
As organizations accelerate investments in AI, semantic data models, advanced analytics, and agentic transformation, lots of jargon gets thrown around, and this sometimes results in confusion about how data driven systems work. In the realm of semantic layers, one of the key terminological distinctions that frequently gets glossed over is the distinction between ontologies and knowledge graphs. In this article, we will examine the differences between ontologies and knowledge graphs, how they interact with one another, and how they can each be used to supplement and constrain generative AI as two key components of the semantic layer.
Ontologies
An ontology is a formal, explicit model of the entities in a domain, the attributes those entities have, the relationships that hold between entities, and the constraints that exist on those relationships. In simpler terms, an ontology is a shared map of a subject area — capturing what things exist, what we know about them, how they connect, and what rules govern those connections. An ontology is not data. Rather, it provides a generalized, meaningful schema of your data. And unlike a simple data model or relational database schema, an ontology focuses on both structure and meaning. Because ontologies define the connections between things within a subject area, they enable interconnection of data. And because they operate with definitions that are consistently interpretable by both machines and humans, they also enable data standardization and integration of systems across an enterprise.
At its core, an ontology is built from a small set of foundational components: classes, attributes, and relations. These components are intentionally general and abstract; they define the structure of a subject area without tying it to a specific technical implementation.
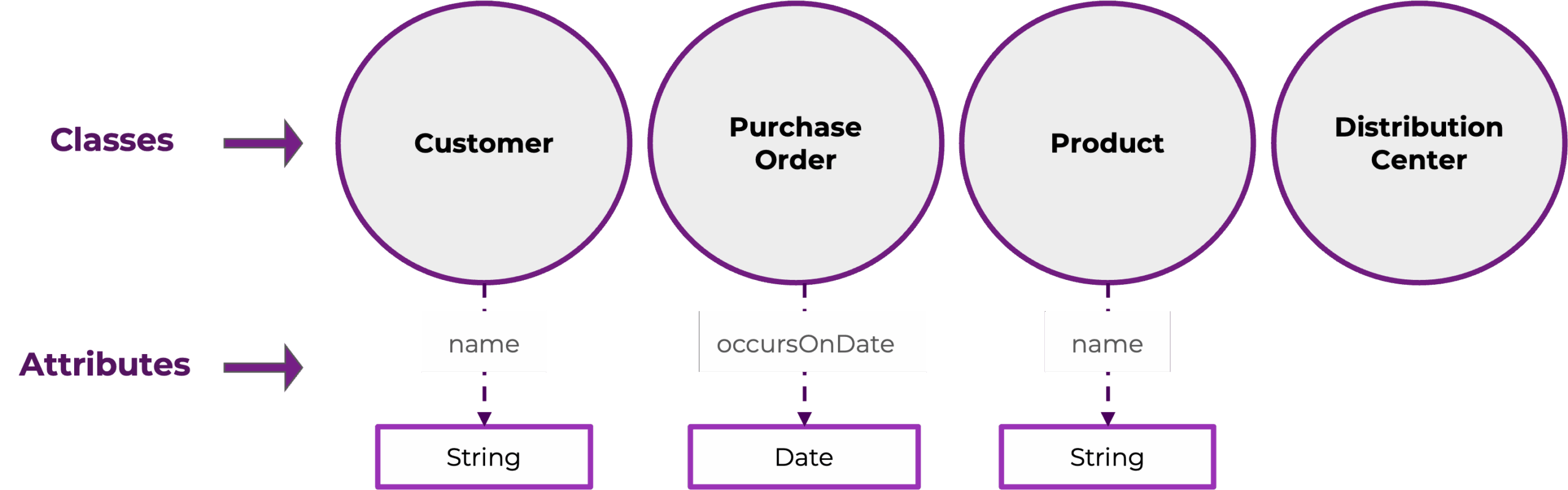
Classes represent the categories or types of things that exist in a data domain. For example, if your data pertains to individual purchase orders placed by customers for specific products and fulfilled by particular distribution centers, your ontology would likely include classes like Customer, Purchase Order, Product, and Distribution Center.

Note that these are representations of general types of things. The class Customer, for example, does not represent any particular customer, but rather the category of customers, and it can be used to categorize individual customers across multiple different datasets.
