
When we start most of our engagements with our clients, there are common and important challenges we’re typically presented with that help summarize the core needs that persist within the data management space today:
- We don’t know what data we have and/or who owns it;
- We have not been successful at reaping the benefits of our data, even after we migrate it to a central location (for example, into a data lake or warehouse);
- We don’t have a quick way of knowing how many of our projects use or need similar data;
- We are not sure of the number of data-centric or Artificial Intelligence (AI) initiatives that are taking place within our organization; and
- We don’t have the right solutions or skill sets to support enterprise AI or advanced data engineering efforts.
These are fundamental challenges that have been confronting organizations for some time. Organizations need new approaches and solutions to avoid failure and achieve the results and benefits that they have been looking for.
The good news is that the data and AI industry has made tremendous leaps in the past decades – especially supported by higher computing power, semantic solutions, and cloud technologies. As a result, the focus is now shifting to achieving economies of scale and alignment across the multiple data initiatives and needs that are quickly spinning up within pockets of the enterprise. The data trends we are seeing today exhibit this direction and center around approaches that enable reusability of data that is created for data-centric efforts, repeatability or delivery processes, and building the capacity to scale beyond a proof of concept or a business unit.

Based on these experiences and what I see on our projects, there are three concepts that are trending in the data and enterprise AI community that leading organizations should be aware of.
Data Fabric
A data fabric is a logical data architecture that serves as a data connection and knowledge layer. A data fabric enables data federation and virtualization of semantic labels or rules (e.g. taxonomies/business glossaries or ontologies) to capture and connect data based on business or domain meaning and value. A knowledge graph is a key component of a data fabric that serves as the data orchestration or discovery layer. The ultimate objective of this design concept is to aggregate and unify unstructured and structured data to connect data of all formats that is available for both humans and machines to understand.
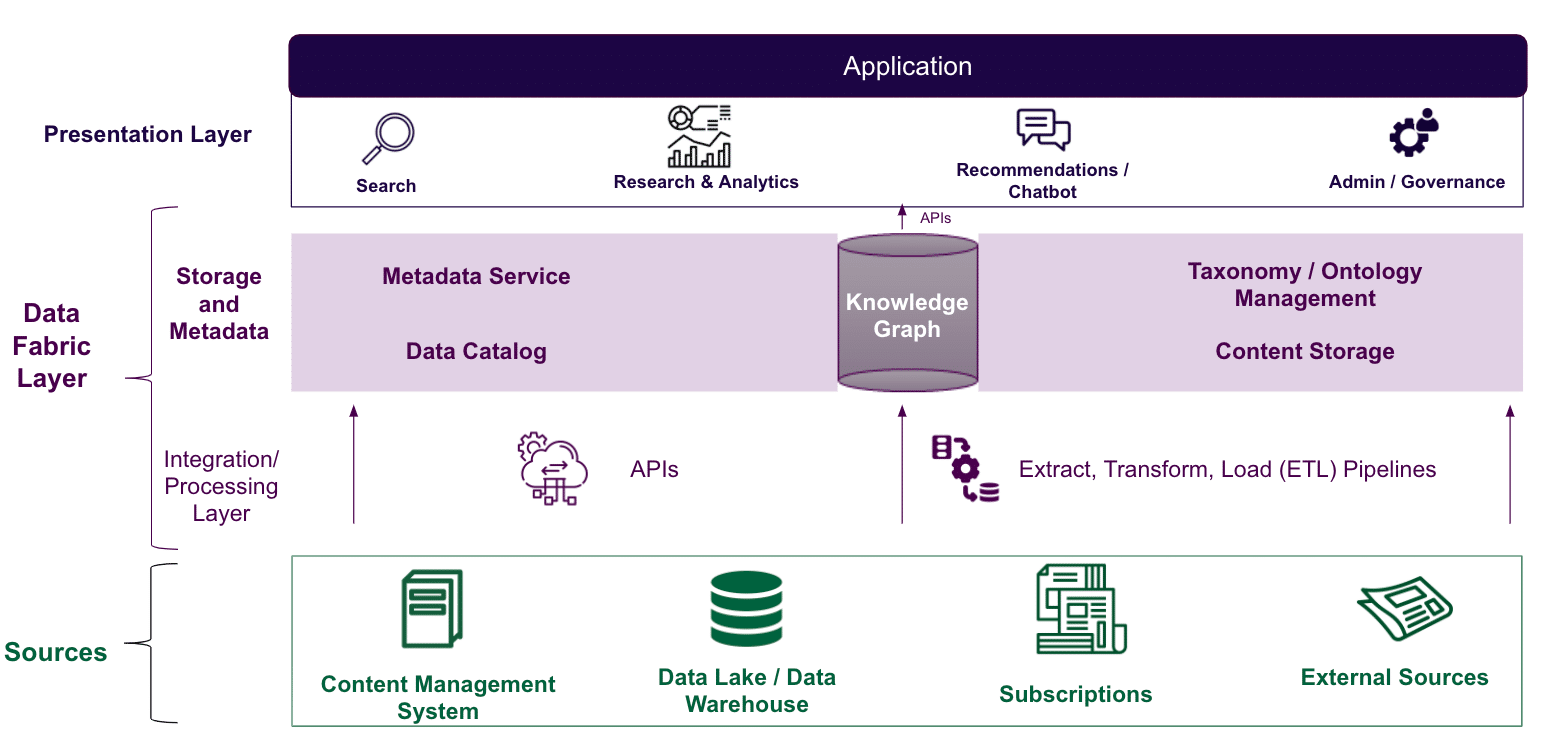 Conceptual Diagram for Data Fabric / Knowledge Graph layer
Conceptual Diagram for Data Fabric / Knowledge Graph layer
We have been working on multiple efforts where organizations are employing these data abstraction and delivery models through metadata and taxonomy unification, labeling or cataloging (data catalogs), data integration or orchestration (ETL/ELT pipelines), and data virtualization solutions to support multiple types of data users and applications. Great examples of the application and use cases of a data fabric for our clients include constructing Customer-360 and Enterprise-360 degree views, targeted content recommenders and chatbot applications that are powered by enterprise knowledge graphs.

