
RDF* (pronounced RDF star) is an extension to the Resource Description Framework (RDF) that enables RDF graphs to more intuitively represent complex interactions and attributes through the implementation of embedded triples. This allows graphs to capture relationships between more than two entities, add metadata to existing relationships, and add provenance information to all triples, reducing the burden of maintenance.
But let’s back up…before we talk about RDF*, let’s cover the basics — what is RDF, and how is RDF* different from RDF?
What is RDF?
The Resource Description Framework (RDF) is a semantic web standard used to describe and model information for web resources or knowledge management systems. RDF consists of “triples,” or statements, with a subject, predicate, and object that resemble an English sentence.
For example, take the English sentence: “Bess Schrader is employed by Enterprise Knowledge.” This sentence has:
- A subject: Bess Schrader
- A predicate: is employed by
- An object: Enterprise Knowledge
Bess Schrader and Enterprise Knowledge are two entities that are linked by the relationship is employed by. An RDF triple representing this information would look like this:

(There are many ways, or serializations, to represent RDF. In this blog, I’ll be using the Turtle syntax because it’s easy to read, but this information could also be shown in RDF/XML, JSON for Linking Data, and other formats.)
The World Wide Web Consortium (W3C) maintains the RDF Specification, making it easy for applications and organizations to develop RDF data in an interoperable way. This means if you create RDF data in one tool and share it with someone else using a different RDF tool, they will still be able to easily use your data. This interoperability allows you to build on what’s already been done — you can combine your enterprise knowledge graph with established, open RDF datasets like Wikidata, jump starting your analytic capabilities. This also makes data sharing and migration between internal RDF systems simple, enabling you to unify data and reducing your dependency on a single tool or vendor.
For more information on RDF and how it can be used, check out Why a Taxonomist Should Know SPARQL.
What are the limitations of RDF (Why is RDF* necessary)?
Standard RDF has many strengths:
- Like most graph models, it more intuitively captures the way we think about the world as humans (as networks, not as tables), making it easier to design, capture, and query data.
- As a standard supported by the W3C, it allows us to create interoperable data and systems, all using the same standard to represent and encode data.
However, it has one key weakness: because RDF is based on triples, standard RDF can only connect two objects at a time. For many use cases, this limitation isn’t a problem. Consider my example from above, where I want to represent the relationship between me and my employer:
Simple! However, what if I want to capture the role or position that I hold at this organization? I could add a triple denoting my position:

Great! But what if I decide to add in my (fictional) employment history?
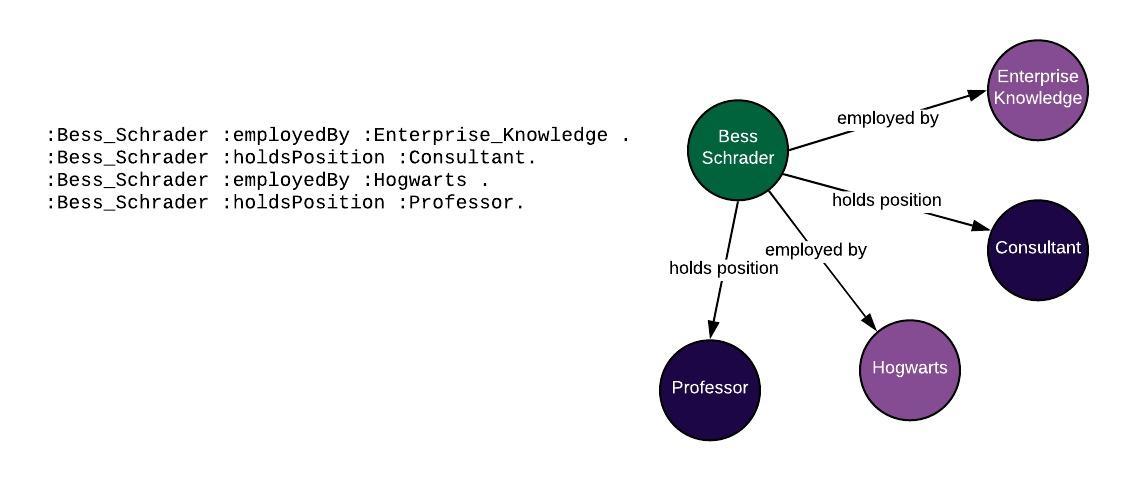
Now it’s unclear whether I was a consultant at Enterprise Knowledge or at Hogwarts.
