
Kjerish, CC BY-SA 4.0, via Wikimedia Commons
Data proliferates. Whether you are a small team or a multinational enterprise, information grows at an accelerated rate over time. As that data proliferates, you can run into issues of interoperability, duplication, and inconsistency that slows down the speed with which actionable insights can be derived. In order to mitigate this natural tendency, we develop and enforce standardized data models.
Developing enterprise data models introduces new concerns, such as how centralized ownership of the model should be. While it can be helpful to have a singular overarching data model team, centralization can also introduce its own challenges. Chief among these is the introduction of a modeling bottleneck. If only one team can produce or approve models, that slows down the speed with which models can be developed and improved. Even if that team is incorporating feedback and review from the data experts, centralization is typically a blocker to ensuring that deep domain knowledge is captured and kept updated. It is for that reason that frameworks such as data mesh and data fabric promote domain ownership of data models by the people closest to the data within a larger federated framework.
Before continuing, we should define a few terms:

Of course, implementing domains working within a federated data model brings its own challenges for data governance. Some–such as the need for global standardization to promote interoperability across data products–are common data challenges, while others–such as the federation of governance responsibilities–may be new to organizations embarking on a decentralized model journey. This article will walk through how to begin transitioning to federated data model governance.

Similar to a town hall or local government, success will rely on ensuring that many different stakeholders have a seat at the table and a sense of shared responsibility. Dietmar Rabich / Wikimedia Commons / “Dülmen, Rathaus, Ratssaal — 2017 — 9667-73” / CC BY-SA 4.0
M oving away from a centralized model: Balancing standardization and autonomy
oving away from a centralized model: Balancing standardization and autonomy

