
When working with organizations on key data and knowledge management initiatives, we’ve often noticed that a roadblock is the lack of quality (relevant, meaningful, or up-to-date) existing content an organization has. Stakeholders may be excited to get started with advanced tools as part of their initiatives, like graph solutions, personalized search solutions, or advanced AI solutions; however, without a strong backbone of semantic models and context-rich content, these solutions are significantly less effective. For example, without proper tags and content types, a knowledge portal development effort can’t fully demonstrate the value of faceting and aggregating pieces of content and data together in ‘knowledge panes’. With a more semantically rich set of content to work with, the portal can begin showing value through search, filtering, and aggregation, leading to further organizational and leadership buy-in.
One key step in preparing content is the application of metadata and organizational context to pieces of content through tagging. There are several tagging approaches an organization can take to enrich pre-existing content with metadata and organizational context, including manual tagging, automated tagging capabilities from a taxonomy and ontology management system (TOMS), using apps and features directly from a content management solution, and various hybrid approaches. While many of these approaches, in particular acquiring a TOMS, are recommended as a long-term auto-tagging solution, EK has recommended and implemented Large Language Model (LLM)-based auto-tagging capabilities across several recent engagements. Due to LLM-based tagging’s lower initial investment compared to a TOMS and its greater efficiency than manual tagging, these auto-tagging solutions have been able to provide immediate value and jumpstart the process of re-tagging existing content. This blog will dive deeper into how LLM tagging works, the value of semantics, technical considerations, and next steps for implementing an LLM-based tagging solution.
Overview of LLM-Based Auto-Tagging Process
Similar to existing auto-tagging approaches, the LLM suggests a tag by parsing through a piece of content, processing and identifying key phrases, terms, or structure that gives the document context. Through prompt engineering, the LLM is then asked to compare the similarity of key semantic components (e.g., named entities, key phrases) with various term lists, returning a set of terms that could be used to categorize the piece of content. These responses can be adjusted in the tagging workflow to only return terms meeting a specific similarity score. These tagging results are then exported to a data store and applied to the content source. Many factors, including the particular LLM used, the knowledge an LLM is working with, and the source location of content, can greatly impact the tagging effectiveness and accuracy. In addition, adjusting parameters, taxonomies/term lists, and/or prompts to improve precision and recall can ensure tagging results align with an organization’s needs. The final step is the auto-tagging itself and the application of the tags in the source system. This could look like a script or workflow that applies the stored tags to pieces of content.
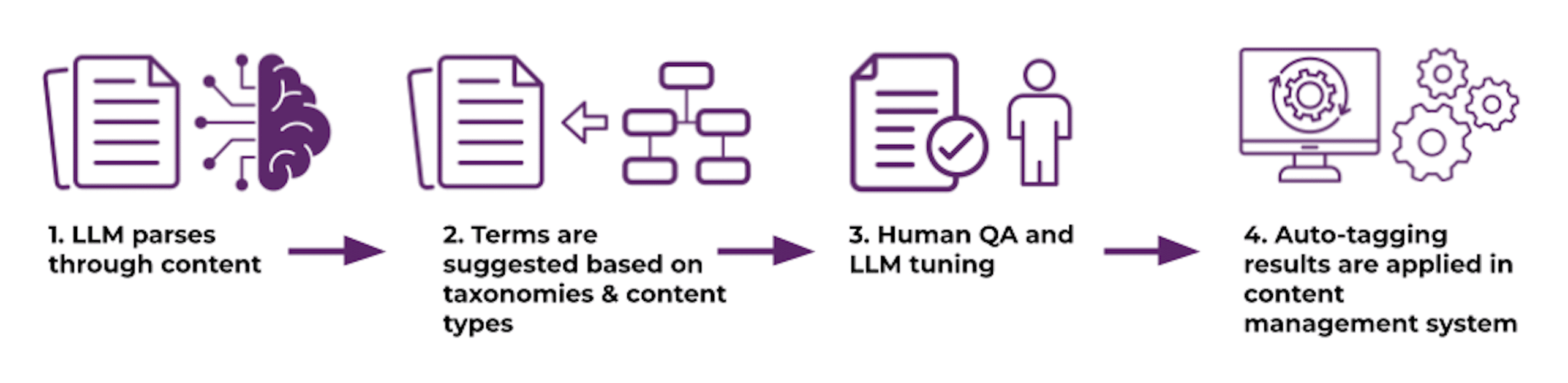
Figure 1: High-level steps for LLM content enrichment
EK has put these steps into practice, for example, when engaging with a trade association on a content modernization project to migrate and auto-tag content into a new content management system (CMS). The organization had been struggling with content findability, standardization, and governance, in particular, the language used to describe the diverse areas of work the trade association covers. As part of this engagement, EK first worked with the organization’s subject matter experts (SMEs) to develop new enterprise-wide taxonomies and controlled vocabularies integrated across multiple platforms to be utilized by both external and internal end-users. To operationalize and apply these common vocabularies, EK developed an LLM-based auto-tagging workflow utilizing the four high-level steps above to auto-tag metadata fields and identify content types. This content modernization effort set up the organization for document workflows, search solutions, and generative AI projects, all of which are able to leverage the added metadata on documents.
