
Auto-classification is a valuable process for adding context to unstructured content. Nominally speaking, some practitioners distinguish between auto-classification (placing content into pre-defined categories from a taxonomy) and auto-tagging (assigning unstructured keywords or metadata, sometimes generated without a taxonomy). In this article, I use ‘auto-classification’ in the broader sense, encompassing both approaches. While it can take many forms, its primary purpose remains the same: to automatically enrich content with metadata that improves findability, helps users immediately determine relevance, and provides crucial information on where content came from and when it was made. And while tagging content is always a recommended practice, it is not always scalable when human time and effort is required to perform it. To solve this problem, we have been helping organizations automate this process and minimize the amount of manual effort required, especially in the age of AI, where organized and well-labeled information is the key to success.
This includes designing and implementing auto-classification solutions that save time and resources – using methods such as natural language processing, machine learning, and rapidly-evolving AI models such as large language models (LLMs). In this article, I will demonstrate how auto-classification processes can deliver measurable value to organizations of diverse sizes or industries, using real-world examples to illustrate the costs and benefits. I will then give an overview of common methods for performing auto-classification, comparing their high-level strengths and weaknesses, and conclude by discussing how incorporating semantics can significantly enhance the performance of these methods.
How Can Auto-Classification Help My Organization?
It’s a good bet that your organization possesses a large repository of unstructured information such as documents, process guides, and informational resources, either meant for internal use or for display on a public webpage. Such a collection of knowledge assets is valuable – but only as valuable as the organization’s ability to effectively access, manage, and utilize them. That’s where auto-classification can shine: by serving as an automated processor of your organization’s unstructured content and applying tags, an auto-classifier adds structure quickly that provides value in multiple ways, as outlined below.
Time Savings
First, an auto-classifier saves content creators time in two key ways. For one, manually reading through documents and applying metadata tags to each individually can be tedious, taking time away from content creators’ other responsibilities – as a solution, auto-classification can free up time that can be used to perform more crucial tasks. On the other end of the process, auto-classification and the use of metadata tags can improve findability, saving employees time when searching for documents. When paired with a taxonomy or set list of terms, an auto-classifier can standardize the search experience by allowing for content to be consistently tagged with a set of standard language.
Content Management and Strategy
These standard tags can also play a role in more content strategy-focused efforts, such as identifying gaps in content and content deduplication. For example, if some taxonomy terms feature no associated content, content strategists and managers may identify an organizational gap that needs to be filled via the authoring of new content. In contrast, too many content pieces identified as having similar themes can be deduplicated so that the most valuable content is prioritized for end users. These analytics-based decisions can help organizations maximize the efficacy of their content, increase content reach, and cut down on the cost of storing duplicate content.
Ensuring Security
Finally, we have seen auto-classification play a key role in keeping sensitive content and information secure. Auto-classifiers can determine what content should be tagged with certain sensitivity classifications (for example, employee addresses being tagged as visible by HR only). One example of this is through dark data detection, where an auto-classifier parses through all organizational content to identify information that should not be visible to all end users. Assigning sensitivity classifications to content through auto-tagging can help to automatically address security concerns and ensure regulatory compliance, saving organizations from the reputational and legal costs associated with data leaks.
