
Have you been catching up on your favorite TV shows lately? If so, while watching a series or movie from home, it is very likely you might have asked yourself the following questions:
- “The narrator’s voice sounds familiar, who is it?”
- “What is that actor’s name? I think I might have seen him in another movie.”
- “Isn’t she the actress from this other show I watched some years ago?”
A few years ago, these questions might have gone unanswered if neither you nor any of the people with you knew the answer, or you might have had to wait until the credits appeared. However, now, all it takes is a simple google search to find all of the answers to those questions. The information that you might find on the internet about the series could be the cast, number of seasons, number of episodes in the season, airing dates, episode summaries, episode length, and production details, among others. This relationship between the TV series and the information you found about it on the internet brings us to the concept of metadata.

Metadata
As you might notice from the example above, metadata is simply data about data. In this particular case, it would be the data on the internet about the videos you watched. The primary use of metadata is to provide context and information about data, as well as enhance findability and describe data, all of which are especially helpful when dealing with unstructured data.
- Structured data: These data follow a defined framework with a set number of fields. Think of a well-formatted spreadsheet where every column contains one specific type of data. An example of this would be a table with personal information, such as name, address, telephone number, and age of multiple people.
- Unstructured data: This data is not able to be stored in a traditional column-row database or spreadsheet. Think of photos, videos, audio, text documents, and websites. Unstructured data is also the most common type of data, and because of its unstructured nature, its metadata is particularly useful to help us find it and make sense of it. How would you be able to find a movie without being able to search by its title, who stars in it, or what it is about?
Amazon Prime Video Meets IMDB
IMDB is a database designed to provide TV watchers and cinephiles information about millions of TV shows and films, including cast biographies and reviews. In 1998, Amazon bought IMDB to acquire its lucrative user base and give its Amazon Prime Video streaming service a marketing push. This strategic acquisition allowed Amazon to promote its video streaming service to an already targeted user base.
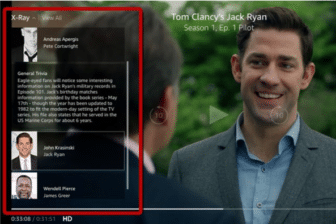
Amazon Prime Video and IMDB kept growing in both content and active users. The streaming service not only got its marketing push, but also integrated its user-generated data (such as user behavior and preferences) with IMDB’s database to boost its recommendation systems across platforms. So, how could these two successful products be further integrated? Fast forward about a decade, and Amazon Prime Video added a new feature called X-Ray.
Remember those questions that many people have while watching a video? Well, X-Ray takes care of that. Now, when pausing your favorite show, X-Ray will display information about what you are currently viewing. This includes cast information, filmographies, facts, trivia, character backstories, photo galleries, bonus video content, and music. By leveraging metadata from IMDB, Amazon Prime Video can add structure to unstructured video content, enabling users to answer those nagging questions.
Building More Informed Recommendation Systems
Recently, due to the COVID-19 crisis, video streaming services have been experiencing a surge in demand. As people catch up on their favorite series, streaming service firms need to keep their customers engaged by recommending related material that would keep them active.
At Enterprise Knowledge, we had the opportunity to work with a prominent client in the telecommunications industry. We improved their recommendation systems, leveraging the power of metadata on its unstructured content. The enhanced recommendation system takes the viewers’ input based on a specific scene the viewer is currently watching. The engine would ingest information pulled from the closed captioning file and internal and external databases containing information about the tv series, episode, and scene. The resulting recommendation system would not only work on general information about the tv series such as genre, recurring cast, summaries, and network, but it would also take specific details about the scene, such as sentiment inferred from the subtitles, non-recurring cast appearances, and particular music in the scene, improving the recommendations provided to the viewer.
viewers’ input based on a specific scene the viewer is currently watching. The engine would ingest information pulled from the closed captioning file and internal and external databases containing information about the tv series, episode, and scene. The resulting recommendation system would not only work on general information about the tv series such as genre, recurring cast, summaries, and network, but it would also take specific details about the scene, such as sentiment inferred from the subtitles, non-recurring cast appearances, and particular music in the scene, improving the recommendations provided to the viewer.
Beyond the media or telecommunications industries, metadata has an equally crucial role in making unstructured data usable and accessible. It allows enterprise applications to link unstructured content based on assigned attributes included in the metadata. As another example, in the pharmaceutical industry, a recommendation system would take research papers, formulations, and experiment reports and link them based on related chemical compounds, illnesses, or authors. These links in the data power up recommendation systems and enterprise search engines that provide content at the users’ point of need. The resulting enterprise applications are as powerful as the quality and completeness of the metadata used to derive the results.
The benefits of including metadata as an integral part of an organization’s strategy include:
- Content findability, reuse, and sharing: Metadata ensures that complex content is easily understood and processed by people other than the content creator. Hence, it allows anyone in the organization to find the content they need to do their jobs regardless of content type, knowledge of its existence, who owns it, or where it is located. This results in increased productivity and higher quality of work.
- Data Governance: Metadata can also serve as an annotation tool that denotes content ownership and temporality since some data may be deemed irrelevant after a specific timeframe. This also makes it easier to identify who is responsible for the timeliness and the quality of the content. Furthermore, it can be used to trigger workflows that ensure the content is accurate and up to date, if necessary. As a result, organizations have greater control over their content and data, ensuring the right people are finding and acting on the right information.
- Innovation and Service: When employees spend less time asking coworkers for content, looking for information, recreating information, and waiting for answers, they have more time for innovation and customer support. This, in turn, results in greater employee and customer satisfaction, which leads to higher employee and customer retention.
Conclusion
In conclusion, metadata provides structure to unstructured content, making it machine-readable and ready to work with machine learning and artificial intelligence applications. In my specific example, Enterprise Knowledge enhanced the client’s unstructured video content using internal and external sourced data to provide a metadata rich environment. This environment gave the recommendation system access to new information on which to drive its decisions, culminating in better recommendations that keep TV watchers engaged. Similarly, we can help your organization connect your data, content, and people in ways to enhance your corporate knowledge, resulting in the benefits I discussed above.
Does your organization need assistance in leveraging metadata to enhance its unstructured content? Feel free to reach out to us for help!