Attributes describe the characteristics or properties that members of a class can have. Customers and products, for example, have names. Purchase orders occur on particular dates. Like classes, ontology attributes are general. They describe the kinds of information that can be associated with members of a class, but not any actual values.
Relations define how members of classes can relate or connect to one another. In the case of our example customer purchase data, for example, there are several relations that could hold between the members of our classes. Purchase orders are placed by customers, they are orders for particular products, and they can be fulfilled by distribution centers, which can distribute products.
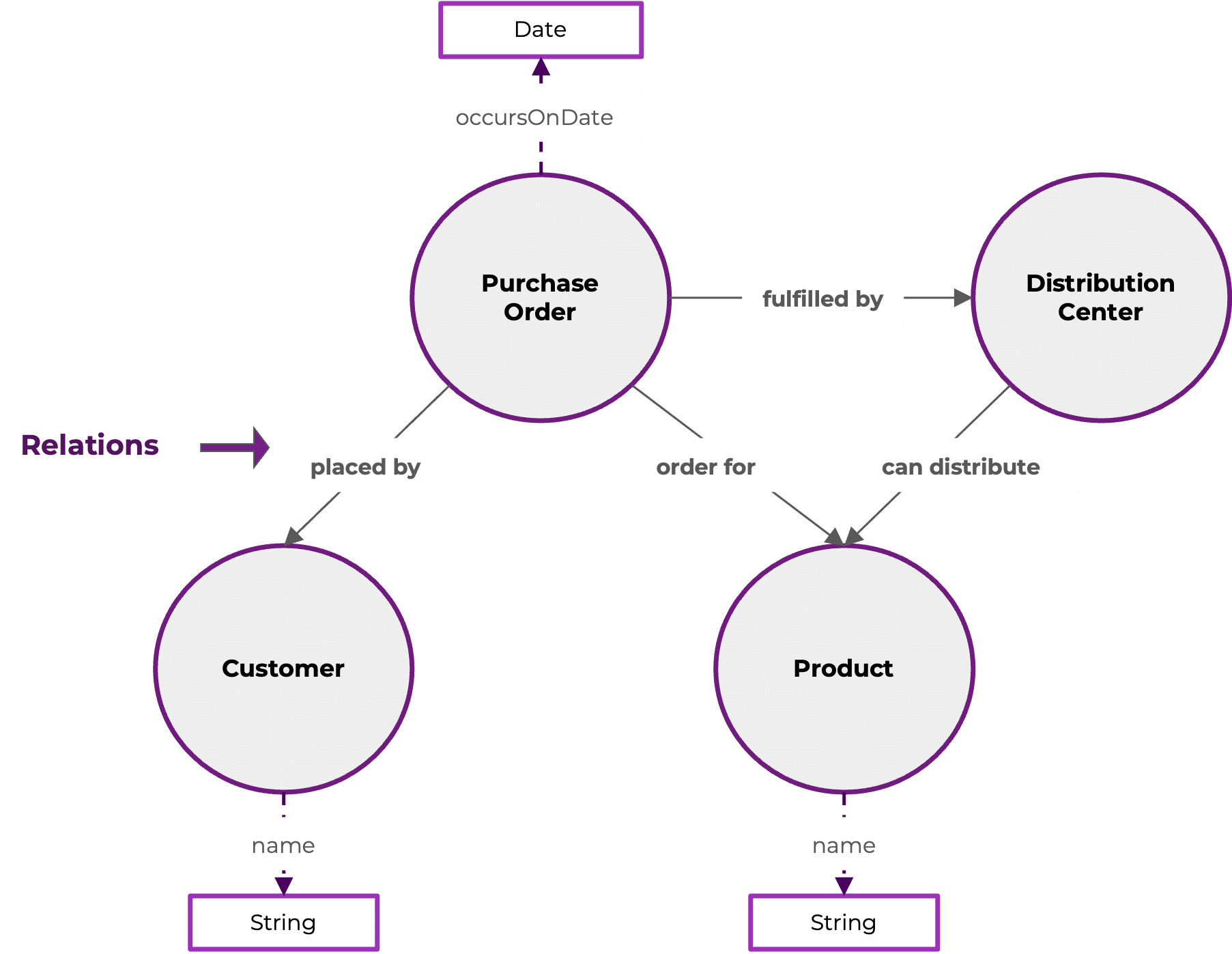
As with classes and attributes, relations in an ontology describe general connections that can be made between members of different classes. They provide a roadmap for the linkages that can be drawn between data elements.
