
Information models like taxonomies and ontologies are rarely built independently, and they are never static. At EK, knowledge engineers partner with clients to build these models through an iterative process of design, validation, and implementation. The models that come out of this process are in a constant state of change, especially those that power dynamic semantic solutions like knowledge graphs and data fabrics. How can we effectively govern these changes without limiting the pace of development? For a trusted approach to managing change, we can take inspiration from a bedrock of software engineering: version control.
How Is Version Control Relevant to Knowledge Engineering?
Version control was designed with a simple goal in mind: to help teams of developers track changes to complicated code projects. Over the years it has become standard practice in most development environments. Though it originated in software engineering, version control is broadly applicable to any environment where rapid iteration and experimentation are the norm. Increasingly, disciplines like design, manufacturing, and data science are adopting version control systems to manage their work.
There are clear parallels between software and knowledge engineering. Ontologies and taxonomies are serialized in common text and data formats, just like software code. Information modeling teams work iteratively, using the same Agile approaches that were refined in the engineering environment, and they strive to design models that are flexible and modular, so they can expand to meet new business use cases. Both software engineering and information modeling teams are naturally collaborative and cross-functional, with team members of varying expertise contributing across domains.
Given the similarities between the two environments, it is not surprising that software and knowledge engineers face similar challenges. With so much rapid change, it can be difficult to know which version of a file is most recent or who worked on what feature, or to handle common workflow issues like integrating changes