
We have been at the forefront of implementing generative technologies to augment traditional taxonomy workflows offering new capabilities for content modeling, classification, and semantic enrichment. This raises an important question for practitioners: What are the implications of Generative AI for the role of the Taxonomist?
It is important to highlight, as emphasized in several blogs authored by EK’s Taxonomy and AI experts, that a major part of implementing AI capabilities is the need for human expertise and/or human-in-the-loop workflows. While AI promotes the ability to achieve more with less, it is only as effective as the data available. Human involvement remains a necessary facet to provide context, decision-making, and strategy. Taxonomists who set the overall strategy and standards for how taxonomies are developed and used can guide how the advanced capabilities are used. This piece pulls together our collective experiences to highlight how taxonomists fit into this new paradigm, and how your organization can leverage this synergy to optimize your taxonomy and semantic processes.
AI-driven Taxonomy Creation
Having personal experience working with GenAI taxonomy “helper” tools that can be used to generate potential lists of labels, hierarchical terms, alternate labels, definitions, and support validation, it is evident that the quality of the output is dependent on multiple factors. The taxonomy model design (specificity of the domain), the data analyzed, and the prompts used, and ongoing training all influence the output of these models. What all of these factors have in common, is that they underscore the ongoing need for inclusion of taxonomist expertise.
Curating Large Language Models (LLMs) Training Sets
Beyond the relationship of how AI can help taxonomists, taxonomists also play a crucial role in optimizing the training of Large Language Models (LLMs) by leveraging their understanding of programmatic knowledge representation and structured and unstructured information, what we broadly refer to as knowledge assets. To train LLMs, they must be exposed to a training corpus. Taxonomists can curate specific training sets, both good and bad examples, to test the performance of the LLM and determine if modifications are needed. This strategic selection is not arbitrary; it is guided by taxonomist expertise in developing hierarchical classifications, ontologies, controlled vocabularies, and familiarity with organization knowledge assets.
Furthermore, taxonomists are better equipped to introduce knowledge assets that address potential biases or gaps inherent in large, unfiltered corpora. By intentionally including examples that represent diverse perspectives or underrepresented concepts, they can help mitigate the propagation of undesirable biases in the LLM’s eventual outputs. Taxonomist insight into how knowledge is organized and accessed allows them to anticipate areas where an LLM might struggle with ambiguity or inconsistency and then provide tailored training examples to address these challenges proactively. Ultimately, this specialized intervention by taxonomists before full corpus exposure results in LLMs that are not only more accurate and coherent in their understanding, but also more capable of generating nuanced and contextually appropriate responses.
Ensuring Knowledge Asset Quality for AI Output
As we discussed in detail in Top Ways to Get Your Content and Data Ready for AI, AI-powered organizations will look first to their knowledge assets as the key building block to drive success. The precision and accuracy of AI output is a direct reflection of the contextual framing and access to high-quality knowledge assets.
To ensure high quality knowledge assets, comprehensive cleanup efforts are necessary to de-duplicate and purge outdated or erroneous data that could compromise AI effectiveness. Often clean up efforts are not addressed due to the sheer size of the work that may be involved. Taxonomists, who work with these knowledge assets as well as their organizational structures, can provide insight into key areas that would benefit from clean up. This can help SMEs pinpoint where to focus their efforts rather than trying to boil the ocean.
Following cleanup, it becomes important to establish structure and context to these knowledge assets. A taxonomist fundamentally provides this structure by organizing knowledge assets into hierarchical or relational categories. This structure defines what each knowledge asset means, clarifying its specific purpose, scope, and content. This structured approach also illuminates how these individual assets integrate into the broader organizational knowledge landscape. For example, “Crane” categorized under construction equipment clearly means the machine used to raise and lower objects and not the bird. Taxonomists possess the requisite theoretical and practical knowledge and skills to design models suitable for various use cases. By applying pertinent metadata to knowledge assets (tagging), additional context is provided for AI utilization. Furthermore, the increasing sophistication of taxonomy management software, which includes auto tagging capabilities, significantly reduces the reliance on manual efforts and is a workflow that can be managed by a taxonomist.
As we articulated in Generative AI for Taxonomy Creation,
“Generative AI focuses on getting answers from text/content. This is only half of the picture when it comes to creating taxonomies. As taxonomies serve to connect users to content, they need to be designed to take into consideration both the users and the content. That’s why taxonomy design involves tasks that involve end users: interviews, focus groups, brainstorming workshops, and term list suggestions from subject matter experts.”
Taxonomists, serving as intermediaries between data and individuals, are ideally positioned to integrate subject matter experts (SME) feedback into the taxonomy design process.
AI-driven Taxonomy Validation
Based on my experience, we also use the methods discussed above to help validate and refine taxonomies. Below are a selection of exciting capabilities that we have enabled for our clients to expedite their taxonomy validation and refinement process:
- Proposing New Terminology and Concepts: AI models, by continuously analyzing evolving content streams can proactively identify emerging concepts and propose new terminology.