There are a variety of ways to address this problem in RDF. One of the most popular is reification or n-ary relations, in which you create an intermediary node that allows you to group more than two entities together. For example:
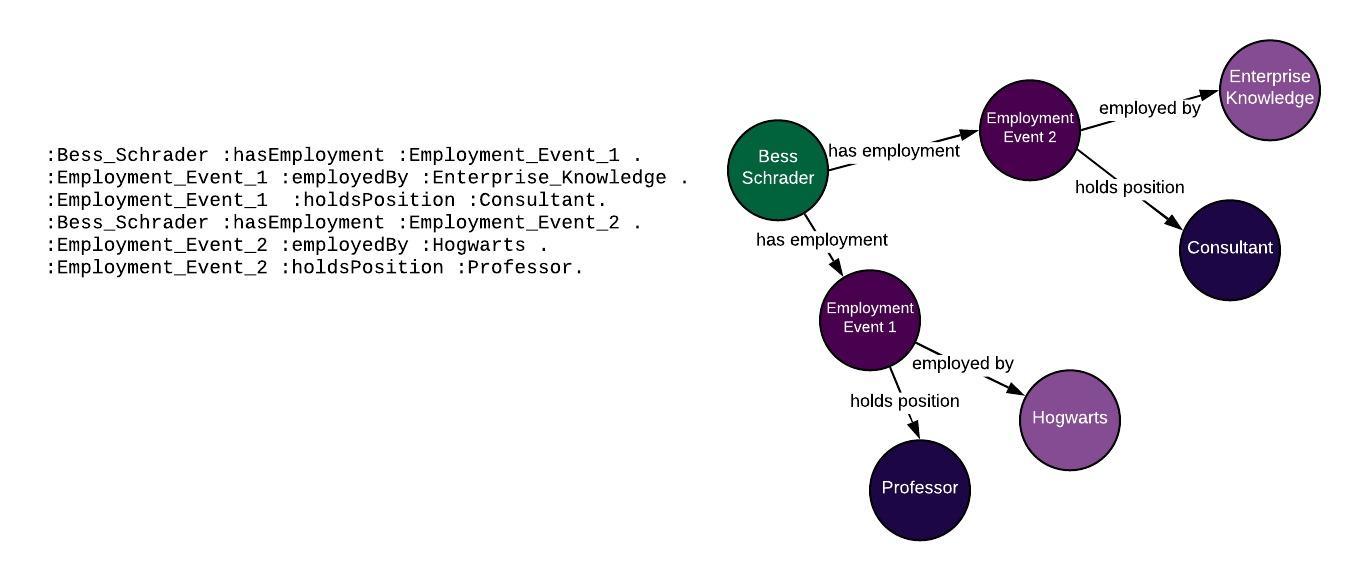
Using this technique allows you to clear up confusion and model the complexity of the world. However, adding these intermediary nodes takes away some of the simplicity of graph data — the idea of an “employment event” isn’t exactly intuitive.
There are many other methods that have been developed to handle this kind of complexity in RDF, including singleton properties and named graphs/quads. Additionally, an entirely different type of non-RDF graph model, labeled property graphs, allows users to attach properties directly to relationships. However, labeled property graphs don’t allow for interoperability at the same scale as RDF — it’s much harder to share and combine different data sets, and moving data from tool to tool isn’t as simple.
None of these solutions retain both of the strengths of RDF: the interoperable standards and the intuitive data model. This crucial limitation of RDF has limited its effectiveness in certain applications, particularly those involving temporal or transactional data.
What is RDF*?
RDF* (pronounced RDF-star) is an extension to RDF that proposes a solution to the weaknesses of RDF mentioned above. As an extension, RDF* supplements RDF but doesn’t replace it.
The main idea behind RDF* is to treat a triple as a single entity. By “nesting” or “embedding” triples, an entire triple can become the subject of a second triple. This allows you to add metadata to triples, assigning attributes to a triple, or creating relationships not just between two entities in your knowledge graph, but between triples and entities, or triples and triples. Take our example from above. In standard RDF, if I want to express past employers and positions, I need to use reification:
In RDF*, I can use nested triples to simply denote the same information:

This eliminates the need for intermediary entities and makes the model easier to understand and implement.
