
In today’s rapidly advancing field of data science, where new technologies and methods continuously emerge, it’s essential to have a structured approach to navigate the complexities of data mining and analysis. The CRISP-DM framework–short for Cross-Industry Standard Process for Data Mining–provides a robust methodology that helps data science teams stay organized and efficient from the start of a project to its deployment. When complemented with Knowledge Intelligence (KI), CRISP-DM becomes even more powerful, embedding expert knowledge and business context into every phase of the process. This blog offers a comprehensive guide to each phase of the CRISP-DM framework, enriched with insights on integrating KI to drive actionable insights in your data science projects.
What is the CRISP-DM Framework and its Relationship with Knowledge Intelligence?
CRISP-DM is a widely adopted, six-phase methodology for executing data science projects. First developed in the 1990s, it has become a common process model used by data scientists across various industries. The framework ensures a standardized approach, with its strength rooted in a structured, iterative process that allows teams to refine and adapt their work as new data, technologies, and business needs evolve. When integrated with KI, CRISP-DM benefits from advanced techniques such as federated knowledge extraction (aggregation of disparate information) and embedding business context and expert knowledge into data processes, ensuring insights are both actionable and aligned with organizational goals.
Key Phases of the CRISP-DM Framework
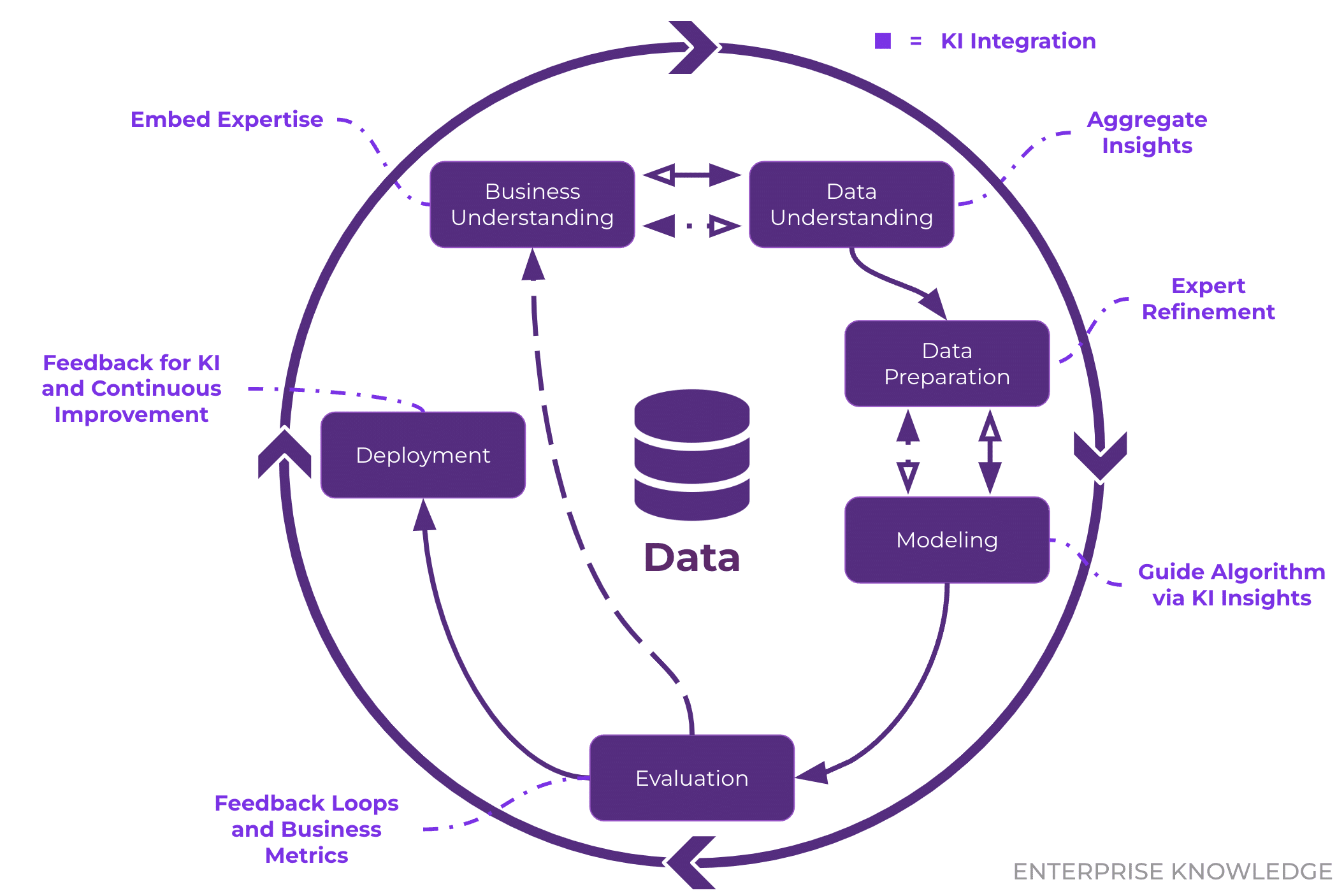
The CRISP-DM Framework is composed of six interconnected phases that guide the entire lifecycle of a data science project. Incorporating KI into each phase enhances its effectiveness:
- Business Understanding: This initial phase focuses on understanding the business objectives and requirements, setting the groundwork for all subsequent phases by defining the problem and identifying what success looks like. By embedding expert knowledge and business context through KI, teams can align data science goals with organizational objectives more effectively. For example, if a company wants to reduce customer churn, the data science team would work to define measurable metrics, such as predicting which customers are most likely to leave based on their historical interactions. This ensures that the project’s direction aligns with the business’s overarching goals and incorporates institutional expertise.
- Data Understanding: In this phase, you gather, explore, and evaluate the data to ensure it is suitable for the project. KI plays a key role by enabling the consolidation of knowledge from diverse organizational structures, including unstructured and semi-structured data. For instance, if a retail company is trying to predict customer churn, the team might explore purchase history, customer demographics, and previous interactions to identify trends or inconsistencies. Thanks to KI implementations, teams are now able to thoroughly understand the data and can ensure they’re working with the right inputs to identify any gaps early in the process that might require additional data collection.
