
The Topic Taxonomy: An Outdated Artifact?
As knowledge workers continue to navigate constantly evolving priorities in developing effective AI solutions that complement organizational priorities, semantics have maintained their value—but not without shifts that deserve our attention.
Broadly speaking, one reliable tenet holds true: taxonomies, as structured, hierarchical representations of a domain of content enriched with semantic context, provide a prime source of knowledge in a format that AI-powered solutions are built to digest. This hasn’t changed. That said, there are nuances around which taxonomies provide the most value. As semantic modelers with years of combined experience, we will focus on some essential taxonomies and how their value in the age of AI has shifted, with actionable recommendations on how to adapt your semantic modeling strategy accordingly.
We’ll start our exploration of different taxonomies and their value for AI solutions with the topic taxonomy. Topic taxonomies refer to the hierarchical classification systems that organize knowledge assets into topics and subtopics, describing the “aboutness” of the corpus they represent. They can be developed to represent any domain of knowledge, and provide coverage for any range of knowledge assets. While other taxonomies (product taxonomies, regional taxonomies, site navigation, etc.) warrant discussion, topic taxonomies in particular exemplify the overlap between most historically in-demand from our clients and most impacted by advancements in AI-powered solutions.
Experienced Enterprise Knowledge modelers report that, for over a decade, topic taxonomies were some of the most valuable, in-demand semantic models from organizations in a range of industries. Topic taxonomies played a vital role in supporting:
- Query expansion for improved search, particularly for highly-regulated and complex domains like healthcare and scientific research;
- Faceted search and filtering;
- Discovery and recommendation of relevant content within a domain; and
- Categories to wrangle unwieldy content.
However, with rapid advancements in Large Language Model (LLM) capabilities, the following question emerges: are topic taxonomies still relevant or valuable? To answer that, let’s first review how LLMs work.
LLMs vs. Taxonomies: An Updated Landscape
How LLMs Work
When a user submits a query to an AI-powered search or summarization tool, the system retrieves relevant content from the organization’s dataset and passes it to an LLM, which generates a natural-language summary drawing on both the retrieved content and the linguistic patterns it learned during training.
The quality of that summary depends on how well the retrieved content maps to the user’s intent and how unambiguous the underlying content is. We’ve observed that LLM-powered summaries have dramatically improved in quality and accuracy, even in the past year.
Keeping that in mind, let’s consider cases where an LLM produces reliable answers without taxonomy, and then we’ll explore the cases where taxonomy does make a significant difference.
Where LLMs Thrive Without Topic Taxonomies
While taxonomists may be reluctant to admit it, there are some instances where developing a topic taxonomy may not be the best way to dedicate modeling resources to a taxonomy project. This is not to say that taxonomies aren’t valuable; rather, these are areas where we suggest deprioritizing topic taxonomies in favor of developing different kinds of taxonomies.
Foundational Content
LLMs perform reasonably well with foundational content; content covering fundamental topics that would apply to most comparable organizations. Examples of such content include generic Human Resources topics (new hire onboarding, payroll, benefits information) or common customer support topics (setting up an account, changing a username, etc.). That said, foundational content does benefit heavily from taxonomies when representing a range of geographical regions where policies may differ—but we will get to that.
Structured Content
We know that LLMs perform better when digesting structured content; research consistently shows that content adhering to structured formats improves LLM retrieval and response quality. For example, a study on retrieval granularity found that breaking content into self-contained, structured units improved QA accuracy by 5–7 percentage points over arbitrarily segmented passages.
While “structured content” often implies “tagged with taxonomy,” it can also refer to content adhering to a content model, tabular data, code repositories, and more; essentially, any formal and consistent approach to transform content or data from an unstructured state to a structured format. Structuring content is particularly valuable for LLMs because it explicitly indicates where content can be broken into meaningful sections, as opposed to risking being chopped up into arbitrary pieces. This gives LLMs more information per token budget, which improves tool accuracy, efficiency, and effectiveness. The following visual illustrates how LLMs parse unstructured vs. structured content, and indicates how imposing structure improves the response.