Just as standard RDF can be queried via the SPARQL query language, RDF* can be queried using SPARQL*, allowing users to query both standard and nested triples.
Currently, RDF* is under consideration by the W3C and has not yet been officially accepted as a standard. However, the specification has been formally defined in Foundations of an Alternative Approach to Reification in RDF, and many enterprise tools supporting RDF have added support for RDF* (including BlazeGraph, AnzoGraph, Stardog, and GraphDB ). Hopefully this standard will be formally adopted by the W3C, allowing it to retain and build on the original strengths of RDF: its intuitive model/simplicity and interoperability.
What are the benefits of RDF*?
As you can see above, RDF* can be used to represent relationships that involve more than one entity (e.g. person, role, and organization) in a more intuitive manner than standard RDF. However, RDF* has additional use cases, including:
- Adding metadata to a relationship (For example: start dates and end dates for jobs, marriages, events, etc.)
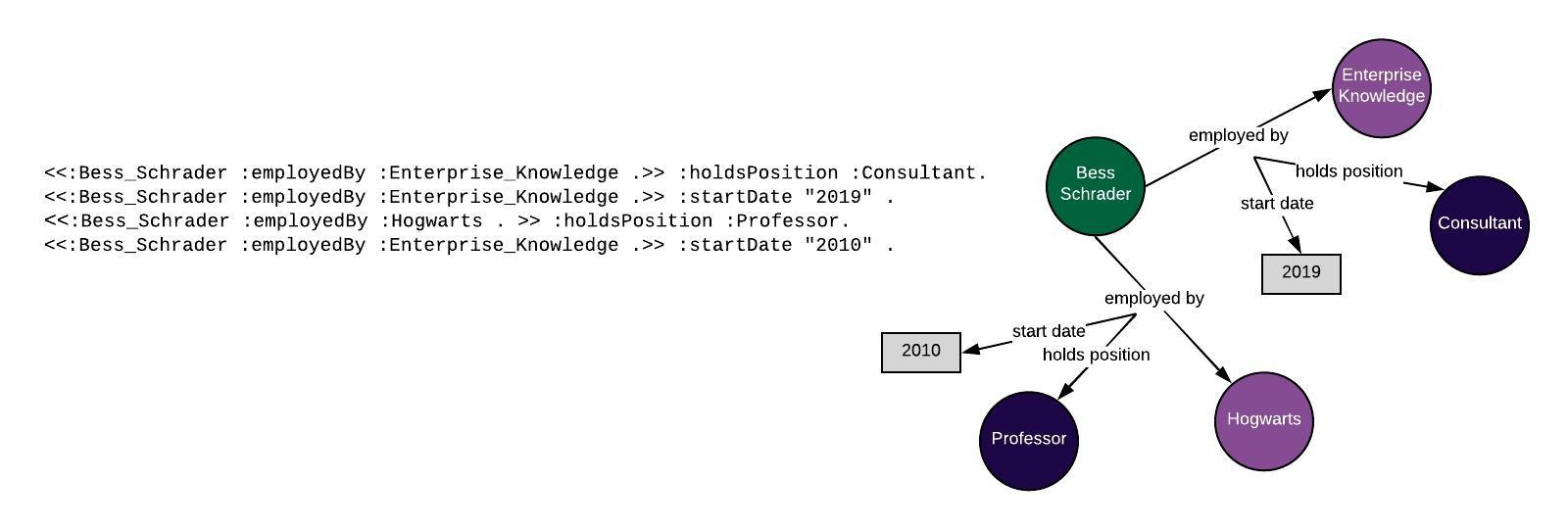
- Adding provenance information for triples: I have a triple that indicates Bess Schrader works for Enterprise Knowledge. When did I add this triple to my graph? What was the source of this information? Who added the information to the graph?

Conclusion
On its own, RDF provides an excellent way to create, combine, and share semantic information. Extending this framework with RDF* gives knowledge engineers more flexibility to model complex interactions between multiple entities, attach attributes to relationships, and store metadata about triples, helping us more accurately model the real world while improving our ability to understand and verify where data origins.
Looking for more information on RDF* and how you can leverage it to solve your data challenges? Contact Enterprise Knowledge.