and managing feature requests. Modeling teams need a system that organizes and streamlines the continuous flow of changes to their models so they can work harmoniously with as little friction as possible. Fortunately, software teams have already worked out a tried-and-tested methodology to address these issues, and this approach can be easily adapted to an information modeling context.
Benefits of Version Control
Version control is an approach to tracking and managing changes to complex projects. Version control systems (VCSs) actualize version control into software like Git or SVN. Though the features vary by system, most VCSs have the following core components.
Traceability

The bread and butter of any VCS is tracking changes to project files, down to the user, time, and rationale for the change. Every time a user saves the state of the project via a commit, the VCS makes a snapshot of the project files. Let’s say an ontologist adds new axioms to an ontology that end up creating unexpected side effects when the reasoner is run. With a VCS, the ontologist can inspect a line-by-line history of each change to the ontology, and if necessary, revert back to an earlier state before the errors were introduced.
Branching and merging
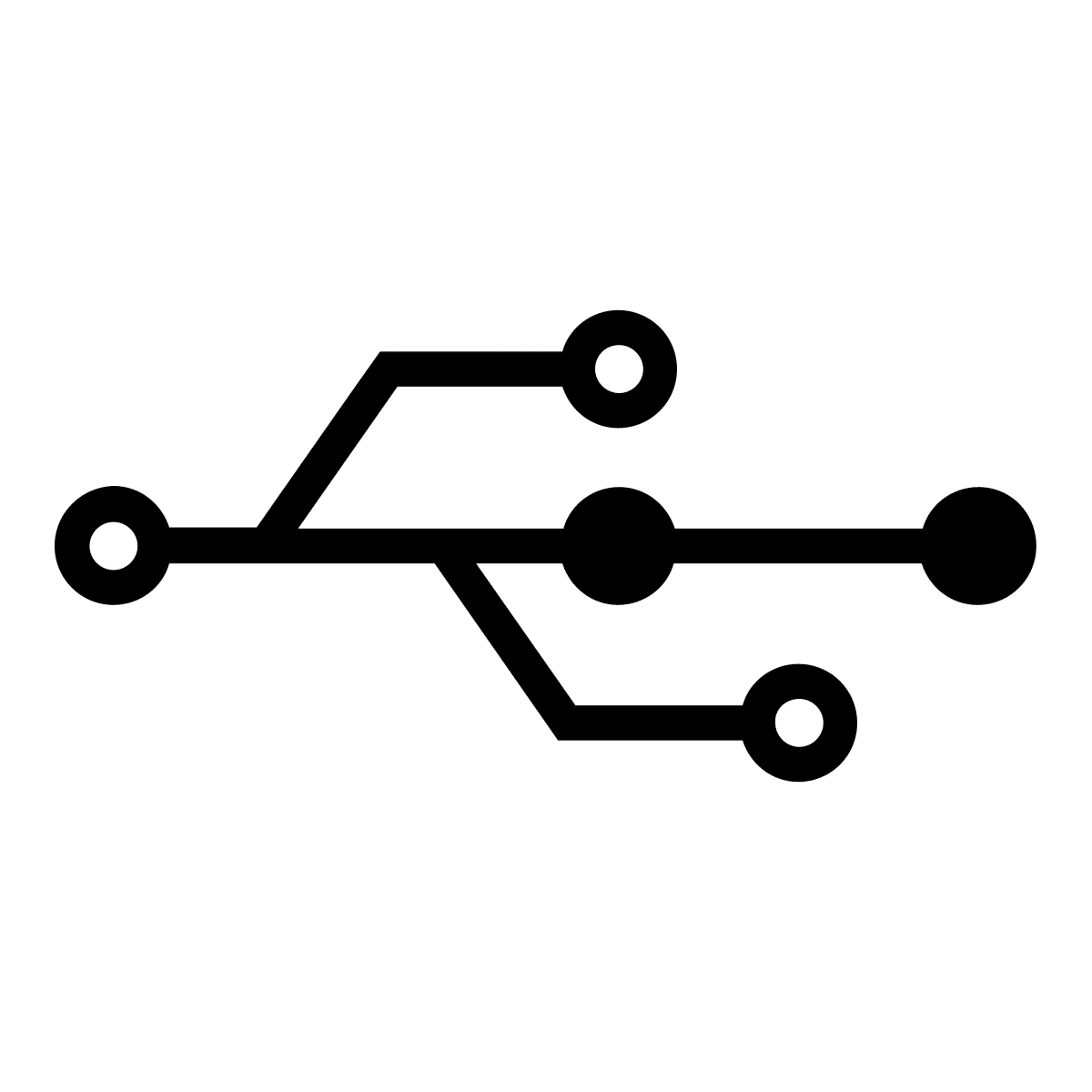
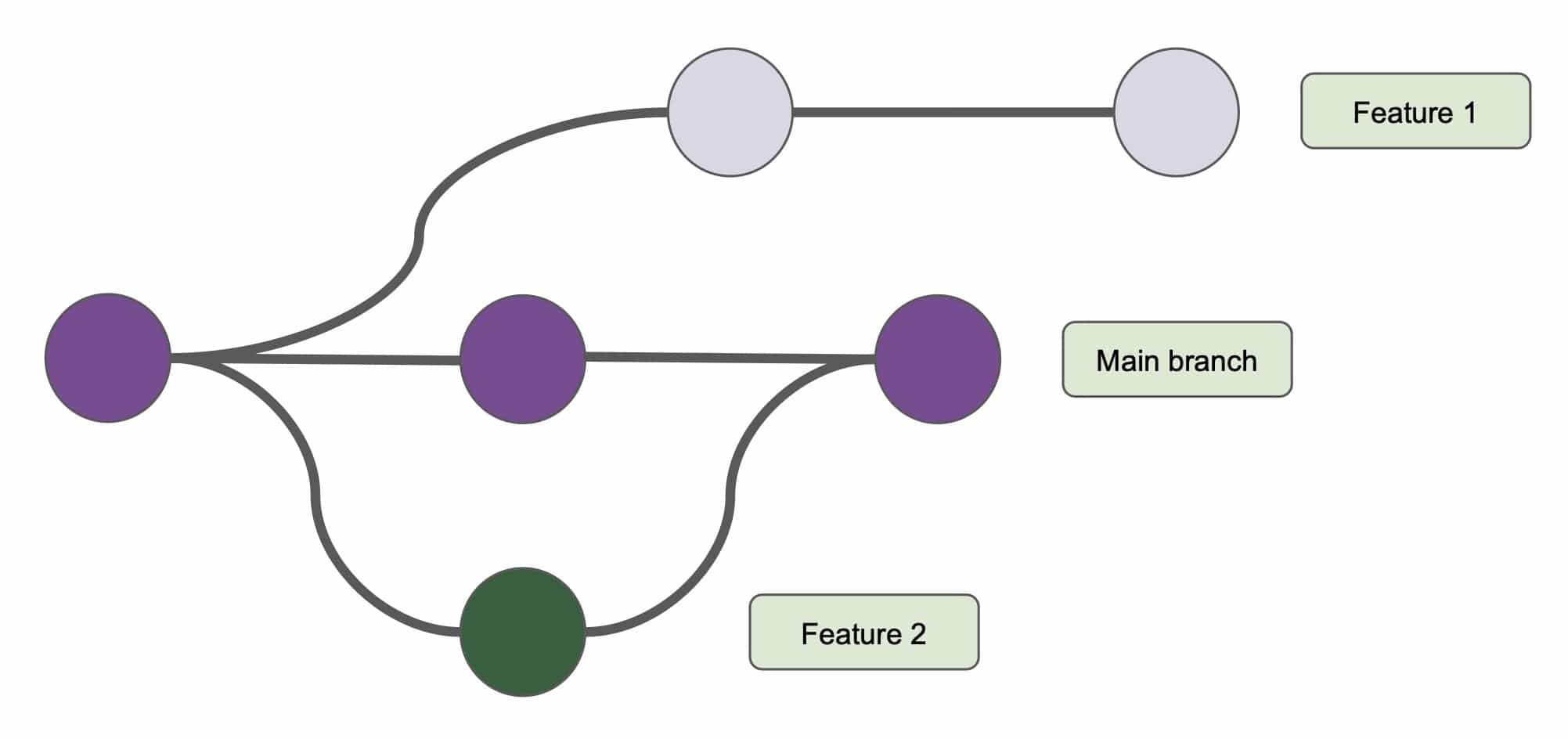
Branching allows users to create isolated copies of a project to work on without impacting the main project files. Let’s say an ontologist wants to attempt to extend an ontology by linking it with external data from DBpedia. With version control, they can create an independent copy of the main ontology called a branch to use for testing. If the integration is successful, they can merge the changes into the main branch. If the experiment fails, they can simply delete the branch. There is no limit to the number of active branches, so the ontologist can work on an entirely different area of the ontology without impacting other branches. Branching and merging allow for multiple simultaneous lines of development, facilitating faster, more efficient workflows.
