
 Despite a variety of powerful technical solutions designed to centrally manage enterprise data, organizations are still running into the same stubborn data issues. Bottlenecks in data registration, lack of ownership, inflexible models, out of date schemas and streams, and quality issues have continued to plague centralized data initiatives like data warehouses and data lakes. To combat the organizational and technical problems that give rise to these issues, businesses are turning to the data mesh framework as an alternative.
Despite a variety of powerful technical solutions designed to centrally manage enterprise data, organizations are still running into the same stubborn data issues. Bottlenecks in data registration, lack of ownership, inflexible models, out of date schemas and streams, and quality issues have continued to plague centralized data initiatives like data warehouses and data lakes. To combat the organizational and technical problems that give rise to these issues, businesses are turning to the data mesh framework as an alternative.
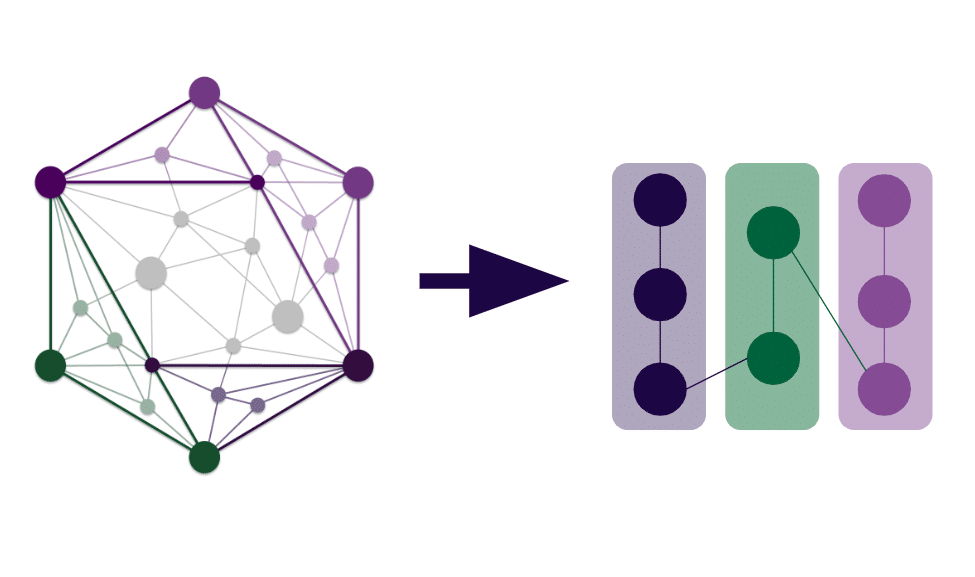
Data mesh focuses on decentralizing data, moving from the data lake paradigm to a network of data products owned and produced by specific business domains. Within the data mesh, data is treated like a product: it has specific business units that own the production of data as a product and work to meet the needs of the enterprise data consumers. Domain ownership and data product thinking, both of which promote autonomy, are balanced through a self-serve data platform and a federated governance model that ensure data products meet standardization and quality needs, and are easy for domains to produce and register. The name “data mesh” comes from the graph nature of this decentralized model: the data products serve as points, or nodes, which are linked together to power deeper data insights.
The shift from centralized data management to decentralized data management can be a stark change in mindset, and organizations can struggle to know where to begin. Translating the four principles of the data mesh framework–data as product, domain ownership of data, self-service data platform, and federated computational governance–to technical and organizational requirements requires a new perspective on data and semantics. It requires a graph perspective, similar to a knowledge graph. At Enterprise Knowledge, we help clients to model their data using knowledge graphs, and we’ve demonstrated how a knowledge graph can be instrumental to jump-starting an organization’s data mesh transformation. As this article will walk through, knowledge graphs are an intuitive and powerful method for accelerating a mesh initiative.
How can knowledge graphs accelerate data mesh?
A knowledge graph is a graph-based representation of a knowledge domain. The term was first introduced by Google as a means to connect searches to the concepts like a person or organization searched for rather than the exact strings used. A knowledge graph models the human understanding of concepts and processes as entities, with relationships between them showing the context and dependencies of each entity. Data is then mapped to the graph as “instances” of entities and relationships. This encodes the human understanding of a knowledge domain such that it can be understood and reasoned over by machines. Knowledge graphs are a powerful tool for mapping different data sources to a shared understanding, and can power enterprise search, content recommenders, enterprise AI applications, and more.