For organizations that have already implemented centralized data governance, the thought that governance responsibilities can or should be federated out to different domains may seem strange. Data governance grows out of the need for standardization, interoperability, and regulatory standards, all of which are typically associated with centralized management. These needs are central to any large organization’s data governance, and they don’t go away when creating a federated governance model. However, within a federated data model, these standardization needs are balanced against the principles of domain autonomy that support data innovation and agile production. Time spent explaining field naming conventions and data structure to non-experts and waiting for approval can slow or even stymie the ability to make data internally available, resulting in increased cost, lost hours, and lower innovation.
To support domain autonomy and the ability to move quickly when iterating on or creating new data products, some of the responsibility for ensuring that data meets governance standards is shifted onto the domains as part of a shared governance model. Business-wide governance concerns like security and enterprise authorization remain with central teams, while specific governance implementations like authorization rules and data quality assurance are handled on a domain basis. Domains handle the domain-level governance checks and leave the centralized governance group to tackle more central issues like regulatory compliance, meaning that the data product teams spend less time waiting on centralized governance checks when iterating on a data product.
The federated and central governance teams are not separate entities, working without knowledge of one another. Domain teams are able to weigh in on and guide global data product governance policies, through a cross-functional governance team.
 Global governance, local implementation
Global governance, local implementation
Within a federated governance model, it is still important to be able to create enterprise-wide governance policies. Individual domains need guidance on meeting regulatory requirements in areas of privacy and security, among others. Additionally, for standardization to be of the greatest benefit, all of the groups producing data need to align on the same standards.
It is for these reasons that the federated governance model relies on a cross-functional governance team for policy decisions, as well as guidance on how to implement governance to meet those policies. This cross-functional team should be made up of domain representatives and representatives from Central IT, Compliance, Standards, and other experts in relevant governance areas. This ensures that policy decisions are not removed from the data producers, and that domains have a say in governance decisions while remaining connected to your organization’s central governance bodies. Policies that should be determined by this governance team can include PII requirements, API contracts, mappings, security policies, representation requirements, and more.
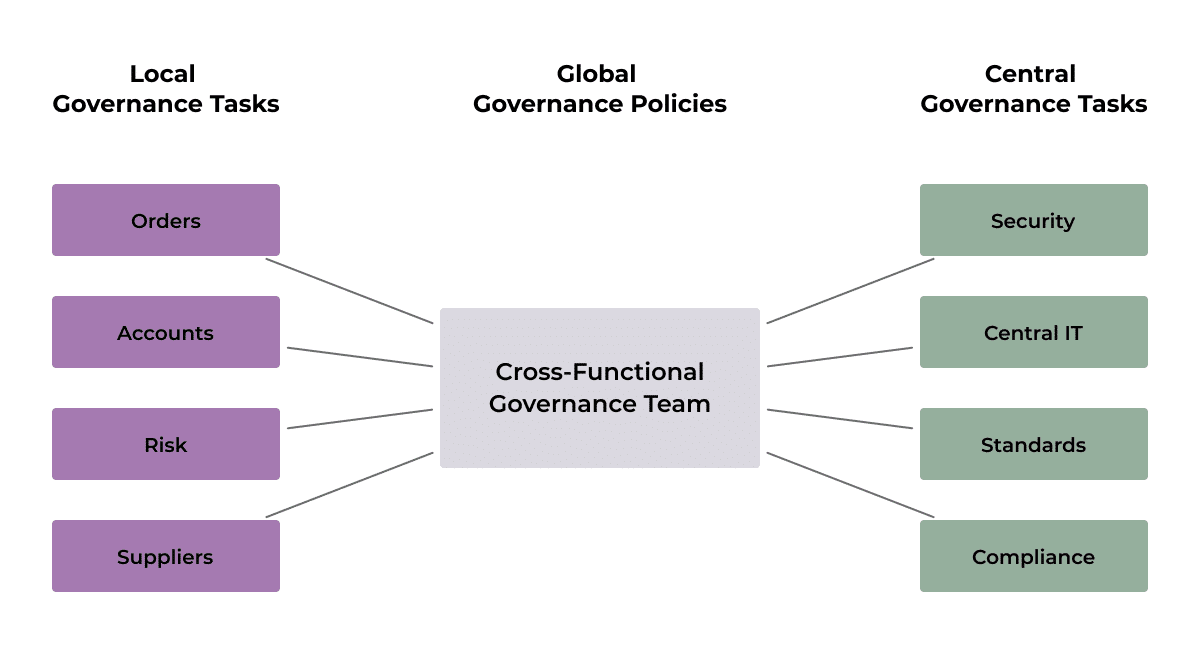
An example federated governance diagram
In order to ensure that domains are fully engaged in the governance process, it is best practice to involve the data product teams early in the governance process. For an organization new to federated data models, this should happen when the data product teams are being stood up, rather than waiting for product teams to be fully formed before grafting on later. When Enterprise Knowledge spearheaded the development of an enterprise ontology for data fabric at a major multinational bank, we worked with the major stakeholders to start defining a federated governance program and initial domains from the beginning of the engagement alongside the initial ontology modeling. This helped to ensure that there was early buy-in from the teams that would later define and be responsible for data products.
The data product teams are ultimately responsible for executing the governance policies of this group, so it is vital that they are involved in defining those policies. Lack of involvement can lead to friction between the governance and data product teams, especially if the data product teams feel that the policies are out of sync with their governance needs.
 Shift left on standards
Shift left on standards
The idea of “shifting left” comes from software testing, where it means to evaluate early rather than later in project lifecycles. Similarly, shifting left on standards looks to incorporate data management practices early into data lifecycles, rather than trying to tack them on at the end. Data management frameworks prioritize working with data close to its source, and data governance should be no different. Standards need to be embedded as early within the data lifecycle as possible in order to promote greater usability downstream within data products.
For data attributes, this could mean mapping data to standardized concept definitions and business rules as defined in an ontology. EK has worked with clients to shift left on standardization by using a semantic layer to connect standardized vocabulary to source data across disparate datasets, and map the data to a shared logical model. Applying standardization within the data products improves the user experience for data consumers and lessens the time lost when working with multiple data products.
Zhamak Dehghani, the creator of the data mesh framework, suggests looking for places where standardization and governance can be applied programmatically as part of what she refers to as “computational governance.” Depending on an organization’s technical maturity (i.e. the availability and use of technical solutions internally), governance tasks such as the anonymization of PII, access controls, retention schedules, and more can be coded as a part of the data products. This is another instance of embedding standardization within domains to promote data quality and ease of use. Early standardization lessens the amount of later coordination that is required to publish data products, resulting in faster production, and it is one of the keys to enabling a federated data model.
Conclusion
While federated data governance will be a new paradigm to many organizations, it has clear advantages for data environments that rely on expertise across different subject areas. The best practices discussed in this article will ensure that your organization’s data ecosystem is not only a powerful tool for standardization and insights, but also a robust and reliable one. Data product thinking can be an exciting new way to gain insights from your data, but the change in paradigm required can also leave new users feeling lost and unsure. If you want to learn more about the social and technical sides of setting up federated data governance, contact us and we can discuss your organization’s needs in detail.