Conflicts

Sometimes, when multiple users have made changes to the same lines of a file, a conflict occurs. For example, two taxonomists might get their wires crossed and add incompatible terms to the same area of a taxonomy. A VCS will highlight these conflicts and provide a way for the taxonomists to accept or reject the changes on a line-by-line basis. This prevents users from overwriting or mistakenly changing each other’s work.
Context

Version control can provide valuable information about the evolution of a model. Let’s say a consultant wants to understand her team’s process for developing a new section of an ontology. In addition to tracking changes to files, most version control systems require contributors to include commit messages that describe the nature of those changes each time they create a snapshot. The consultant can investigate this commit history, together with changes to the model itself, to learn valuable context about how that section of the ontology was assembled.
Approaches to Version Control
Git
Among the version control systems, Git is by far the most widely adopted. It’s extremely powerful, flexible, and (relatively) easy to use. Git was designed to track text-based files, including common information model data formats like RDF and XML. It is completely system-independent, so it can be used in conjunction with your preferred ontology or taxonomy management system (more on that later).
Git can be used on its own, but it is frequently paired with GitHub, a cloud-based hosting service for Git projects (aka repositories). GitHub provides a friendly web interface for sharing and publishing code, and it integrates seamlessly with Git for those who prefer to use the command line. Many ontology developers use GitHub as a platform to share their models and collaborate with users and contributors, and it is also possible to set up a private repository for closed ontologies.
Git has all of the VCS core features, plus a lot more. Git allows users to configure specific actions called hooks to take place before a file is committed, so ontology developers can set up their logic and consistency checks to happen automatically each time they release a version. Git can also track ancillary files like design documentation alongside the main code. This way, all the relevant files are stored and shared together in a single location.
Of course, there are downsides to using Git for knowledge engineering projects – keep in mind that it was not designed to manage ontologies! For one, Git tracks every modification to a file, even minor syntactic changes like removing a comma. If you are not careful about limiting cosmetic edits, it can be quite difficult to identify and interpret just the substantive changes to the model. Another potential drawback is that Git does not do a good job of handling binary files, so changes to certain files like graph visualizations or Word documents will not be tracked.
Taxonomy and Ontology Tools
Though few of them offer the feature depth and maturity of Git, many ontology and taxonomy management systems offer limited version control functionality out of the box. As you would expect, it’s quite convenient to use the version control features native to your ontology development environment, and many vendors have made version management a priority in recent years. Below are a few examples.
WebProtégé, the cloud-based version of Stanford’s popular ontology development tool, has Git-like version control functionality packaged in a friendly user interface. Ontology developers can collaboratively edit ontologies in real time via a group editing panel that neatly illustrates a detailed revision history, and all changes are visible via a project feed. As in Git, changes are tracked and grouped into snapshots that can be rolled back if needed.
PoolParty Semantic Suite, the powerful set of tools for integrating knowledge models into databases and front-end systems, offers a workflow process for managing change to taxonomies and ontologies. Administrators can set up a workflow by which users can submit terms for inclusion in a scheme, and others can approve, dismiss, or deprecate terms. Group editing is tracked and tied to each users’ individual account, and PoolParty keeps detailed user logs and an audit log of all of the “events” associated with a project. PoolParty also supports semantic versioning, the formal convention for naming the versions of model releases.
The ontology development tool TopBraid EDG offers a robust set of change management features. All revisions are logged by default and can be accessed via a dedicated change history pane that allows users to filter changes by user, date, or element. It is possible to “undo” changes in batches. Like PoolParty, EDG allows users to set up approval workflows in the interface. EDG is one of the few systems with a Git integration that allows users to interact with a Git repository from within the ontology interface.
Even when these tools stand on their own, it is considered best practice to store copies of your models outside of their technology stack to guard against system failure. Many knowledge engineering teams pair the version control in their ontology editor with a VCS like Git that can act as a backup and a sharing platform. An added benefit is when they need to migrate from one system to another, they have their models stored in a system-independent location. This hybrid approach allows them to streamline the model development process inside their tool of choice while enjoying the added capabilities of a dedicated VCS.
Summary
Version control is a critical pillar of any information model governance strategy. Core features like traceability, branching, and sharing can help knowledge engineering teams create and manage models that can scale in any environment. With a little bit of planning, it is possible to translate practices from software version control to the knowledge engineering space and transform the way you manage your models. For help getting started, contact us!