
Our clients often assume that building a knowledge graph requires that all data be managed in a single place for it to be effective. That is not the case. There are a variety of ways that organizations can solve for their knowledge-first and relationship-based use cases while maintaining aspects of their existing data architecture. In this way, graph data is not a “one size fits all” solution. The spectrum of leveraging graph data models spans from using a graph database as the primary data storage to using an ontology model as the blueprint for a relational data schema.
Graph Database as Primary Storage: All data and ontology is stored within the graph database, ingesting all relevant source data and enabling inference and reasoning capabilities.
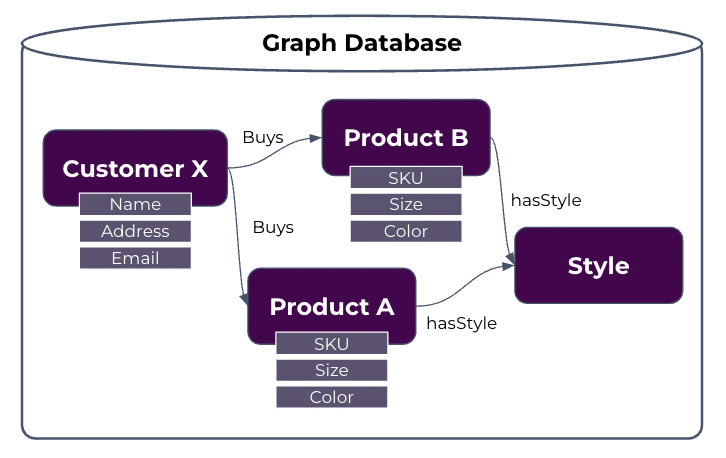
Graph Database as Relationship Management and Taxonomy Integration: Relationships between core concepts and content metadata (like taxonomy tags on documents) are stored within the graph, but actual content and descriptive metadata are stored within other systems and are connected to the graph via virtualization.
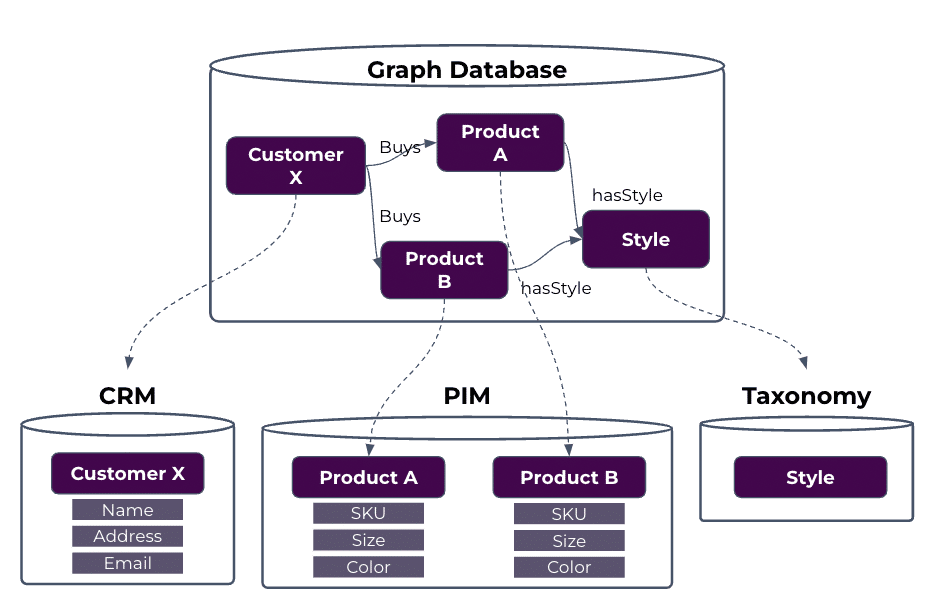
Graph Data Model (Ontology) as Relational Data Schema: The ontology model is an Enterprise Relational Diagram (ERD) that sets the “vision” for how to connect and leverage data stored in a relational database.
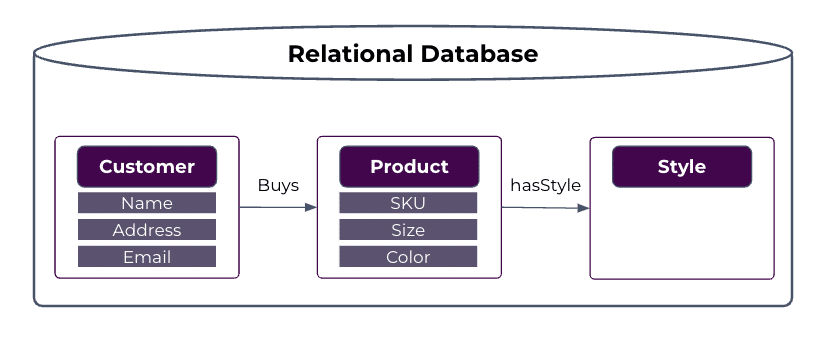
Organizations can see the value of capturing relationships in a machine-readable way, even when not all of the data relevant to the use case is captured in a graph database. The model that makes sense for your organization and your use case is dependent on factors including:
- Restrictiveness of source data systems;
- Volume and scale of data;
- Enterprise architecture maturity;
- Inference and reasoning needs; and
- Integration needs with downstream systems.
At EK, we design graph-based architectures in a way that leverages your organization’s specifications and conventions, while introducing best practices and standards from the industry. Looking to get started? Contact us.