Data Mesh
Data Mesh is a distributed approach to enterprise data management focused on building business-focused data products. A working Data Mesh model ultimately enables decentralized data operations and a self-service infrastructure. This is achieved by employing tools or solutions that are based on a microservices architecture as well as open source linked data sources and software applications that decentralize data ownership and management. According to Zhamak Dehghani, the expert who coined the term and framework, key principles of Data Mesh include:
- Treating data as a product – The disruptive nature of a data mesh architecture empowers individual business units to own and manage their data and provide it to other departments and even customers as a product itself.
- Domain-driven ownership of data – Data are owned by those who create it, understand it and know how to manage it. This provides leadership and business users the ability to find, explore, create, label, merge, or add new data sources based on their use cases and needs in a globally governed environment.
- Self-serve data platforms – Business domain teams have self-serve platforms that abstract the complexity of data creation to intuitively create and consume data products.
- Federated computational governance – The mesh is created based on interoperability standards and serves as an ecosystem where users can get value from aggregation and correlation of independent data products.
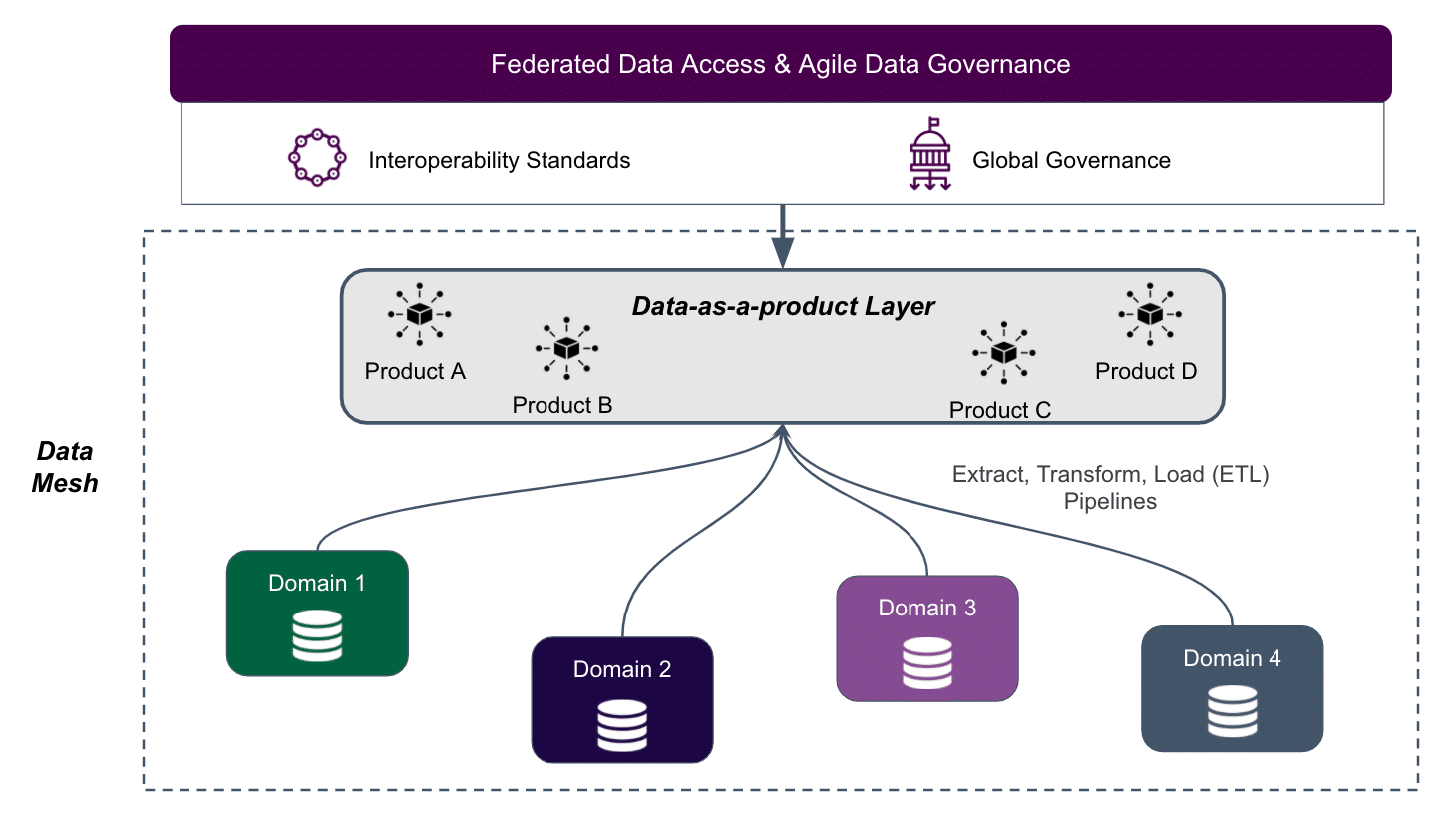 Conceptual Diagram for a Data Mesh
Conceptual Diagram for a Data Mesh
Data Mesh is not a single technology, system, or platform. Rather, it is a framework that facilitates the realization of the above-mentioned principles of data democratization. An example of this is a project where we are supporting one of the largest global digital marketing firms that has been collecting consumer data from hundreds of primary sources to build consumer marketing databases. We have been working with them to develop a distributed architecture that will ultimately allow them to deduplicate and standardize their consumer data of over 2 billion records into a clean and validated data product that can be used for reporting and marketing functions, customer services departments as well as a data-product to its retail affiliates.

DataOps
DataOps is a blanket term that synchronizes the people, process, data, technology and end-to-end value stream across the data development and processing lifecycle. It is the adoption of Agile frameworks along with software engineering development and operations (DevOps) practices for data analytics and machine learning programs to reduce data processing time and improve data quality at scale. Gartner calls this “XOps” (data, machine learning, model, and platform) to achieve efficiencies; and to ensure reliability, reusability and repeatability of data while reducing the duplication of technology and processes. In addition to embracing some of the aforementioned data trends and frameworks, successful DataOps organizations apply the following emerging data practices:
