
Before AI became part of everyday conversations, most enterprise knowledge and data projects had a somewhat straightforward goal: to create a “single source of truth.” In theory, this meant that everyone in the company could look at the same search results and data dashboards and get the same answers to basic questions like, “Who is our expert on a given topic?” or “What was our revenue last quarter?” In practice, we know how hard it has been to answer those questions. Teams tend to debate the definition of terms and negotiate which data to measure, obscuring one obvious answer. It’s refreshing, however, that the industry now strongly agrees – semantics is key to making AI work in the enterprise. Ironically, even with this agreement, data practitioners are still struggling to agree on the terms themselves; what they mean and how all the pieces should fit together to actually deliver value.
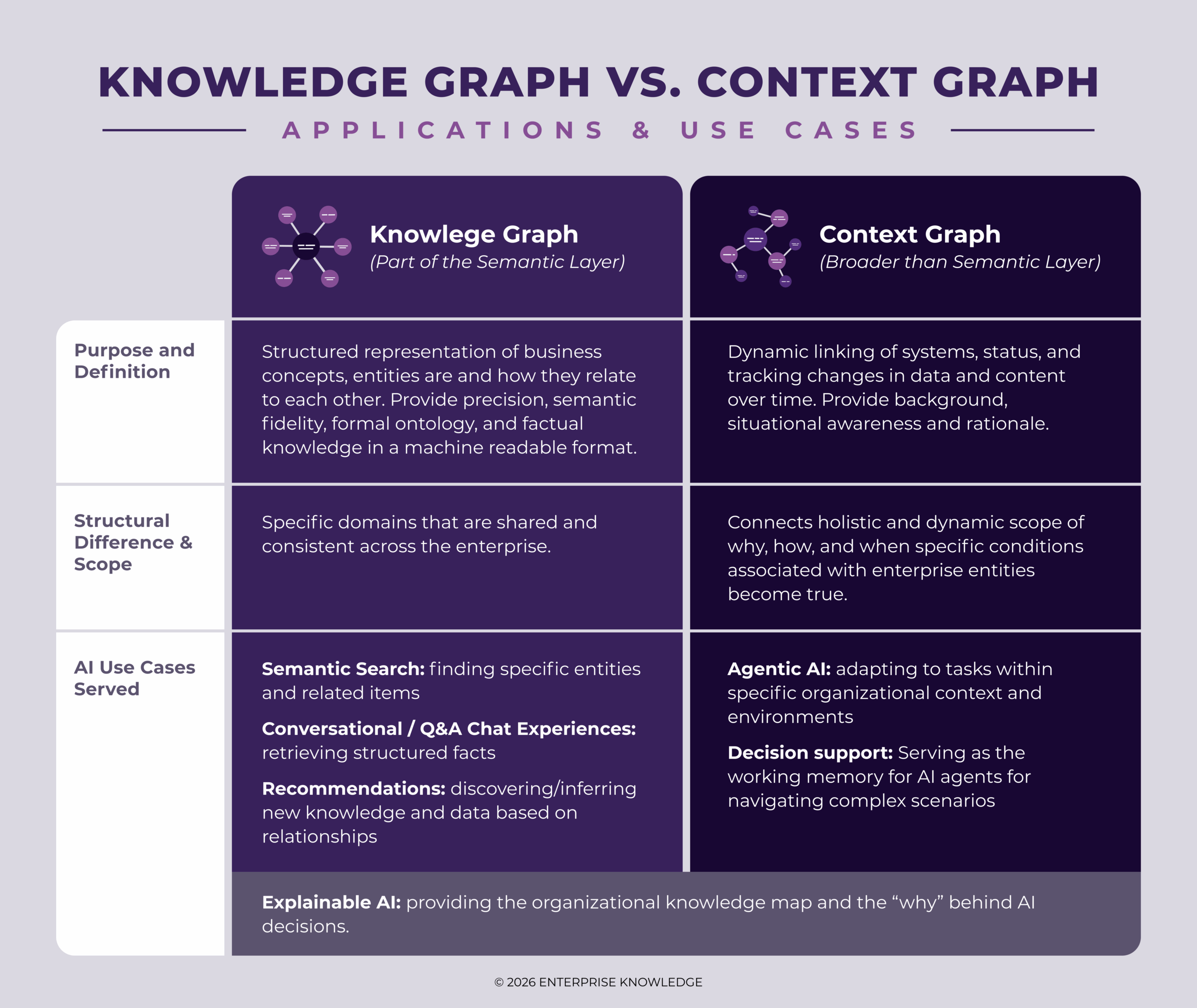
Over the last decade, there have been significant strides and successes achieved through the semantic layer, which provides the structural meaning and context behind data and knowledge. It primarily plays the role of the connector of enterprise knowledge assets across the organization without the need to physically move data. Because a semantic layer framework is built on standard data models such as metadata, taxonomies, ontologies, business glossaries, and knowledge graphs, it supplies the methods for organizing and linking facts and entities within knowledge and data. It does so in both human and machine-readable formats, making the semantic layer even more essential as enterprise AI continues to mature from experimentation to production.