Ontologies +
An ontology provides a standardized, structured, machine-readable representation of a knowledge domain. As we will see in the next section on knowledge graphs, this makes the ontology the semantic backbone for your data: standardizing it, enabling linkages, and encoding the meaning along with the data itself. Ontologies by themselves can be useful for facilitating alignment of Large Language Models (LLMs).
Large language models like GPT, Claude, Gemini, and Llama are trained on extremely broad bases of largely publicly-available training data, which can lead them to answer questions through a lens that is applicable to the general public, but not to your particular business use cases. An ontology, on the other hand, is usually built to represent the organization’s particularized way of understanding the domain. As a result, you can guide LLM processing to greater accuracy and alignment with your business by injecting part, or all, of the ontology into your LLM prompts. If your business has very particular requirements for eligibility for a consulting agreement, for example, by explicitly supplying the LLM with the required relations for, and definition of, a consulting agreement as it occurs in your ontology, you can improve the LLM’s responses by ensuring it understands your business’ particular understanding of the concept.
In addition to assisting with alignment in individual LLM calls made by applications, these same semantic constraints can be applied across agentic AI systems, ensuring that all AI agents in the system align on the same understanding of the concepts important to your business.
Knowledge Graphs
As we have seen, an ontology provides a general, abstracted representation of a domain of knowledge. In a way, it provides a semantic schema which can be used to structure data. A knowledge graph is data structured via an ontology. So, while our ontology defines the classes Customer and Purchase Order, and the relations and attributes that pertain to those classes, a knowledge graph using this ontology would contain representations of individual customers and individual purchase orders, record the specific values for attributes on those individuals, and illustrate the links between them.
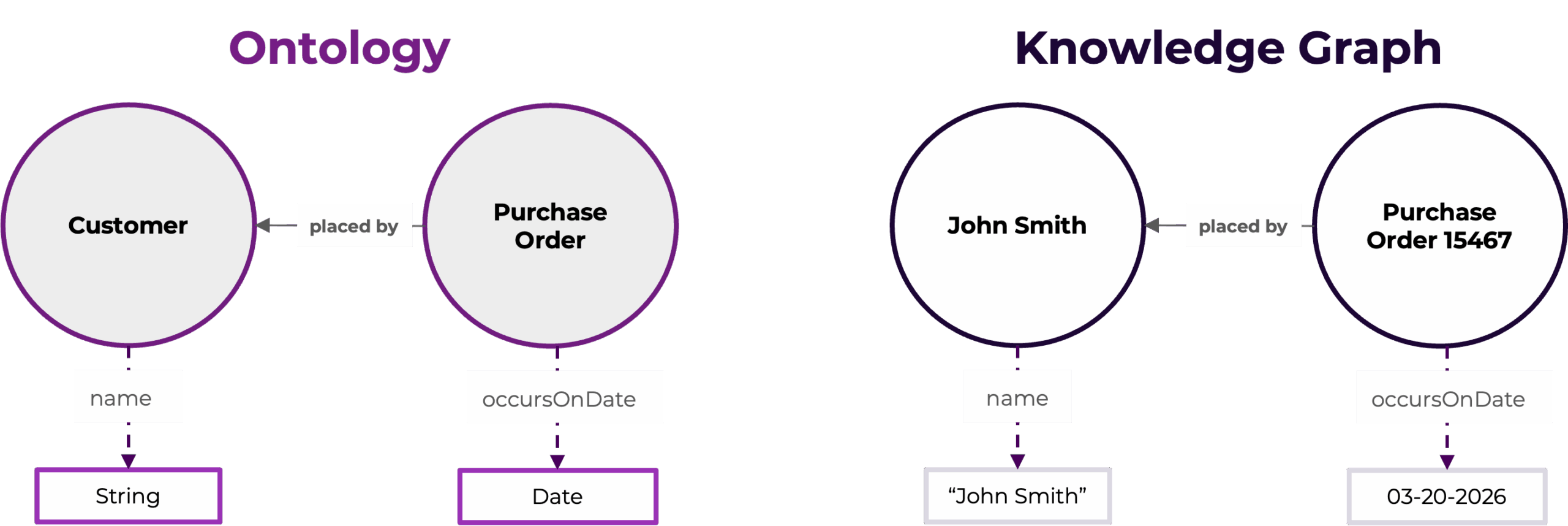
The knowledge graph contains all of your relevant data, structured, linked, and constrained by the ontology. Essentially, the knowledge graph houses your data as a web of entities linked with one another. This linked web of data can be queried using query languages such as SPARQL, or accessed via APIs using SPARQL or transformations to languages such as JSON-LD or YAML. Graph data is accessible to LLMs via these means or via Model Context Protocol (MCP) servers.
