consistently, leveraging graph data to find patterns and insights. Additionally, AI-driven knowledge discovery, automated metadata tagging, and interoperability across systems further enhance research efficiency and collaboration.
At EK, we specialize in delivering tailored solutions to help your organization overcome its unique data and knowledge management challenges–from strategy to implementation. Explore our Knowledge Base to learn more about our expertise and semantic layer solutions, and contact us to discuss how we can support your specific needs.