
Retrieval-Augmented Generation (RAG) is a commonly utilized pattern for grounding large language models in enterprise data. Instead of solely relying on a model’s training, RAG collects relevant information from internal sources, documents, knowledge bases, and other systems; it then uses that context to guide generation. This approach improves accuracy, allows models to work with proprietary or frequently changing data, and has made RAG a natural starting point for many enterprise AI initiatives.
However, as RAG is applied to more complex use cases, its limitations start to surface. Since it treats knowledge as flat chunks of text, it makes it difficult to convey relationships, maintain consistent context, or support multi-step and cross-document reasoning. GraphRAG addresses these gaps by incorporating graph-based structure into the retrieval process, where entities and their relationships are explicitly modeled. The result is a more context-aware retrieval methodology that sets the foundation for higher quality and more explainable responses at an enterprise level.
What is GraphRAG?
GraphRAG extends traditional RAG by grounding retrieval and reasoning in a knowledge graph built on semantic standards rather than relying solely on vector similarity over text. Instead of treating each retrieved chunk as an isolated unit, GraphRAG uses an explicit graph structure with entities, relationships, and shared vocabularies to represent how information is connected across documents and systems.
In practice, this means retrieval is driven not just by textual similarity, but by meaning and structure. Facts, entities, and relationships are anchored to a common ontology, allowing the system to understand how pieces of information relate to one another. This enables traceable reasoning paths, supports multi-step and cross-document questions, and produces answers that are more transparent and auditable—qualities that are essential in an enterprise environment.
How Does GraphRAG Differ from Naive RAG?
Naive RAG systems return information primarily based on textual or vector similarity (keyword or embedding similarity) and assemble the responses by presenting the most relevant chunks in parallel. This approach works well for straightforward lookups, but it often breaks down when the questions require precision, complex reasoning, or an understanding of how information is related. Because each chunk is treated independently, the model has limited awareness of relationships across documents, and it can be difficult to explain why specific pieces of information were retrieved or how an answer was formed.
GraphRAG changes this behavior by shifting retrieval from isolated text to structured context. Instead of asking “which passages are similar,” the system can ask “which entities, relationships, and facts are relevant, and how do they connect?” This supports more consistent handling of ambiguity, enables cross-document and multi-hop questions, and creates reasoning paths that can be traced back to explicit graph structures. In enterprise settings, this fosters higher precision, more interpretable answers, and results that adapt as knowledge evolves.
What Are the Components of GraphRAG?
A GraphRAG system is composed of several components that work together to introduce structure, context, and control into the retrieval and generation pipeline. Each component plays a specific role, ensuring that retrieved information is not only relevant but meaningfully connected before it is used by a language model.
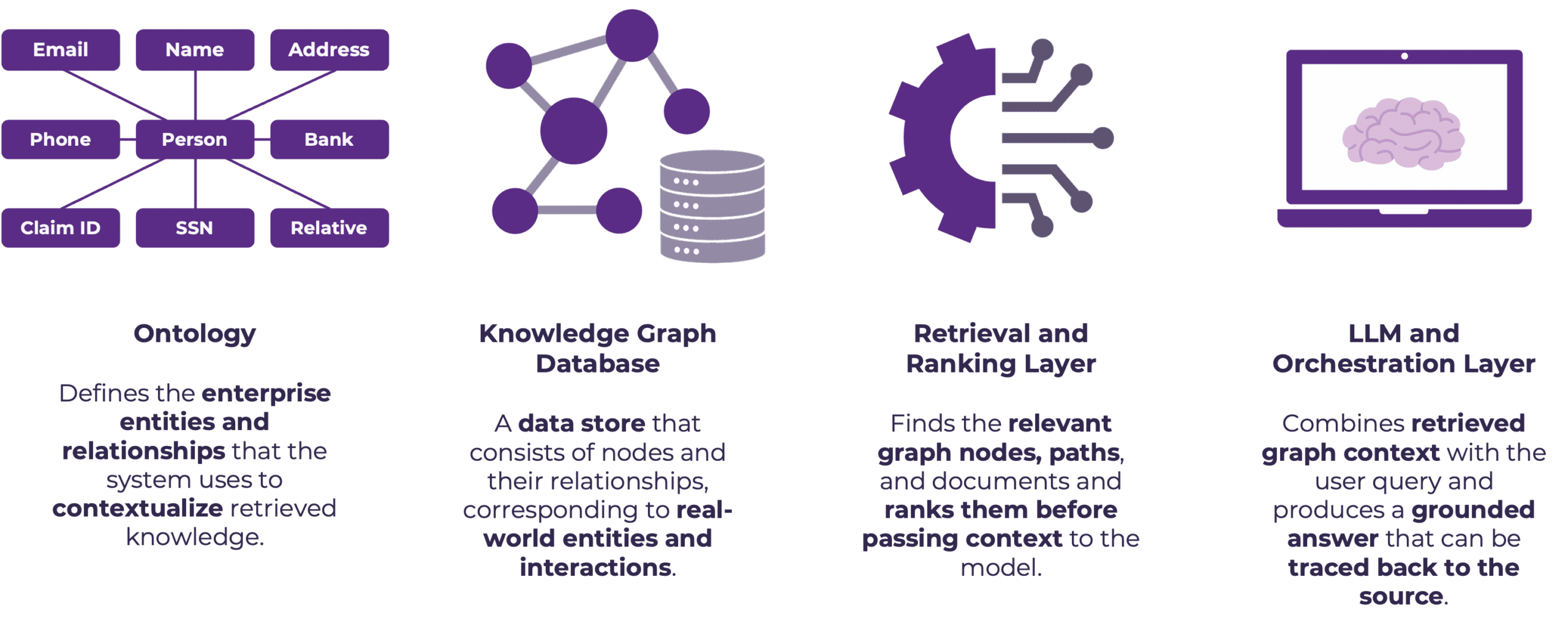
At a high level, GraphRAG combines an enterprise ontology to define shared meaning, a knowledge graph to store entities and relationships, a retrieval and ranking layer to identify the most relevant graph context, and an LLM and orchestration layer to synthesize grounded responses. Together, these components shift RAG from document-centric retrieval towards context-aware reasoning, while preserving traceability and alignment with enterprise knowledge models.
The Purpose of Each Component

- Ontology: Establishes a shared semantic foundation for the system by defining entities, relationships, and accepted meanings up front. This removes ambiguity and ensures that retrieval and reasoning align with enterprise definitions rather than surface-level text, allowing the system to interpret questions consistently, even when terminology varies across teams, documents, or data sources.