Today, generative AI (GenAI) and AI agents are adding further complexity by expanding the role of knowledge and data efforts to tackle tasks that require autonomous reasoning. Unlike the deterministic content and data management tools of the past that operate based on predetermined code and schema rules, LLMs and AI agents are “probabilistic,” meaning they are good at making up answers and executing tasks without a native understanding of facts or truth, time, or organizational boundaries. This means GenAI solutions and AI agents require embracing solutions that can autonomously answer sophisticated questions like, “Why is revenue down, and what should we do about it?” in a reliable format. This shift from “finding data” to “reasoning and understanding context” is the driver for a more robust context layer that needs to provide the operational nuances that are typically locked within systems, teams, and organizational silos. This additional context includes operational and dynamic context, such as user profile information (roles, access rights, and responsibilities), task or workflow context, instructions and guardrails for AI systems, and business rules or policies.
| The semantic layer serves as an interpreter that provides facts, standard terminology, definitions, and relationships between knowledge and data assets, but it does not capture the full picture of how that information is actually used in real time. The semantic layer’s added context helps AI solutions understand not only what the data means, but also how it should be interpreted and applied in different scenarios and circumstances. |
| A Context Layer, therefore, acts as a broader, multidimensional operational map that integrates the structured components of a semantic layer (such as a knowledge graph) with dynamic contextual information (through a context graph), capturing changing, temporal relationships, user interactions, operational patterns, and agentic behaviors/actions that traditional schemas typically overlook. |
Together, these interpretation and context frameworks provide a mechanism to capture organizational knowledge and reasoning about data, serving as the organizational lens through which AI sees your data and business. In practice, this allows AI solutions to go beyond static data schemas and adapt to changing users, tasks, and environments, reflecting real-world organizational operations.
Context Layer and Semantic Layer: Components and Use Cases
Within an effectively architected context layer, standard data modeling components do not operate in silos. Instead, they create a complementary feedback loop where the semantic layer provides the structural rules and organizational meaning, and additional context is provided through temporal data, event logs or triggers, and historical/operational knowledge in order to form an explainable action. Connect this additional context, and you will have a context graph that is grounded in real-world entities and shared semantics.
A clear understanding of the roles each of the components plays within a context layer (and how they build on one another) helps you avoid overengineering while still making the right, targeted investments. Instead of asking, “Do we need all of this?”, the better question becomes, “What do we need to support our use cases, and what can we grow into over time?” Below is a practical use case example to help you think about how semantic and context layer components interact with each other, from foundational elements to more advanced capabilities, to make informed design decisions.