Value of Semantics with LLM-Based Auto-Tagging
Semantic models such as taxonomies, metadata models, ontologies, and content types can all be valuable inputs to guide an LLM on how to effectively categorize a piece of content. When considering how an LLM is trained for auto-tagging content, a greater emphasis needs to be put on organization-specific context. If using a taxonomy as a training input, organizational context can be added through weighting specific terms, increasing the number of synonyms/alternative labels, and providing organization-specific definitions. For example, by providing organizational context through a taxonomy or business glossary that the term “Green Account” refers to accounts that have met a specific environmental standard, the LLM would not accidentally tag content related to the color green or an account that is financially successful.
Another benefit of an LLM-based approach is the ability to evolve both the semantic model and LLM as tagging results are received. As sets of tags are generated for an initial set of content, the taxonomies and content models being used to train the LLM can be refined to better fit the specific organizational context. This could look like adding additional alternative labels, adjusting the definition of terms, or adjusting the taxonomy hierarchy. Similarly, additional tools and techniques, such as weighting and prompt engineering, can tune the results provided by the LLM and evolve the results generated to achieve a higher recall (rate the LLM is including the correct term) and precision (rate the LLM is selecting only the correct term) when recommending terms. One example of this is adding weighting from 0 to 10 for all taxonomy terms and assigning a higher score for terms the organization prefers to use. The workflow developed alongside the LLM can use this context to include or exclude a particular term.
Implementation Considerations for LLM-Based Auto-Tagging
Several factors, such as the timeframe, volume of information, necessary accuracy, types of content management systems, and desired capabilities, inform the complexity and resources needed for LLM-based content enrichment. The following considerations expand upon the factors an organization must consider for effective LLM content enrichment.
Tagging Accuracy
The accuracy of tags from an LLM directly impacts end-users and systems (e.g., search instances or dashboards) that are utilizing the tags. Safeguards need to be implemented to ensure end-users can trust the accuracy of the tagged content they are using. These help ensure that a user is not mistakenly accessing or using a particular document, or that they are frustrated by the results they get. To mitigate both of these concerns, a high recall and precision score with the LLM tagging improves the overall accuracy and lowers the chance for miscategorization. This can be done by investing further into human test-tagging and input from SMEs to create a gold-standard set of tagged content as training data for the LLM. The gold-standard set can then be used to adjust how the LLM weights or prioritizes terms, based on the organizational context in the gold-standard set. These practices will help to avoid hallucinations (factually incorrect or misleading content) that could appear in applications utilizing the auto-tagged set of content.
Content Repositories
One factor that greatly adds technical complexity is accessing the various types of content repositories that an LLM solution, or any auto-tagging solution, needs to read from. The best content management practice for auto-tagging is to read content in its source location, limiting the risk of duplication and the effort needed to download and then read content. When developing a custom solution, each content repository often needs a distinctive approach to read and apply tags. A content or document repository like SharePoint, for example, has a robust API for reading content and seamlessly applying tags, while a less widely adopted platform may not have the same level of support. It is important to account for the unique needs of each system in order to limit the disruption end-users may experience when embarking on a tagging effort.
Knowledge Assets
When considering the scalability of the auto-tagging effort, it is also important to evaluate the breadth of knowledge asset types being analyzed. While the ability of LLMs to process several types of knowledge assets has been growing, each step of additional complexity, particularly evaluating multiple types, can result in additional resources and time needed to read and tag documents. A PDF document with 2-3 pages of content will take far fewer tokens and resources for an LLM to read its content than a long visual or audio asset. Going from a tagging workflow of structured knowledge assets to tagging unstructured content will increase the overall time, resources, and custom development needed to run a tagging workflow.
Data Security & Entitlements
When utilizing an LLM, it is recommended that an organization invest in a private or an in-house LLM to complete analysis, rather than leveraging a publicly available model. In particular, an LLM does not need to be ‘on-premises’, as several providers have options for LLMs in your company’s own environment. This ensures a higher level of document security and additional features for customization. Particularly when tackling use cases with higher levels of personal information and access controls, a robust mapping of content and an understanding of what needs to be tagged is imperative. As an example, if a publicly facing LLM was reading confidential documents on how to develop a company-specific product, this information could then be leveraged in other public queries and has a higher likelihood of being accessed outside of the organization. In an enterprise data ecosystem, running an LLM-based auto-tagging solution can raise red flags around data access, controls, and compliance. These challenges can be addressed through a Unified Entitlements System (UES) that creates a centralized policy management system for both end users and LLM solutions being deployed.
Next Steps:
One major consideration with an LLM tagging solution is maintenance and governance over time. For some organizations, after completing an initial enrichment of content by the LLM, a combination of manual tagging and forms within each CMS helps them maintain tagging standards over time. However, a more mature organization that is dealing with several content repositories and systems may want to either operationalize the content enrichment solution for continued use or invest in a TOMS. With either approach, completing an initial LLM enrichment of content is a key method to prove the value of semantics and metadata to decision-makers in an organization.
Many technical solutions and initiatives that excite both technical and business stakeholders can be actualized by an LLM content enrichment effort. By having content that is tagged and adhering to semantic standards, solutions like knowledge graphs, knowledge portals, and semantic search engines, or even an enterprise-wide LLM Solution, are upgraded even further to show organizational value.
If your organization is interested in upgrading your content and developing new KM solutions, contact us!