Both knowledge graphs and data mesh take different sources of information and represent them as nodes on a graph with links between them in order to power advanced insights and applications. Unlike data mesh, knowledge graphs are often more centrally managed (one example being a knowledge graph powering a semantic layer) and focus on representing attributes rather than products at the node level, but both approaches take a domain approach to modeling business understanding and capturing the meaning or semantics underlying the data.
In her book Data Mesh: Delivering Data-Driven Value at Scale, Zhamak Dehghani, the creator of the data mesh framework, even describes data products within a data mesh as constituting an “emergent knowledge graph” (pp. 8, 199). The deep similarities between data mesh and knowledge graphs lead to a natural synergy between the two approaches. Having a knowledge graph is like having superpowers when it comes to tackling a data mesh transformation.
Superpower #1: The knowledge graph provides a place and framework for data product modeling
![]() One of the first stumbling blocks for organizations embarking on a data mesh initiative is understanding how to model for data products within a domain. For the purpose of this article, we will assume that starter domains and data products have already been identified within an organization. One of the first questions people ask is how they can model data products without creating silos.
One of the first stumbling blocks for organizations embarking on a data mesh initiative is understanding how to model for data products within a domain. For the purpose of this article, we will assume that starter domains and data products have already been identified within an organization. One of the first questions people ask is how they can model data products without creating silos.
Having a self-service data platform provides a common registration model, but it doesn’t enforce interoperability between data products. To be able to link between data products without wasting time creating cross-mappings, it is necessary to align on common representations of shared data, which Zhamak Dehghani refers to as “polysemes.” Polysemes are concepts that are shared across data products in different domains, like customer or account. Taking “account” as our example of a shared concept, we will want to be able to link information related to accounts in different data products. To do these, the products we are linking across will need to align on a method of identifying an account, as well as a common conceptual understanding of what an account is. This is where a knowledge graph comes in, as a flexible framework for modeling domain knowledge.
Using an RDF knowledge graph, we can model account as well as its associated identifier and the relationship between them. Preferably, account and other polysemes will be modeled by the domain(s) closest to them, with input from other relevant data product domains. If we then model other data products within our knowledge graph, those data products will be able to link to and reuse the account polyseme knowing that the minimum modeling required to link across account has been achieved. The knowledge graph, unlike traditional data models, provides the flexibility for the federated governance group to begin aligning on the concepts and relationships common to multiple domains, and to reuse existing concepts when modeling data products.
Note: There are multiple ways of creating or enforcing a data product schema from a knowledge graph once modeled. SHACL is one language for describing and validating a particular data shape in a knowledge graph, as is the less common ShEx. SPARQL, GraphQL, and Cypher are all query languages that can be used to retrieve semantic information to construct schemas.
Superpower #2: Use the knowledge graph to power your self-service data mesh platform
![]() The data mesh self-service platform is the infrastructure that enables the data products. It should provide a common method for data product registration that can be completed by generalist data practitioners rather than specialists, and a place for data consumers to find and make use of the data products that are available. In order to fulfill the data mesh infrastructure needs, a data mesh platform needs to: support data product discovery, provide unique identifiers for data products, resolve entities, and enable linking between different data products. To show how a knowledge graph can help a data mesh platform to meet these structural requirements, I will walk through each of them in turn.
The data mesh self-service platform is the infrastructure that enables the data products. It should provide a common method for data product registration that can be completed by generalist data practitioners rather than specialists, and a place for data consumers to find and make use of the data products that are available. In order to fulfill the data mesh infrastructure needs, a data mesh platform needs to: support data product discovery, provide unique identifiers for data products, resolve entities, and enable linking between different data products. To show how a knowledge graph can help a data mesh platform to meet these structural requirements, I will walk through each of them in turn.
