

In late November of 2022, artificial intelligence (AI) research and development company OpenAI released ChatGPT, an AI chatbot powered by a Large Language Model (LLM). In the following year, the world witnessed a meteoric rise in the usage of ChatGPT and other LLMs across a diverse array of industries and applications. However, what large language models actually are and what they are capable of is often misunderstood. In this blog, I will define LLMs, explore how they work, explain their strengths and weaknesses, and elaborate on a few of the most common LLM use cases for the enterprise.
So, what is a Large Language Model?
In short, a Large Language Model is an advanced AI model designed to perform Natural Language Processing (NLP) tasks, including interpreting, translating, predicting, and generating coherent, contextually relevant text. LLMs require extensive training on vast textual datasets that contain trillions of words, like Wikipedia and GitHub, which teaches the model to recognize patterns in text. An LLM such as OpenAI’s GPT-4 isn’t doing any “reasoning” like a human does, at least not yet – it is merely generating output that fits the patterns it has learned through training. It can simply be thought of as doing very sophisticated predictions of which words in which context go in what order.
How does a Large Language Model work?
All LLMs operate by leveraging immense, layered networks of interconnected nodes that process and transmit information. The structure of the networks draws inspiration from the interconnectedness of the human brain’s network of neurons. Within this framework, LLMs use so-called transformer models – consisting of an encoder and a decoder – to turn input into output.
In the process of handling a sequence of input text, a tokenizer algorithm first converts the text into a machine-readable format by breaking down the text into small, discrete units called “tokens” for analysis; tokens themselves are often single words or single letters.
For example, the sentence “Hello, world!” can be tokenized into [“Hello”, “,”, “world”, “!”].
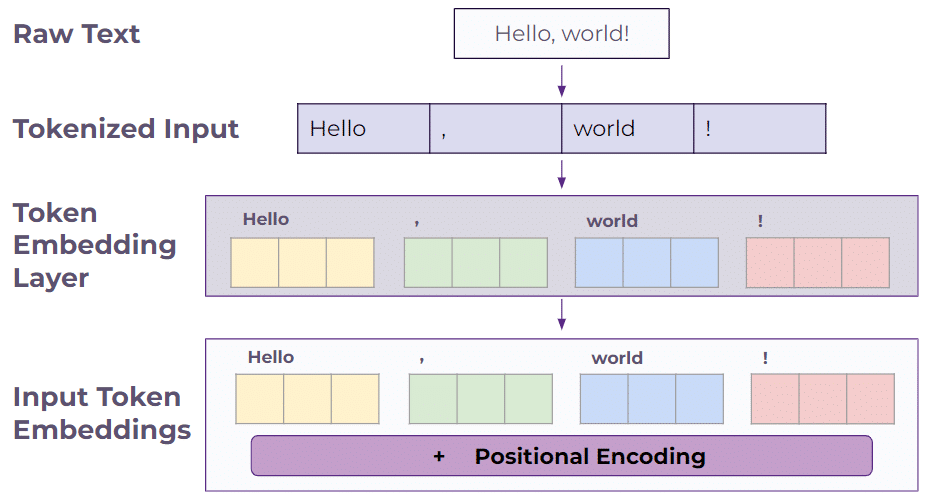
These tokens are then converted into numerical values known as embedding vectors, which is the format expected by the transformer model. However, because transformers can’t inherently understand the order of words, each embedding vector is combined with a positional encoding. This step ensures the order of the words is taken into account by the model.
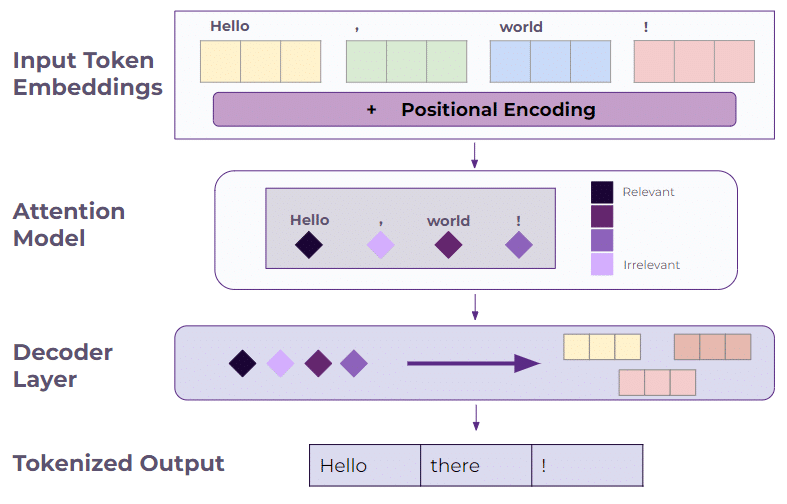
After the input text is tokenized, it is passed through the encoder to create attention vectors, which are numerical values that help the model determine the relevance and relationship of each token to the others in the input. This helps the LLM capture dependencies and relationships between tokens, giving it the ability to process the context of each token in the sequence.