Common Auto-Classification Methods
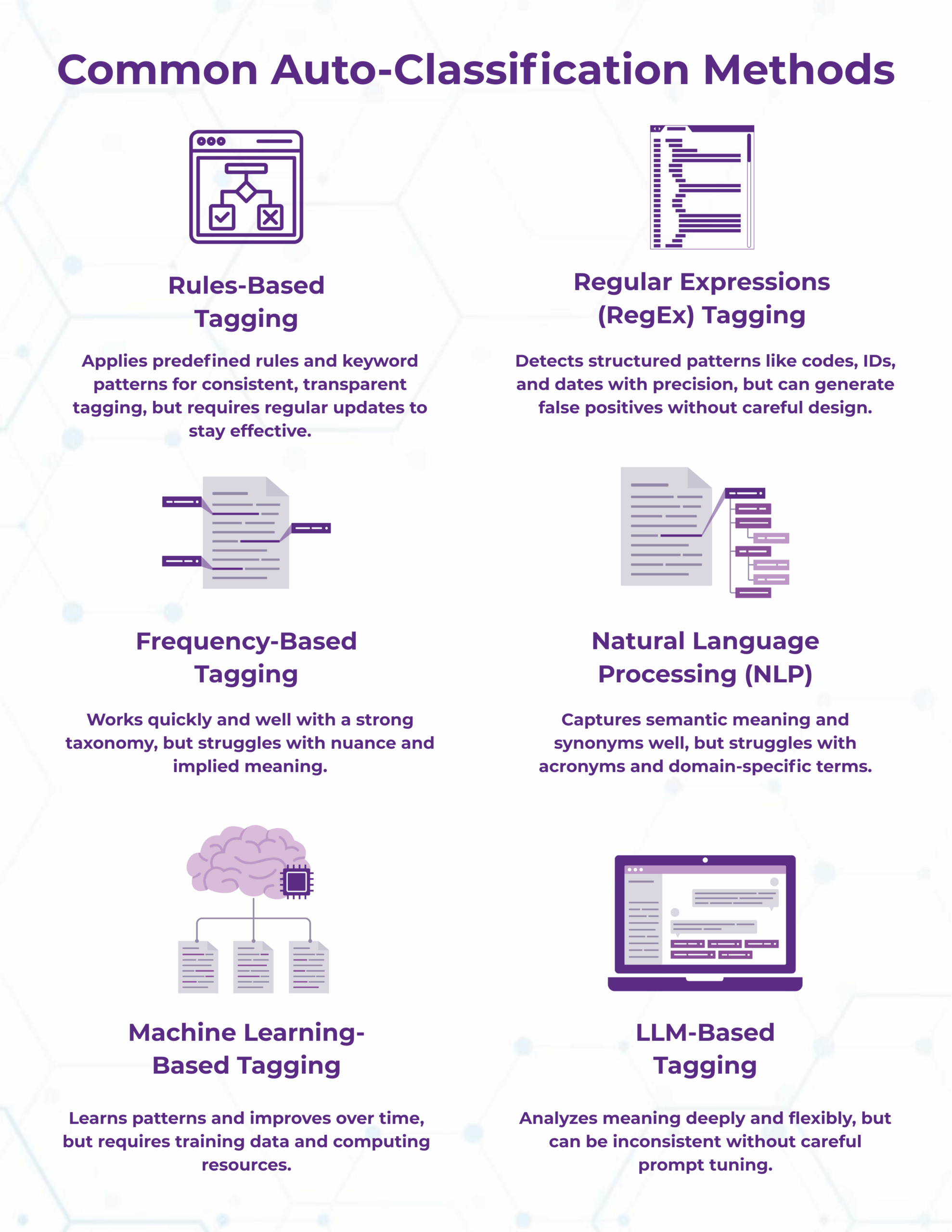
So, how do we go about tagging content automatically? Organizations can choose to employ one of a number of methods as a standalone solution, or combine them as part of a hybrid solution. Below, I will give a high-level overview of six of the most commonly used methods in auto-classification, along with some considerations for each.
1. Rules-Based Tagging: Uses deterministic rules to map content to tags. Rules can be built from dictionaries/keyword lists, proximity or co-occurrence patterns (e.g., “treatment” within 10 words of “disorder”), metadata values (author, department), or structural cues (headings, templates).
- Considerations: Highly transparent and auditable; great for regulated/compliance use cases and domain terms with stable phrasing. However, rules can be brittle, require ongoing maintenance, and may miss implied meaning or novel phrasing unless rules are continually expanded.
2. Regular Expression (RegEx) Tagging: A specialized form of rules-based tagging that applies RegEx patterns to detect and tag structured strings (for example, SKUs, case numbers, ICD-10 codes, dates, or email addresses).