Straightforward Content
Content written in plain, literal, and descriptive language tends to be adequately summarized by LLMs without taxonomic support. When the text says exactly what it means, the model has less room to misinterpret it. The retrieval system can match queries to content based on straightforward lexical and semantic similarity, and the summarization layer can synthesize it without confusion. This also applies to well-transcribed conversational content in transcripts.
Abundant Content
Many domains (software engineering, general medicine, consumer finance, and more) boast enormous representation in LLM training data, meaning that the model already has a strong baseline source for the terminology and concepts involved. As long as the content itself is well-written and doesn’t directly contradict most sources on the subjects therein, the AI agent can retrieve it, interpret it, and summarize it accurately without a taxonomy providing additional semantic guardrails.
For these kinds of content, developing a topic taxonomy may not deliver as much value, but there are other kinds of taxonomies that can provide far greater value and mitigate risk. Let’s dive in.
Where Taxonomies Serve As Differentiators
Despite advancements in the capabilities of LLMs, taxonomies continue to provide heightened value by providing semantic context and accuracy for the following areas:
Organization-Specific Terminology
Highly organization-specific terminology grounded in business function is one area where taxonomies continue to provide enhanced value, where relying on LLMs alone leaves users vulnerable to inaccurate, inadequately contextualized, insufficient responses. Taxonomies prioritizing unique, specific elements about an organization that would otherwise be incomplete or absent from generic training data are highly valuable for providing context that may otherwise be locked up in inaccessible formats, like tacit knowledge held by seasoned employees. Product taxonomies in particular exemplify where putting in the extra effort to capture your organization’s specific context is an effort that won’t go wasted, as opposed to letting an LLM parse together assumptions about products from product pages and internal documentation that often have multiple versions, overlapping information, or competing sources of truth.
Taxonomies for Disambiguation
Similar to taxonomies covering organization-specific terminology, areas where disambiguation is necessary to avoid overlapping meanings retain a high level of value for LLM-powered solutions. Here, allowing for some overlap between the value provided by both taxonomies and business glossaries, modeling a clarification between PTO (Paid Time Off) and PTO (Patent and Trademark Office) can provide a key distinction where knowledge assets may represent both concepts equally.
Think of using Google to research an acronym that sees broad as well as highly niche usage; letting LLMs loose on niche documentation without similarly niche contextualization may result in unsatisfactory outcomes. For example, imagine an engineer at a manufacturing firm asking an internal AI assistant, “What are our EPS requirements?” expecting information about Emergency Power Supply specs for their facility. Without disambiguation, the LLM (trained more on financial content than facilities engineering) might return a summary about Earnings Per Share targets from the company’s investor relations documents. The engineer wastes time, loses trust in the tool, and might miss a critical safety specification.
To explore another example of taxonomy’s utility for disambiguation, consider organizations where the same essential concept has both customer-facing and internal-facing terms: without explicit contextualization, an LLM would risk conflating the two, surfacing the wrong term to the wrong audience. For example, a bank’s customer may know a feature as “overdraft protection,” while internal teams track it under a regulatory label like “Reg E courtesy pay.”
Taxonomies for Risk Mitigation and Permission Management
Building upon the example of customer-facing vs. internal-facing terms, the realm of compliance and permissions highlights another area where investing time and resources in taxonomy development still holds great value – and should still be considered essential rather than optional. Developing a detailed taxonomy highlighting audiences or permissions provides LLMs with structured, contextualized guidelines, particularly when taxonomy concepts are applied as tags to the knowledge assets that need to be accessible by certain audiences and not others.
Taxonomies for Assigning Value
Tangential to the audience and permission management use case, taxonomies can also be valuable for assigning greater weight to knowledge assets that should be treated as a source of truth or higher priority than other assets. Suppose your team works with massive amounts of technical documentation that must all be maintained for document retention reasons, and can’t be reduced in a content audit. In this case, taxonomy would be useful for highlighting content that should be prioritized when retrieving information on a certain topic. Here, LLMs and taxonomies can join forces: the taxonomy can be leveraged to identify content that the LLM should assign greater importance to and weigh more heavily than other content, and the LLM can surface a more valuable response to the end user.