The semantic structure provided by the ontology enables the potential identification of new, valuable links in your data, or even generation of additional data and metadata via inference rules. For example, if a customer counts as preferred at your company when they have made twenty purchases, an inference rule can be written to capture this policy. On the basis of this rule, when a customer’s twentieth purchase is recorded in the data, a customer can be automatically tagged with preferred status.
Knowledge Graphs +
As with ontologies, knowledge graphs are useful in reigning in or directing LLMs in ways that enable greater accuracy and alignment with your particular business use case. Many organizations are already employing Retrieval-Augmented Generation (RAG) to move LLMs beyond what they have learned in basic language training. RAG dynamically retrieves relevant information from external knowledge sources at query time, helping LLMs to ground responses in current, authoritative data. The standard RAG architecture selects flat chunks of text to supply as context for an LLM based on textual similarity.
Graph RAG (RAG that utilizes a knowledge graph as the external knowledge source) takes this a step further. Because Graph RAG operates over a knowledge graph instead of flat chunks of text, retrieval of the relevant information is rooted in the semantics of the ontology governing that knowledge graph. As the ontology encodes not just facts, but also meaning, hierarchy, and context, this enables Graph RAG systems to assist with disambiguation in queries. If a simple RAG system being used in an insurance company sees a query about “policy,” for example, it may return multiple chunks of text pertaining to customer insurance policies, underwriting policies, or compliance policies. But only one of these is likely to be relevant to the query. An ontology would represent each of those types of policies distinctly, with distinct relationships. That meaningful context can help disambiguate what the user meant, and allow for more precise retrieval of the desired information.
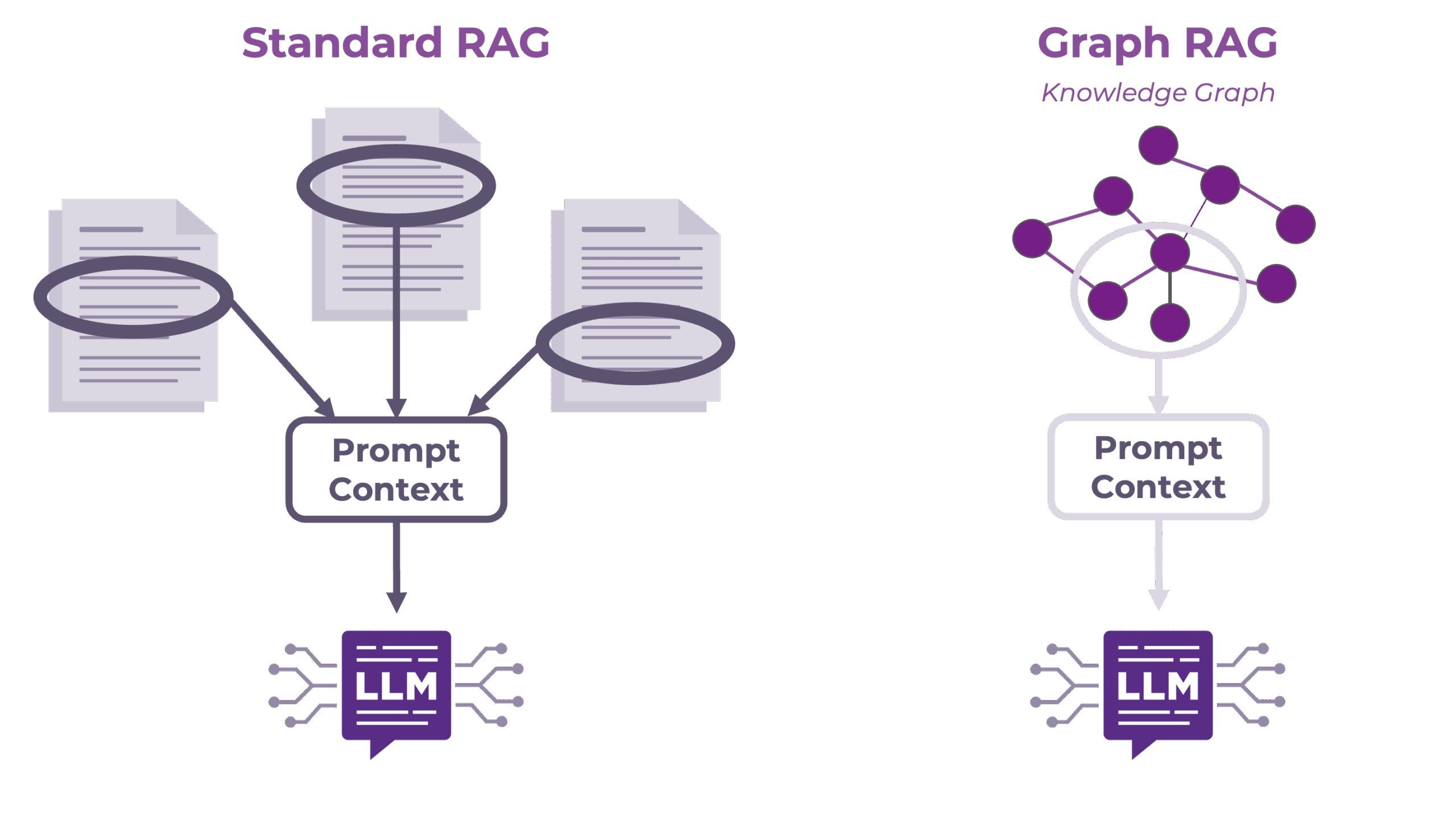
The semantics embedded in a knowledge graph also make it possible for a Graph RAG-assisted LLM or agentic system to traverse conceptual relationships and reason across connected domains in ways that flat document retrieval simply cannot support. For example, suppose you wish to know which of your European suppliers are connected with logistics partners that have been flagged for compliance issues. No single document chunk connects all of these facts together. Basic RAG might find the supplier locations, or the logistics connections, or