- Data Preparation: Once the data is understood, this phase involves transforming and cleaning it to make it ready for modeling. Tasks such as handling missing values, normalizing data, and feature engineering are critical at this stage. KI supports this phase by incorporating business rules, industry insights, and expert feedback into the data transformation process. For example, in a retail churn prediction scenario, the team might create new features like average purchase frequency or time since the last purchase to boost model performance. Moreover, an embedded feedback loop helps continually refine data accuracy and ensures the data is optimally prepared for feature engineering. Expert input can also be leveraged to accurately label training data, further enhancing model reliability. This robust preparation minimizes potential issues during analysis and ensures the dataset is well-suited for the modeling phase.
- Modeling: This phase involves applying various machine learning algorithms to the prepared data in order to create models that address the business problem. KI can guide feature selection and algorithm choices by leveraging feedback loops to guide optimal algorithm and feature selection into the modeling process. For example, when predicting customer churn for a retail company, the team might consider methods such as decision trees, random forests, or logistic regression to see which model offers the best predictive accuracy. By carefully selecting and refining the models with KI measures, teams ensure that the final solution can provide meaningful insights and meet business goals.
- Evaluation: In this phase, the model is rigorously tested to ensure it meets the business objectives and delivers accurate results. Here, KI introduces an embedded feedback loop that continuously refines evaluation criteria by integrating real-time business insights and performance metrics. For example, a retail company might compare the model’s identification of at-risk customers against historical behavior patterns. This embedded loop leverages business feedback to update standardized evaluation metrics–such as precision, recall, or customer retention rates–ensuring that these metrics are aligned with the organization’s evolving priorities. If the model’s performance deviates from expectations, the feedback mechanism guides timely adjustments to either the input data or model parameters. This iterative process not only guarantees technical robustness but also ensures that the model remains closely aligned with the business goals before deployment.
- Deployment: In the final phase, the model is integrated into the business environment, making it available for use in real-world applications. This phase may involve integrating the model into existing systems, creating user interfaces, or automating workflows based on the model’s predictions. Importantly, the outputs from the deployed solution are channeled back into knowledge intelligence initiatives–such as semantic layers or Retrieval-Augmented Generation (RAG) systems–to continuously refine and enhance earlier stages of the CRISP-DM process. For example, a retail company might deploy their churn prediction model by incorporating it into their customer relationship management (CRM) system, allowing the marketing team to automatically identify and target at-risk customers with retention campaigns, while the model’s performance data is used to update and improve KI-driven insights. Continuous monitoring ensures that the model remains accurate and relevant as business conditions and data evolve, creating a dynamic feedback loop where CRISP-DM informs KI, and KI, in turn, enhances future deployments.