Discover Data Products
 For data products to transform an organization, they need to be easily found by the data consumers who can best make use of the analytical data. This includes both analysts as well as other data product teams who can reuse existing products. Take a financial services company’s credit risk domain, for example. Within this domain you can have data products that serve attributes and scores from each of the three big credit bureaus, as well as aggregate products that combine these credit bureau data products with internally tracked metrics. These products can be used by a wide variety of the business’s applications: reviewing potential loan and credit card customers, extending further credit to existing customers, identifying potential new customers for credit products, analyzing how risk changes and develops over time, etc.
For data products to transform an organization, they need to be easily found by the data consumers who can best make use of the analytical data. This includes both analysts as well as other data product teams who can reuse existing products. Take a financial services company’s credit risk domain, for example. Within this domain you can have data products that serve attributes and scores from each of the three big credit bureaus, as well as aggregate products that combine these credit bureau data products with internally tracked metrics. These products can be used by a wide variety of the business’s applications: reviewing potential loan and credit card customers, extending further credit to existing customers, identifying potential new customers for credit products, analyzing how risk changes and develops over time, etc.
A knowledge graph supports this reuse and findability by defining the metadata that describes the data products. Associated taxonomies can also help to tag use cases and subject areas for search, and existing knowledge graph connections between data products can surface similar datasets as recommendations when consumers browse the mesh.
Assign Unique Identifiers
Th e core of the data product node within a mesh is its Uniform Resource Identifier, or URI. This identifier is connected to a data product’s discovery metadata and its semantic information: relationships to other data products, schema, documentation, data sensitivity, and more. Knowledge graphs are built on a system of URIs that uniquely identify the nodes and relationships with the graph. These URIs can be reused by the data mesh to identify and link data products without having to create and manage a second set of identifiers.
e core of the data product node within a mesh is its Uniform Resource Identifier, or URI. This identifier is connected to a data product’s discovery metadata and its semantic information: relationships to other data products, schema, documentation, data sensitivity, and more. Knowledge graphs are built on a system of URIs that uniquely identify the nodes and relationships with the graph. These URIs can be reused by the data mesh to identify and link data products without having to create and manage a second set of identifiers.
Resolve Entities
 Entity resolution is the process of identifying and linking data records that refer to the same entity, such as a customer, business, or product. The node-property relationship structure of knowledge graphs is well suited to entity resolution problems, since it categorizes types of entities and the relationships between them. This in turn powers machine learning entity resolution to disambiguate entities. Disambiguated entities can then be linked to a single identifier. Resolving entities surfaces linkages across data products that would not otherwise be identified, generating new insights into data that was previously isolated.
Entity resolution is the process of identifying and linking data records that refer to the same entity, such as a customer, business, or product. The node-property relationship structure of knowledge graphs is well suited to entity resolution problems, since it categorizes types of entities and the relationships between them. This in turn powers machine learning entity resolution to disambiguate entities. Disambiguated entities can then be linked to a single identifier. Resolving entities surfaces linkages across data products that would not otherwise be identified, generating new insights into data that was previously isolated.
Link Products Together
A data mesh is not a data mesh unless there are linkages across the data products to form new data products and power new analytics. Without those linkages, it is only a set of disconnected silos that fail to address institutional data challenges. Linkages that exist between data products in the knowledge graph will be surfaced by a data mesh platform, such as a data catalog, to provide further context and information to users. New linkages can be easily defined and codified using the knowledge graph system of nodes and properties that underlie that data mesh platform.
data mesh is not a data mesh unless there are linkages across the data products to form new data products and power new analytics. Without those linkages, it is only a set of disconnected silos that fail to address institutional data challenges. Linkages that exist between data products in the knowledge graph will be surfaced by a data mesh platform, such as a data catalog, to provide further context and information to users. New linkages can be easily defined and codified using the knowledge graph system of nodes and properties that underlie that data mesh platform.
Conclusion
Data thrives on connections. The ability to create insights across an enterprise can’t come from one stream or relational table alone. Insights rely on being able to place data within an entire constellation of different sources and different domains, so that you can understand the data’s context and dependencies across a sea of information. Both data mesh and knowledge graphs understand this, and work to define that necessary context and the relationships while simultaneously providing opportunities to enhance the quality of the information sources. These graph based representations of data are not an either-or that businesses need to choose between; instead, they complement each other when used together as a framework for data. If you are interested in learning more about beginning or accelerating a data mesh transformation with a knowledge graph, reach out to us to learn how we can drive your data transformation together.