the compliance issues, but it is unlikely to be able to find all of them and join them. However, because a knowledge graph unifies and links your data, a Graph RAG system would have easy access to the conceptual connection between partners and logistics suppliers, along with their compliance flags, via a simple semantic query. The result is an AI or Agentic AI system whose outputs are anchored in a curated, organization-specific understanding of the world, making responses dramatically more accurate, consistent, and aligned with business intent.
In addition to improving accuracy and alignment, graph retrieval can also improve the efficiency of your AI application or agents. Accurate, business-relevant categorization of your structured and unstructured data via the ontology enables LLMs or agentic systems to efficiently retrieve only the most relevant data for their tasks. Every piece of irrelevant data pulled in to be processed by an LLM or AI agent increases token costs. By enabling retrieval of targeted types of data, knowledge graphs simultaneously improve the performance of AI and agentic systems and reduce the operating costs for those systems.
Conclusion
Ontologies and knowledge graphs are distinct but deeply complementary artifacts. An ontology provides the semantic backbone: a formal, meaningful model of your domain that encodes not just structure, but conceptual relationships, hierarchies, and definitions that reflect your organization’s particular understanding of its business. A knowledge graph builds on that backbone with real data, populating the semantic scaffold with actual entities, attribute values, and the links between them, creating a richly connected, queryable representation of your organizational knowledge.
Together, these two artifacts offer powerful and complementary mechanisms for improving LLM performance. Ontology injection allows organizations to anchor LLM reasoning in domain-specific semantics at the prompt level, ensuring the LLM model or AI agent interprets key concepts, relationships, and constraints the way your business does, rather than through the lens of its broad general training. Graph RAG goes further still, dynamically retrieving contextually relevant, ontologically structured data at query time, enabling the LLM or AI agent to reason across connected knowledge rather than isolated text fragments. The semantic richness of the underlying ontology is what makes this retrieval meaningful — it is the difference between finding information and understanding it.
To discuss how ontologies and knowledge graphs can support your organization’s next phase of AI adoption, contact us and connect with our team!