- Data Findability and Discoverability – Helping the organization discover and understand what data are available is the first step toward data democratization and access to the business value of data. Data discovery is one of the ultimate drivers for DataOps. DataOps facilitates this through access and governance control processes and data visualization solutions (like Tableau or PowerBI) for business users to retrieve, analyze and curate the data they need.
- Agile Delivery – DataOps creates cross-functional, self-organizing teams that collaborate to build and deliver end-to-end data solutions including domain experts, product owners, data engineers and software engineering teams.
- Governance and Scalability – Key forces behind DataOps are speed and quality with reliability in mind. Automation of data curation, governance, and labeling or cataloging, supported by shared data guidelines encourages teams across the organization to establish processes that produce and deliver data of high quality, in a standardized format that is easy to access and scale.
For one of our clients in the healthcare industry, our partnership with their DevOps team meant aligning and embedding DataOps practices in order to support consistent value delivery from their machine learning algorithms in the form of targeted content recommendations.
In this scenario, our data solution combines a data fabric that is built on a knowledge graph with a DataOps approach that delivers personalized learning content as a microservice to their multiple applications and ultimately, to over 2 million of their respective customers. While their DevOps team is focused on optimizing and streaming feature builds and software delivery, the DataOps process focuses on automating the aggregation and enrichment of structured and unstructured data towards delivering value.

Conclusion
These emerging practices are not mutually exclusive. Rather, each seeks to challenge the status quo in order to democratize, operationalize, and scale multiple data processing and development efforts and make data available for the whole organization. Additionally, with a common goal to move the business and domain owners closer to the data, these trends continue to demonstrate the shrinking gap between knowledge and data management within the enterprise.
It is also worth noting that there is no single software application, stand-alone system or platform that provides such an environment or transformation. Adopting the relevant solution(s) for your organization requires a blend of architecture, technology, and alignment across people, process, culture, and the base technologies.
How have you been navigating these challenges? Are you looking for help in realizing business value from these data trends and practices or are seeking guidance on your own organization’s transformation? Reach out to us and learn more.