- Considerations: Excellent precision for well-formed patterns and semi-structured content; lightweight and fast. Can produce false positives without careful validation of results. Best combined with other methods (such as frequency or NLP) for context checks.
3. Frequency-Based Tagging: Frequency-based tagging considers the number of times that a certain term (or variations of said term) appear in a document, and assigns the most frequently appearing tags to the content. Early search engines, website indexers, and tag-mining software relied heavily on this approach for its simplicity and transparency; however, frequency of a term does not always guarantee its importance.
- Considerations: Works well with a well-structured taxonomy with ample synonyms for terms, as well as content that has key terms appear frequently. Not as strong a method when meaning is implied/terms are not explicitly used or terms are excessively repeated.
4. Natural Language Processing (NLP): Uses basic calculations of semantic meaning (tokenization) to find the best matches by meaning between two pieces of text (such as a content piece and terms in a taxonomy).
- Considerations: Can work well for terms that are not organization/domain-specific, but struggles with acronyms/more specific terms. Better than frequency-based tagging at determining implied meaning.
5. Machine Learning-Based Tagging: Machine learning methods allow for the training of models on pre-tagged content, empowering organizations to improve models iteratively for better results. By comparing new content against patterns they have already learned/been trained on, machine learning models can infer the most relevant concepts and tags to a content piece and apply them consistently. User input can help refine the classifier to identify patterns, trends, and domain-specific terms more accurately.
- Considerations: A stock model may initially perform at a lower-than-expected level, while a well-trained model can deliver high-grade accuracy. However, this can come at the expense of time and computing resources.
6. Large Language Model (LLM)-Based Tagging: The newest form of auto-classification, this involves providing a large language model with a tagging prompt, content to tag, and a taxonomy/list of terms if desired. As interest around generative AI and LLMs grows, this method has become increasingly popular for its ability to parse more complex content pieces and analyze meaning deeply.
- Considerations: Tags content like a human, meaning results may vary/become inconsistent if the same corpus is tagged multiple times. While LLMs can be smart regarding implied meaning and content sensitivity, they can be inconsistent without specific model tuning and prompt engineering. Additionally, suffers from accuracy/precision issues when fed a large taxonomy.
Some taxonomy and ontology management systems (TOMS), such as Graphwise PoolParty or Progress Semaphore, also offer auto-classification add-ons or extensions to their platforms that make use of one or more of these methods.
The Importance of Semantics in Auto-Classification
Imagine your repository of content as a bookstore, and your auto-classifier as the diligent (but easily confused!) store manager. You have a wide number of books you want to sort into different categories, such as their audience (children, teen, adult) and genre (romance, fantasy, sci–fi, nonfiction).
Now, imagine if you gave your manager no instructions on how to sort the books. They start organizing too specifically. They put four books together on one shelf that says “Nonfiction books about history in 1814.” They put another three books on a shelf that says “Romance books in a fantasy universe with dragons.” They put yet another five books on a shelf that says “Books about knowledge management.”
Before you know it, your bookstore has 1,098 shelves, and no happy customers.
Therein lies the danger of tagging content without a taxonomy, leading to what’s known as semantic drift. While tagging without a taxonomy and creating an initial set of tags can be useful in some circumstances, such as when trying to generate tags or topics to later organize into a hierarchy as part of a taxonomy, it has its limitations. Tags often become very specific and struggle to maintain alignment in a way that makes them useful for search or for grouping larger amounts of content together. And, as I mentioned at the beginning of this article, auto-classification without a taxonomy in place is not auto-classification in the true sense of the word; rather, such approaches are auto-tagging, and may not produce the results business leaders/decision-makers expect.