Real World Use Case: Semantic & Context Layer for Investment Evaluation and Due Diligence Agents
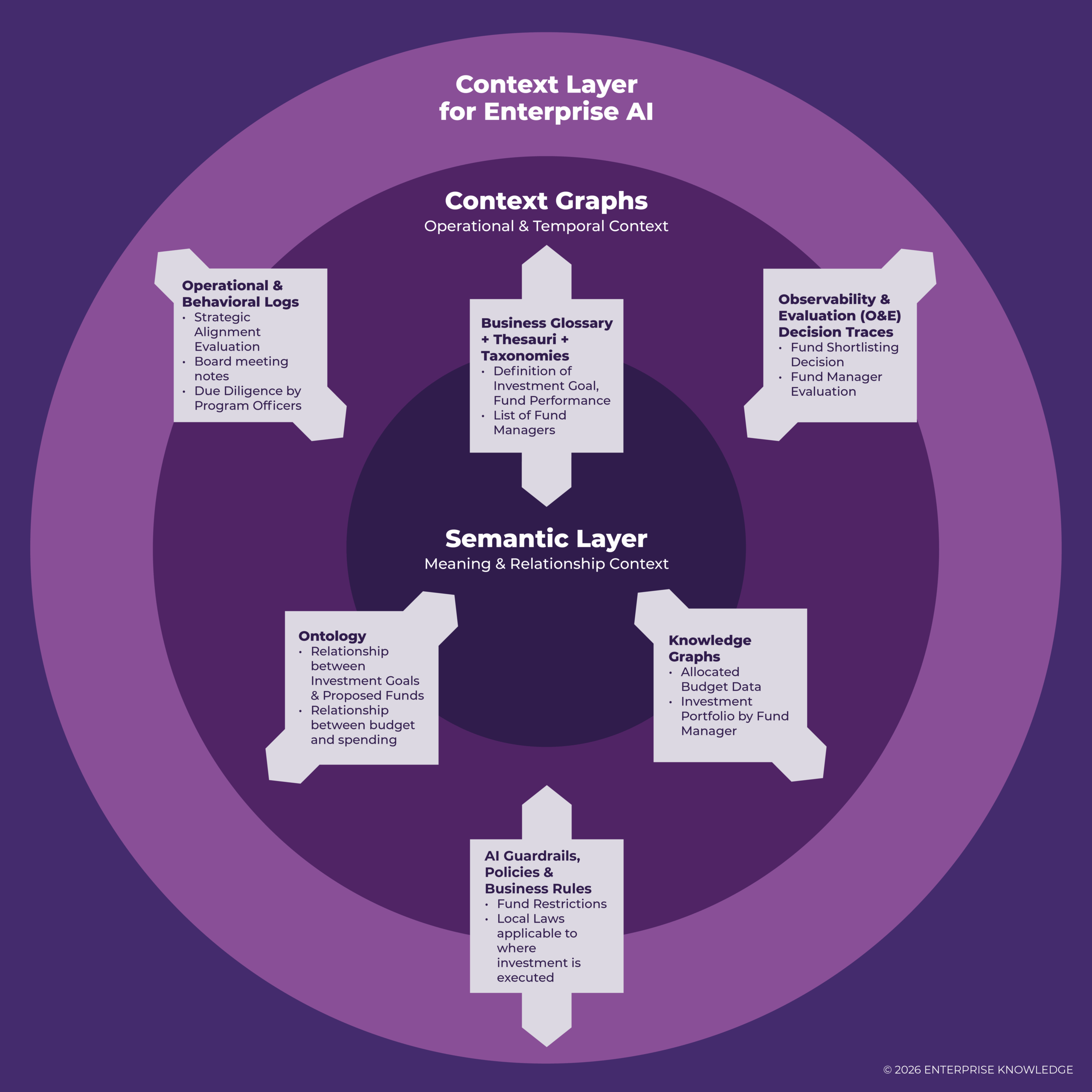
Let’s use one of the most common use cases in fund management, an investment team evaluates whether to increase investment position in a given company, to serve as a worked example.
The semantic layer provides shared meaning and defines the core financial concepts everyone is using. For example,
- What counts as “Revenue”;
- What defines an investment goal;
- The related investments in the company’s industry/sector, etc.
The context graph layer adds real-time data, behavior, and operational signals and explains what is happening around the data and how to act on it. For example,
- Temporal context: longitudinal or time-series analysis, such as investment evaluation and growth over the last three quarters;
- Operational context: sales pipeline status, contracts under negotiation, etc.;
- Behavioral context & O&E Decision Traces: meeting notes from past investment decisions.
So when an investment analyst asks, “What are the fund’s investment goals or investment performance?”, humans, data dashboards, and AI agents are using the same definition, inputs, and calculations to get to the right answer. To make this even more tangible, consider this with agentic AI. Instead of just reporting on these items, AI agents supporting this use can suggest a specific decision or action, such as “Given recent fund manager evaluations on performance and local regulatory challenges, consider delaying investment until two quarters of stabilization.”
Designing The Context Layer
The bottom line is that there isn’t a single product that is the context layer. Although tools in the semantic layer and metadata management space have matured a lot over the past decade, moving from semantics to an AI-ready “context layer” requires more deliberate design, including addressing access, security, interoperability, and governance across the enterprise ecosystem.
Right now, the context layer product market is expanding quickly, but also fragmenting. As many promising platforms are beginning to address the challenge of managing and orchestrating context for AI, the need for shared standards is becoming obvious. Standards, for example, around how context, metadata, relationships between assets, lineage, policies, and operational data can move across systems rather than stay confined to one tool. In earlier eras of IT and big data, we’ve seen what happens when this goes the other way.
Today, the industry is still early in figuring out what the “context layer” of the modern data stack should really look like, and where it should live to effectively support AI agents that don’t understand these legacy boundaries to execute tasks (without the right context that is). One thing forward-thinking organizations are already clear about is that the context layer can’t become just another standalone platform. For it to work, it will need to evolve toward more open, interoperable frameworks that work across the broader data and AI ecosystem. The real challenge will be making sure to expand this capability without recreating the next generation of monolith platforms and vendor lock-in.