The attention vectors are then passed to the decoder to receive an output embedding, which are then converted back into tokens. The decoder process continues until a “STOP” token is output by the transformer, indicating that no more output text should be generated. This process ensures that the generated output considers the relevant information from the input, maintaining coherence and context in the generated text. This is similar to how a human might receive a question, automatically identify the most important aspects of the question, and give an appropriate response that addresses those aspects.
Strengths
Large language models exhibit several strengths that businesses can capitalize on:
- LLMs excel in advanced tasks that require complex NLP like text summarization, content generation, and translation, all of which demonstrate their high level of proficiency in intricate linguistic tasks and creative text manipulation. This enables them to generate human-like output, carry on long conversations regarding almost any topic, recall details from previous messages in the same context, and even be given specific instructions on how they should respond and react to input.
- Similarly, large language models learn rapidly and adapt to the context of a conversation without the need for changing the underlying model architecture. This means they quickly grasp concepts without requiring an extensive number of examples. Supplied with enough detail by a user, LLMs can provide support to that user in solving particular or niche problems without ever having been specifically trained to tackle those kinds of problems.
- Beyond learning human languages, LLMs can also be trained to perform tasks like writing code, retrieving information, and classifying the sentiment of text, among others. Their adaptability extends to a wide array of use cases that can benefit the enterprise in numerous ways, including saving time, increasing efficiency, and enabling employees to work more effectively.
- Multimodal LLMs can both break down and generate a variety of media content, including images and videos, with natural language prompts. These models have been trained on existing media to understand their components and then use this understanding to create new content or answer questions about visual content. For example, the image at the top of this blog was generated using Dall-E 3 with the prompt “Please design an image representing a large language model, apt for a professional blog post about LLMs, using mostly purple hues”. This prompt was purposefully vague to allow Dall-E 3 to creatively interpret what an LLM could be represented as.
Weaknesses
In spite of their strengths, LLMs have numerous weaknesses:
- During training, LLMs will learn from whatever input they are given. This means that training on low quality input data will cause the LLM to generate low quality output content. Businesses need to be strict with the management of the data that the model is learning from to avoid the garbage in, garbage out problem. Similarly, businesses should avoid training LLMs on content generated by LLMs, which can lead to irreversible defects in the model and further reduce the quality of the generated output.
- During training, LLMs will ignore copyright, plagiarize written content, and ingest proprietary data if given access to that kind of content, which can raise concerns about potential copyright infringement issues.
- The training process and operation of an LLM demands substantial computational resources, which not only limits their applicability to high-power, high-tech environments but also imposes considerable financial burdens on businesses seeking to develop their own models. Building, scaling, and maintaining LLMs can therefore be extremely costly, resource-intensive, and requires expertise in deep learning and transformer models, which poses a significant hurdle.
- LLMs have a profound double-edged sword in their tendency to generate “hallucinations”. This means they sometimes produce outputs that are factually false or diverge from user intent, as they are only able to predict syntactically correct phrases without a comprehensive understanding of human meaning and truth. However, without hallucination, LLMs would not be able to creatively generate output, so businesses must weigh the cost of hallucinations against the creative potential of the LLM, and determine what level of risk they are willing to take.
LLM Use Cases for the Enterprise
Large language models have many applications that utilize their strengths. However, their weaknesses manifest across all use cases, so businesses must make considerations to prevent complications and mitigate risks. These are some of the most common use cases where we have employed LLMs:
Content generation:
- LLMs can generate human-like content for articles, blogs, and other written materials. As such, they can act as a starting point for businesses to create and publish content.
- LLMs can assist in generating code based on natural language descriptions, aiding developers in their work, and making programming more accessible for more business-oriented, non-technical people.
Information Retrieval:
- LLMs can improve search engine results by better understanding the linguistic meaning of user queries and generating more natural responses that pertain to what the user is actually searching for.
- LLMs can extract information from large training datasets or knowledge bases to answer queries in an efficient, conversational style, improving access and understanding of organizational information.
Text Analysis:
- LLMs can generate concise and coherent summaries of longer texts, making them valuable for businesses to quickly extract key information from articles, documents, or conversations.
- LLMs can analyze text data to determine the sentiment behind it, which is useful for businesses to gauge customer opinions, as well as for social media monitoring and market research.
- LLMs can be used to do customer and patient intakes, and to perform basic problem solving, in order to save employees time for dealing with more complicated issues.
Conclusion
In the past year, large language models have seen an explosion in adoption and innovation, and they aren’t going anywhere any time soon – ChatGPT alone reached 100 million active users in January 2023, and continues to see nearly 1.5 billion website visits per month. The enormous popularity of LLMs is supported by their obvious utility in interpreting, generating, and summarizing text, as well as their applications in a variety of technical and non-technical fields. However, LLMs come with downsides that cannot be brushed aside by any business seeking to use or create one. Due to their non-deterministic and emergent capabilities, businesses should prioritize working with experts in order to properly mitigate risks and capitalize on the strengths of a large language model.
Want to jumpstart your organization’s use of LLMs? Check out our Semantic LLM Accelerator and contact us at info@enterprise-knowledge.com for more information!