I’ve seen this in practice when testing auto-classification methods with and without a taxonomy. When an LLM was given the same content corpus of 100 documents to tag, but one generated its own terms and the other was given a taxonomy, the results differed greatly. The LLM without a taxonomy generated 765 extremely domain-specific terms that often only applied to a singular content piece. In contrast, the LLM when given a taxonomy tagged the content with 240 terms, allowing the same tags to apply to multiple content pieces, creating topic clusters and groups of similar content that users can easily browse, search, and navigate, making discovery faster, more intuitive, and less fragmented than when every piece is labeled with unique, one-off terms
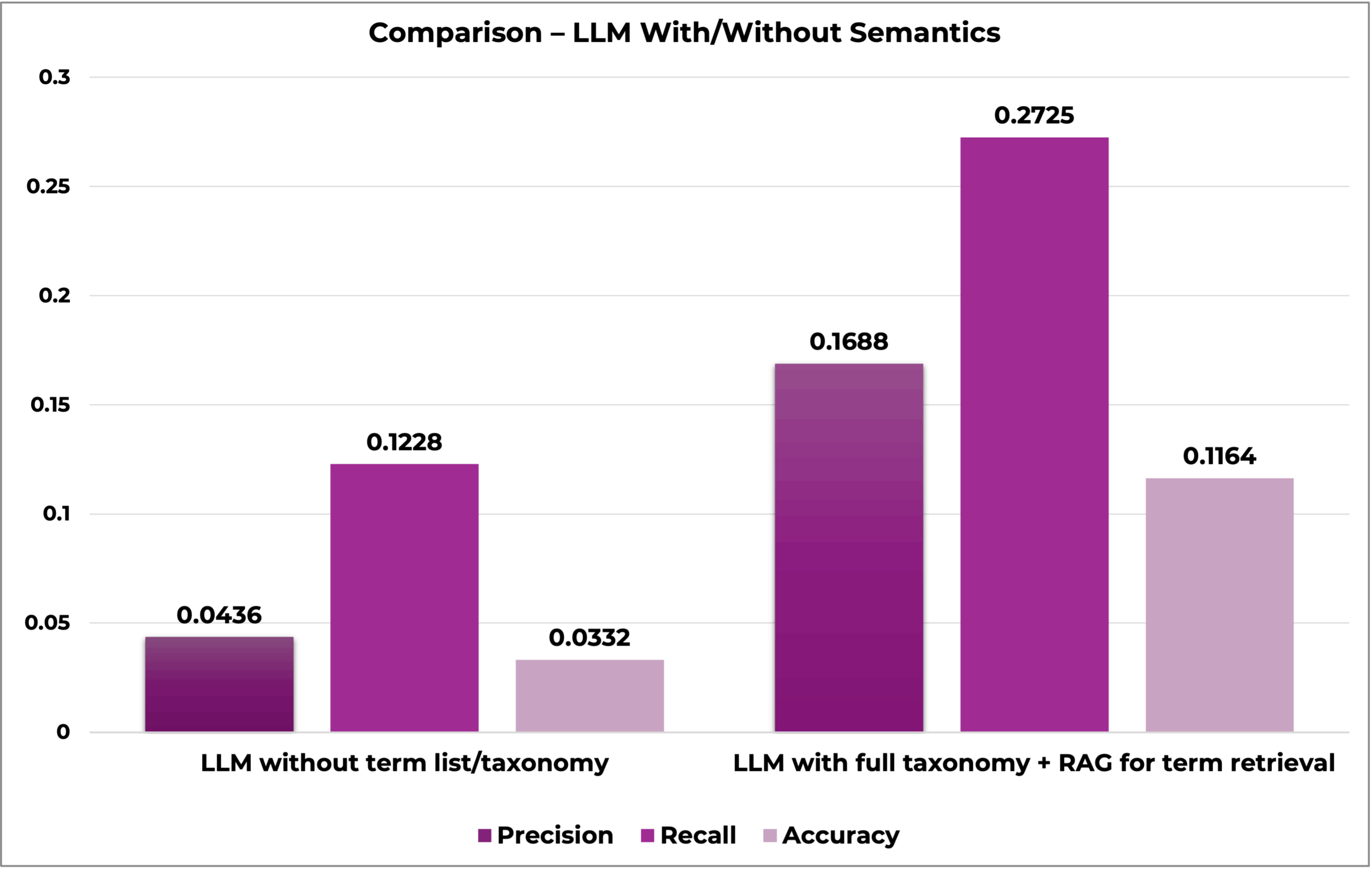
Overall, incorporating a taxonomy into LLM-based auto-classification transforms fragmented, messy one-off tags into consistent topic clusters and hierarchies that make content easier to browse, search, and discover.