Taxonomies Representing Geographic Variation
Even as LLMs demonstrate an impressive ability to effectively summarize large quantities of content, we’ve found they still fall short when parsing between content written for different geographic regions. Recently, EK worked with a client that needed to audit and classify a corpus of content representing location-specific policies at a multinational organization with offices in dozens of different countries, each with differing legal policies. Their current-state LLM-powered summarization tool would conflate leave policies and other compliance-impacted topics across geographical regions. Fortunately, imposing a taxonomy representing geographic variation on a document level mitigated this problem.
Taxonomies as a Foundation for Ontologies and Knowledge Graphs
Last but not least, taxonomies provide tremendous value in the form of providing scaffolding for more advanced models, namely ontologies and knowledge graphs. By first establishing a semantic, hierarchical foundation of fundamental concepts and context, ontologies can then be built to model non-hierarchical relationships, which can then be instantiated in a knowledge graph.
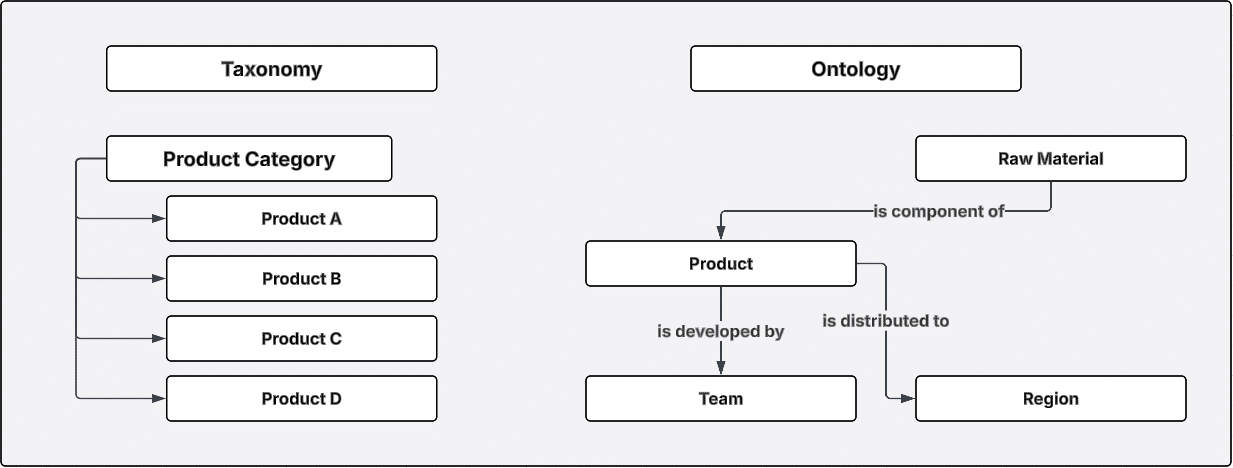
Modeling more complex relationships unlocks value for organizations that need to understand the interplay between distinct entities. As shown in the visual above, taxonomies can model types of products, but an ontology can model more complex relationships between entities; the raw materials needing to be purchased to build the products developed by certain teams, and then the markets they should be distributed to. Complex competency questions require more complex modeling, but require taxonomies as a foundation.
In all of the aforementioned instances, taxonomies provide the additional semantic context that LLMs need to provide reliable responses that reflect organizational specificity, respect compliance considerations, direct attention to prioritized content, disambiguate where needed, and account for geographic variation and other forms of customization to suit user needs.
Taxonomies in the Age of AI: Rethinking Your Taxonomy Strategy
If you’ve grown accustomed to thinking that topic taxonomies should be at the forefront of your semantic modeling strategy, it may be time to think differently to adapt to changes in how taxonomies are consumed and the value they provide LLM-powered tools.
If you’re ready to update your taxonomy strategy to optimize LLM outcomes and get the most out of your semantic design efforts, reach out to us. Our team of semantic modeling experts is ready to discuss your options and develop a solution that fits your goals and keeps up with ongoing evolutions in AI capabilities.