Benefits of Using CRISP-DM
One of the key benefits of CRISP-DM is that it provides a clear roadmap for data science projects. Teams that adopt CRISP-DM often find that it enhances collaboration by aligning technical tasks with business objectives. This framework ensures that all stakeholders–data scientists, business analysts, and leadership–are on the same page throughout the project. Additionally, CRISP-DM’s flexibility allows it to be adapted to different industries and project scales, making it a versatile tool in any data science toolkit.
When Knowledge Intelligence is integrated into the framework, these benefits are amplified. KI helps to embed organizational expertise, unify disparate data sources, and ensure that every phase of the process is driven by contextually rich, actionable insights.
Since the framework is iterative, it allows for continuous improvement. Teams can cycle through the phases as needed, making adjustments based on new insights or changing business needs. This adaptability makes CRISP-DM a strong choice for projects where the problem may evolve over time.
What Happens Without CRISP-DM?
Choosing not to use a structured framework like CRISP-DM, especially when combined with Knowledge Intelligence, can lead to several challenges in managing data science projects. Without a clear, repeatable process and the contextual enhancements that KI provides, teams may struggle with inconsistency, as they lack a roadmap to follow from start to finish. This can lead to inefficient use of resources, misaligned goals, and missed deadlines. Additionally, projects that don’t adhere to a structured process risk poor communication between stakeholders and technical teams, leading to solutions that don’t fully meet business objectives.
In the absence of organizational knowledge and an iterative framework, teams may find it difficult to adapt to changes in business requirements or data quality issues, causing delays or the need for significant rework. Ultimately, this lack of structure and context can reduce the overall effectiveness of the project and limit the ability to deliver valuable, actionable insights.
Alternatives to CRISP-DM
While CRISP-DM is a widely used framework, there are several other methodologies that can be employed in data science projects. Below are some notable alternatives, along with notes on how they might interact with KI integration:
- KDD (Knowledge Discovery in Database):
- Overview: KDD is one of the earliest frameworks for data mining, focusing heavily on the data preparation and transformation stages. It emphasizes discovering patterns and knowledge from large datasets, often used in academic or research settings.
- When to Use: KDD is ideal for projects where the primary focus is on the discovery of new, previously unknown patterns, rather than predefined business objectives.
- How it Differs: KDD tends to be more exploratory and research driven, while CRISP-DM is more focused on business applications and aligning with business goals.
- KI Integration: This methodology typically does not integrate KI directly, as its focus is on data discovery without an explicit emphasis on business context.
- SEMMA (Sample, Explore, Modify, Model, Assess):
- Overview: SEMMA, developed by SAS, is a methodology focused on the modeling aspect of data science. It follows a similar structure to CRISP-DM but places greater emphasis on model building and refinement.
- When to Use: SEMMA works well in environments where model accuracy is critical, such as predictive modeling.
- How it Differs: While CRISP-DM begins with a focus on business understanding, SEMMA jumps straight to the data, making it more suitable for model-centric projects.
- KI Integration: SEMMA can significantly benefit from KI integration. Embedding business insights and feedback loops can improve model selection and refinement, aligning technical outputs more closely with business objectives.
- Agile Data Science:
- Overview: Agile methodologies, widely used in software development, have been adapted for data science projects. Agile Data Science emphasizes collaboration, iterative development, and the flexibility to adapt to changing requirements.
- When to Use: This is ideal for projects that require rapid iteration and delivery, where feedback loops are critical and flexibility is key.
- How it Differs: Agile Data Science focuses more on the flexibility and speed of delivery, whereas CRISP-DM provides a more structured, step-by-step approach.
- KI Integration: Agile Data Science naturally lends itself to KI integration. The iterative feedback loops and close collaboration inherent in agile methods help continuously align technical outcomes with evolving business needs, leveraging KI to inform each iteration.
Conclusion
The CRISP-DM framework offers a structured, repeatable process that ensures the success of data science projects. Its focus on business objectives, data preparation, and iterative refinement makes it an invaluable tool for anyone working in the field. When paired with Knowledge Intelligence, CRISP-DM evolves into a more powerful methodology that embeds expert knowledge and domain-specific context into every phase of the process. If you would like to explore more of Enterprise Knowledge’s expertise, visit our Knowledge Base and feel free to reach out and contact us!