This illustrates the utility of a taxonomy in auto-classification. When you give your employee a list of shelves to stock in the store, they can avoid the “overthinking” of semantic drift and place books onto more well-architected shelves (e.g., Young Adult, Sci-Fi). A well-defined taxonomy acts as the blueprint for organizing content meaningfully and consistently using an auto-tagger.
When Should I Use AI, Semantic Models, or Both?
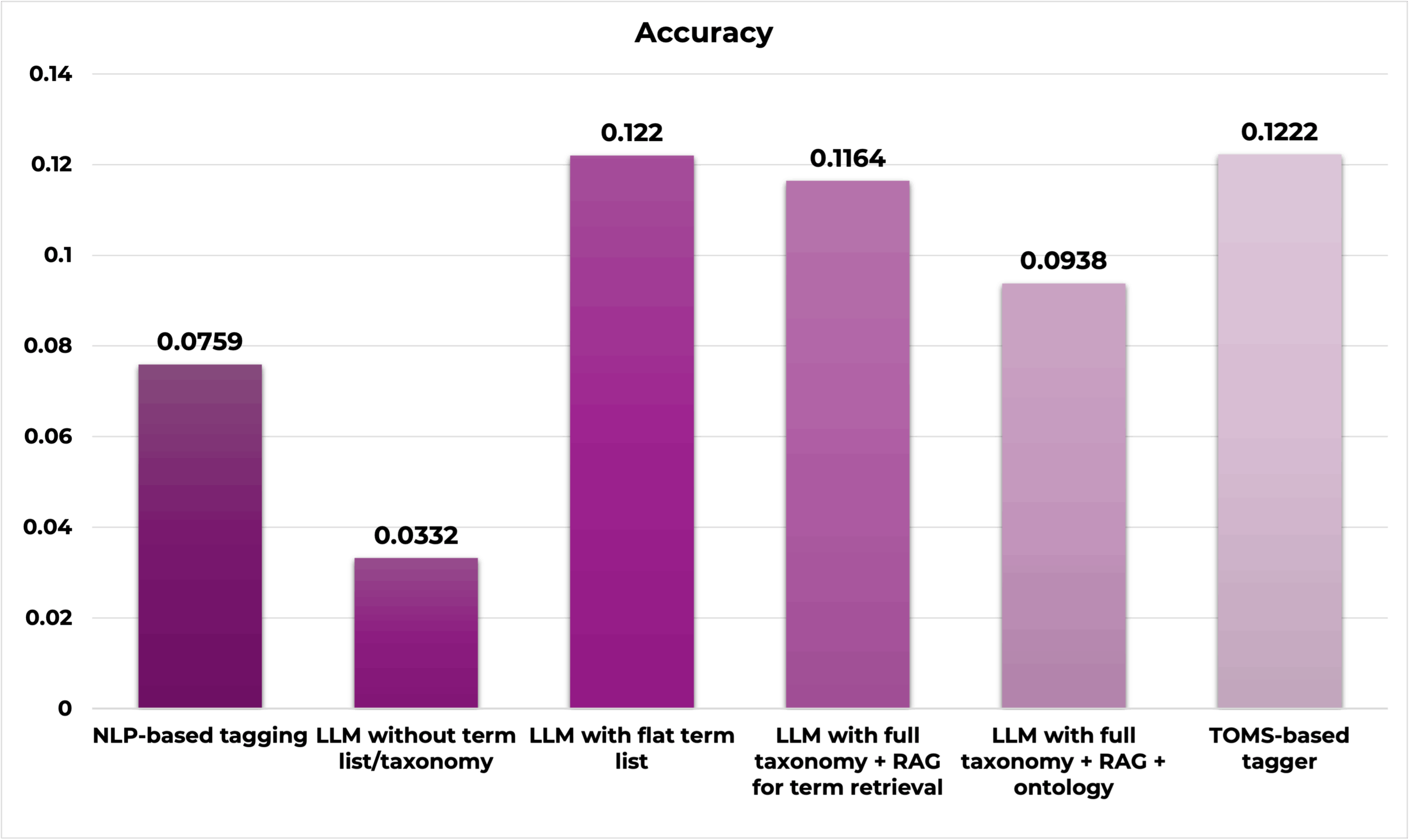
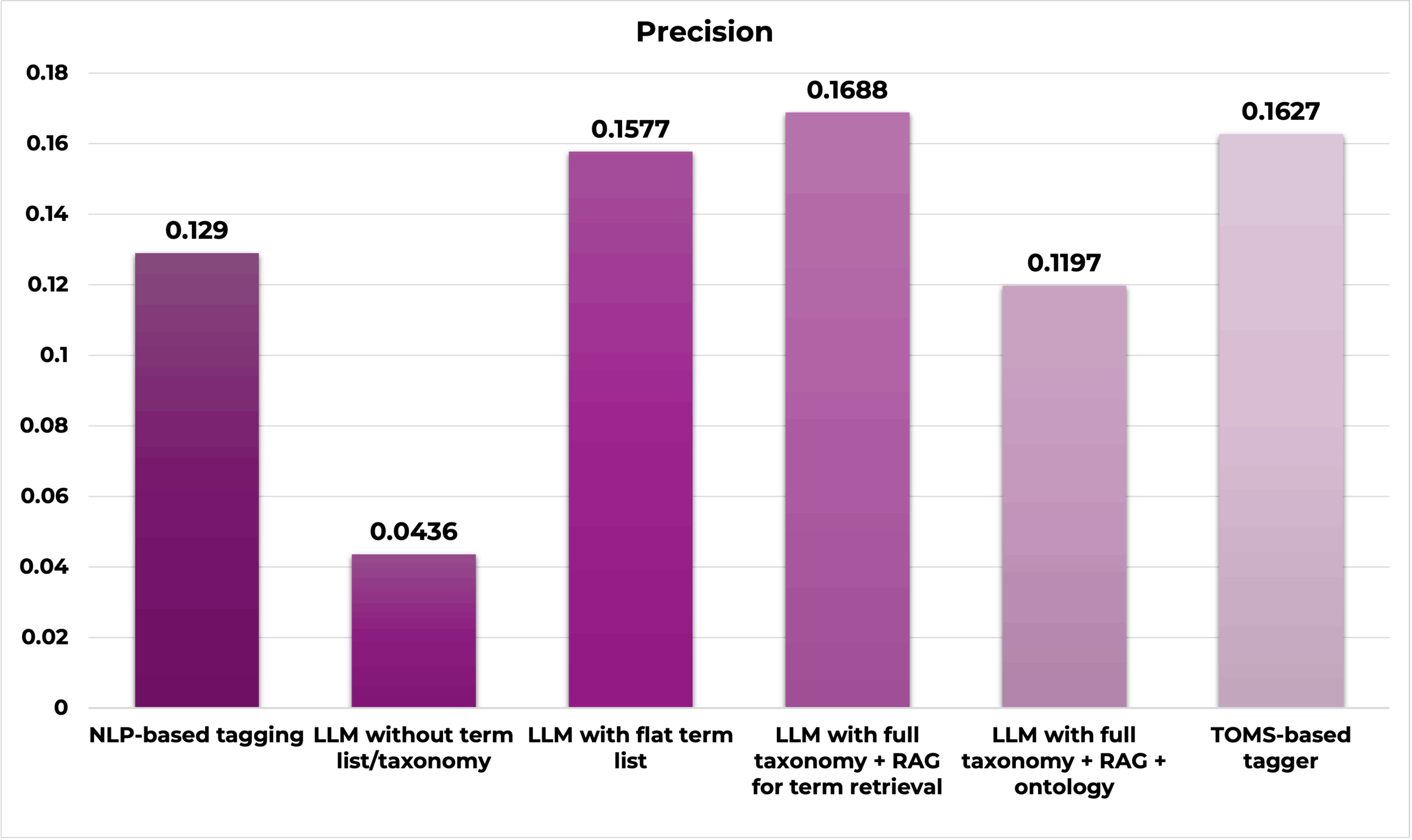
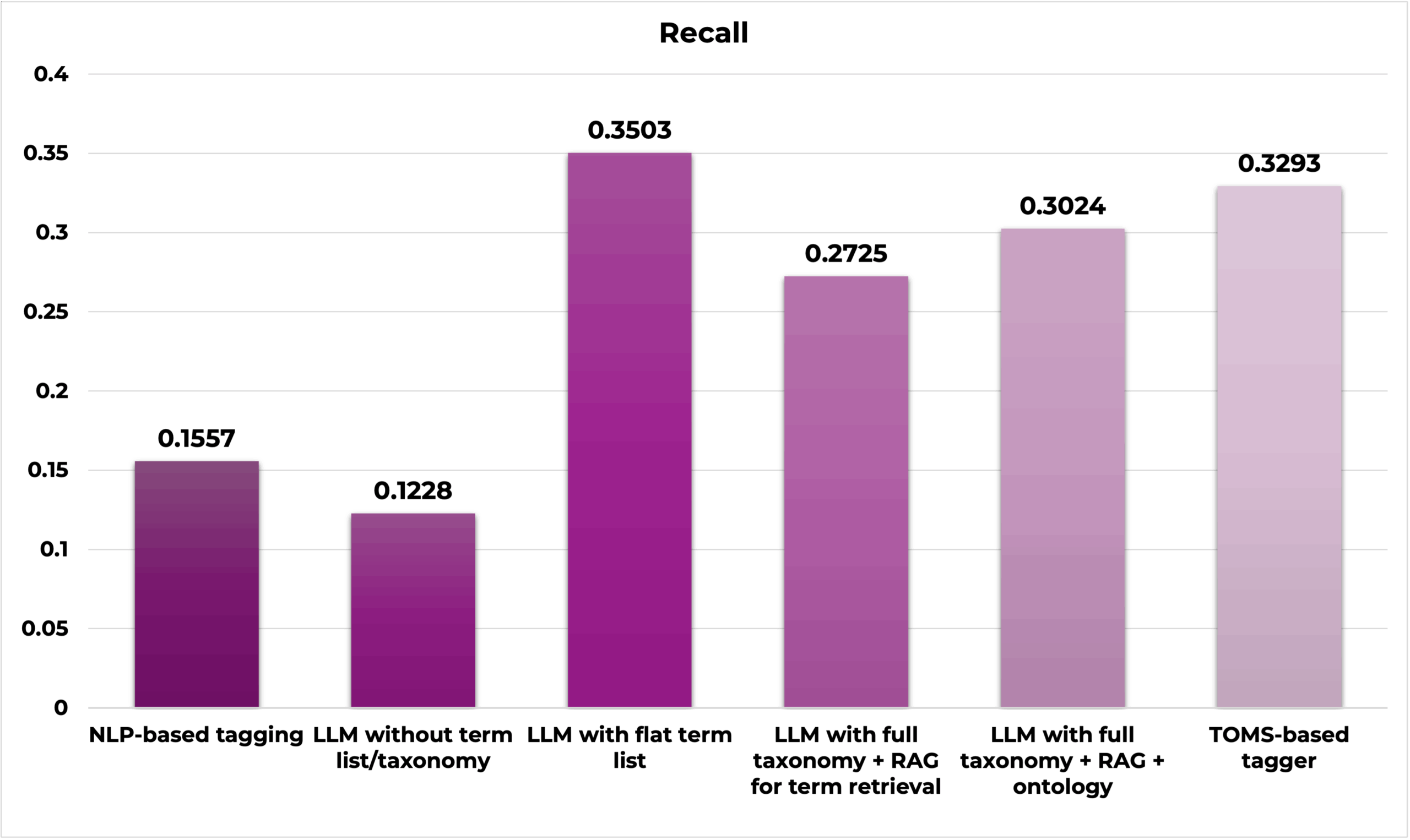
Methods including both AI and semantic models tend to score higher in accuracy, precision, and recall.