- Graph Database: Provides the structural backbone that stores entities and relationships explicitly, supporting traversal-based retrieval, where responses are built from established paths through the graph instead of probabilistic guesses. This makes it possible to understand how an answer was formed and to anchor reasoning in real-world entities and interactions.
- Retrieval and Ranking: Determines which parts of the graph matter most for a given question by identifying relevant nodes, relationships, and paths, and prioritizing them before passing context to the model. This enables multi-hop and cross-domain reasoning while controlling noise, ensuring the model receives a focused and context-aware view of the knowledge graph rather than an unstructured collection of facts.
- LLM and Orchestration: Assembles a final response from the curated graph context, combining retrieved relationships, supporting evidence, and provenance into a coherent answer that can be traced back to specific sources and graph paths. This turns structured context into natural language output while preserving explainability, making the system suitable for enterprise use cases where trust and accountability are required.
Success Stories
A global foundation engaged EK after multiple failed attempts to apply LLMs to strategic investment analysis. The organization needed to synthesize insights across public-domain data, internal investment documents, and proprietary datasets to evaluate how investments aligned with strategic objectives, all while ensuring their results were precise, explainable, and usable by executive stakeholders. EK implemented a GraphRAG-based solution anchored by a purpose-built finance ontology and a unified knowledge graph that integrated structured and unstructured data under a shared semantic model. By combining graph-based retrieval, provenance-aware context assembly, and an agentic RAG workflow, the system consistently outperformed naive LLM and traditional RAG approaches on complex, cross-document questions. The result was a transparent and auditable AI capability that delivered coherent and explainable insights. Stakeholders are now able to trace how each answer was derived, establishing a foundation for organization-wide adoption.
Likewise, an investment agency responsible for managing assets and supporting long-term, high-stakes decisions needed to provide its professionals with faster and more reliable access to relevant research and insights. The agency was building a Knowledge Portal but lacked the foundational semantic frameworks required to implement AI and graph driven insights at scale for the enterprise, while also operating across a complex data environment with misaligned metadata and disparate structured and unstructured sources. EK delivered a GraphRAG-aligned solution by applying semantic modeling and a graph database to unify data definitions and integrate research content into a single access point. The resulting capability ensured trustworthy and consistent results along with reduced operational silos, and improved search through enhanced natural language processing and auto-tagging. This established a scalable semantic knowledge ecosystem that enabled a second phase focused on graph-driven tagging and expanded knowledge graph capabilities.
Conclusion
GraphRAG represents an evolution of retrieval-augmented generation that aligns more naturally with how enterprises structure, govern, and reason over knowledge. By grounding retrieval and reasoning in explicit semantics and relationships, GraphRAG moves beyond keyword and vector similarity to deliver responses that are more precise, explainable, and contextually coherent. As organizations push AI systems into use cases with higher stakes that cross multiple domains, this graph-based foundation becomes critical for not only improving answer quality, but for building trust and transparency into scalable enterprise AI solutions.
To discuss how GraphRAG can support your organization’s next phase of AI adoption, contact us and connect with our team!