- Performing Similarity Analysis to Prevent Redundancy: AI can perform similarity analysis, not just at the lexical level but also at the semantic level, to identify terms or concepts that are highly similar.
- Automated Compliance Review Against Established Rules and Standards: AI can automate the review process, checking proposed taxonomy additions or modifications against established rules and flagging any non-compliance.
- Identifying Potential Relationships Between Terms: Beyond simple hierarchical relationships, AI can uncover more complex and nuanced relationships between terms suggesting new or improved relationships that enrich the taxonomy’s interconnectedness and enhance its utility for navigation, search, and knowledge discovery.
These advanced capabilities collectively contribute to a reduction in the turnaround time for taxonomy updates, moving from a reactive, laborious process to a more proactive, agile one. However, as with AI-assisted taxonomy creation, validation still requires taxonomist intervention. While an AI model possesses the analytical power to recommend new terms, suggest similarities, or identify potential relationships, a domain expert, specifically a taxonomist, must still review these recommendations for their ultimate applicability, accuracy, and strategic fit within the overall information architecture. This human oversight (human-in-the-loop) is paramount because AI, while powerful, lacks the nuanced understanding of organizational context, user behavior, and the subtle human implications of taxonomy changes.
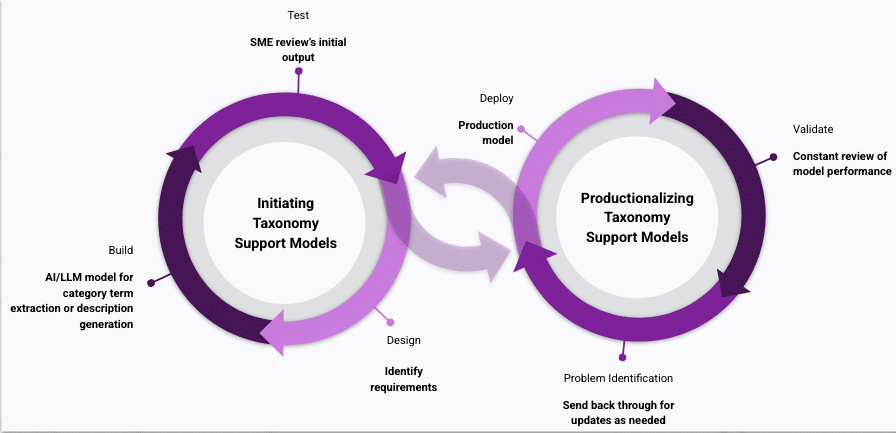
Figure 1: Human-in-the-loop model
The Value of Taxonomy Experts
As domain experts, taxonomists (and their collaborating SMEs) possess a deep comprehension of the human implications of taxonomy updates on downstream users and applications. They understand how a change in a term or relationship might affect user search behavior, the clarity of content presentation, the performance of analytical tools, or the compliance posture of the organization. Their qualitative judgment complements the quantitative insights provided by AI.
Moreover, taxonomists play a pivotal and indispensable role in establishing and maintaining the foundational rules governing taxonomy design and evolution. Fortunately, the standards used in taxonomy construction and management, such as ISO 25964, ANSI/NISO Z39.19, SKOs, RDF, and OWL are mature and stable. But that does not preclude them from being updated.
Taxonomists set the overall strategy for how taxonomies are developed and used within their individual organizations. They develop rules and guidelines tailored to address their particular use cases, business processes, and unique information landscapes. These bespoke use cases and rules require periodic updates or expansions to accommodate new business requirements or technological advancements. In this dynamic environment, taxonomists should be central to ensuring that generative AI systems, which rely heavily on these rules for automated validation and suggestions, consistently utilize the most current, accurate, and strategically aligned rules and standards. Their ongoing stewardship ensures the AI’s efficacy and the taxonomy’s integrity.
Closing
In a recent collaboration with a global investment bank, we successfully transformed their risk management framework through the application of Generative AI. This initiative facilitated the automation of taxonomy development and enhanced the clarity of interconnected risks. Our methodology integrated advanced technological capabilities with human expertise, employing human-in-the-loop models. As the taxonomist, my contribution involved supplying pertinent training data. Subsequently, upon the generation of output by the models, I conducted a thorough review to ascertain accuracy and provided constructive feedback for necessary improvements. This iterative process, as previously noted, requires regular reassessment to ensure sustained accuracy. This endeavor represents a collaborative partnership between data scientists and taxonomists. As a taxonomist with a background in managing knowledge assets, I possess a clear understanding of the anticipated outcomes, while the data scientists’ expertise enables their realization. While subject matter expert (SME) review remains essential, integrating a taxonomist into this process provided an additional layer of oversight, thereby allowing SMEs to allocate more time to strategic initiatives rather than review tasks.
If you are ready to explore how generative AI capabilities can transform your taxonomy management and looking to upskill staff, we have the experience and insights to help with your journey. Contact our team of experts for more information and how we can be of service to you.