As demonstrated above, tags created by generative AI models without any semantic model in place can become unwieldy and excessive, as LLMs look to create the best tag for that individual content piece rather than a tag that can be used as an umbrella term for multiple pieces of content. However, that does not completely eliminate AI as a standalone solution for all tagging use cases. These auto-tagging models and processes can prove helpful in the early stages of creating a term list as a method of identifying common themes across content in a corpus and forming initial topic clusters that can later bring structure to a taxonomy, either in the form of hierarchies or facets. Once again, while not true auto-classification as the industry dictates, auto-tagging with AI alone can work well for domains where topics don’t neatly fit within a hierarchy or when domain models and knowledge evolve quickly and a hierarchical structure would be infeasible.
On the other hand, semantic models are a great way to add the aforementioned structure to an auto-classification process, and work very well for exact or near-exact term matching. When combined with a frequency tagging, NLP, or machine learning-based auto-classifier in these situations, they tend to excel in terms of precision, applying very few incorrect tags. Additionally, these methods perform well in situations where content contains domain-specific jargon or acronyms located within semantic models, as it tags with a greater emphasis on these exact matches.
Semantic models alone can prove to be a more cost-effective option for auto-classification as well, as lighter, less compute-heavy models that do not require paid cloud hosting can tag some content corpora with a high level of accuracy. Finally, semantic models can assist greatly in cases where security and compliance are paramount, as leading AI models are generally cloud-hosted, and most methods using semantics alone can be run on-premises without introducing privacy concerns.
Nonetheless, semantic models and AI can combine as part of auto-classification solutions that are more robust and well-equipped for complex use cases. LLMs can extract meaning from complex documents where topics may be implied and compare content against a taxonomy or term list, which helps ensure content is easy to organize and consistent with an organization’s model for knowledge. However, one key consideration with this method is taxonomy size – if a taxonomy grows too large (terms in the thousands, for example), an LLM may face difficulties finding/applying the right tag in a limited context window without mitigation strategies such as retrieving tags in batches.
In more advanced use cases, an LLM can also be paired with an ontology, which can help LLMs understand more about interrelationships between organizational topics, concepts, and terms, and apply tags to content more intelligently. For example, a knowledge base of clinical notes and guidelines could be paired with a medical ontology that maps symptoms to potential conditions, and conditions to recommended treatments. An LLM that understands this ontology could tag a physician’s notes with all three layers (symptoms, conditions, and treatments) so when a doctor searches for “persistent cough,” the system retrieves not just symptom references, but also likely diagnoses (e.g., bronchitis, asthma) and corresponding treatment protocols. This kind of ontology-guided tagging makes the knowledge base more searchable and user-friendly and helps surface actionable insights instead of isolated pieces of information.
In some cases, privacy or security concerns may dictate that AI cannot be used alongside a semantic model. In others, an organization may lack a semantic model and may only have the capacity to tag content with AI as a start. However, as a whole, the majority of use cases for auto-classification benefit from a well-architected solution that combines AI’s ability to intelligently parse content with the structure and specific context that semantic models provide.
Conclusion
Auto-classification adds an important step in automation to organizations looking to enrich their content with metadata – whether it be for findability, analytics, or understanding. While there are many methods to choose from when exploring an auto-classification solution, they all rely on semantics in the form of a well-designed taxonomy to function to the best of their ability. Once implemented and governed correctly, these automated solutions can serve as key ways to unblock human efforts and direct them away from tedious tagging processes, allowing your organization’s experts to get back to doing what matters most.
Looking to set up an auto-classification process within your organization? Want to learn more about auto-classification best practices? Contact us!