
As a standardized framework for connecting organizational assets, a Semantic Layer captures organizational knowledge and domain meaning to support connecting and coordinating assets across systems and repositories. Metadata, as one component of a Semantic Layer approach, is foundational.
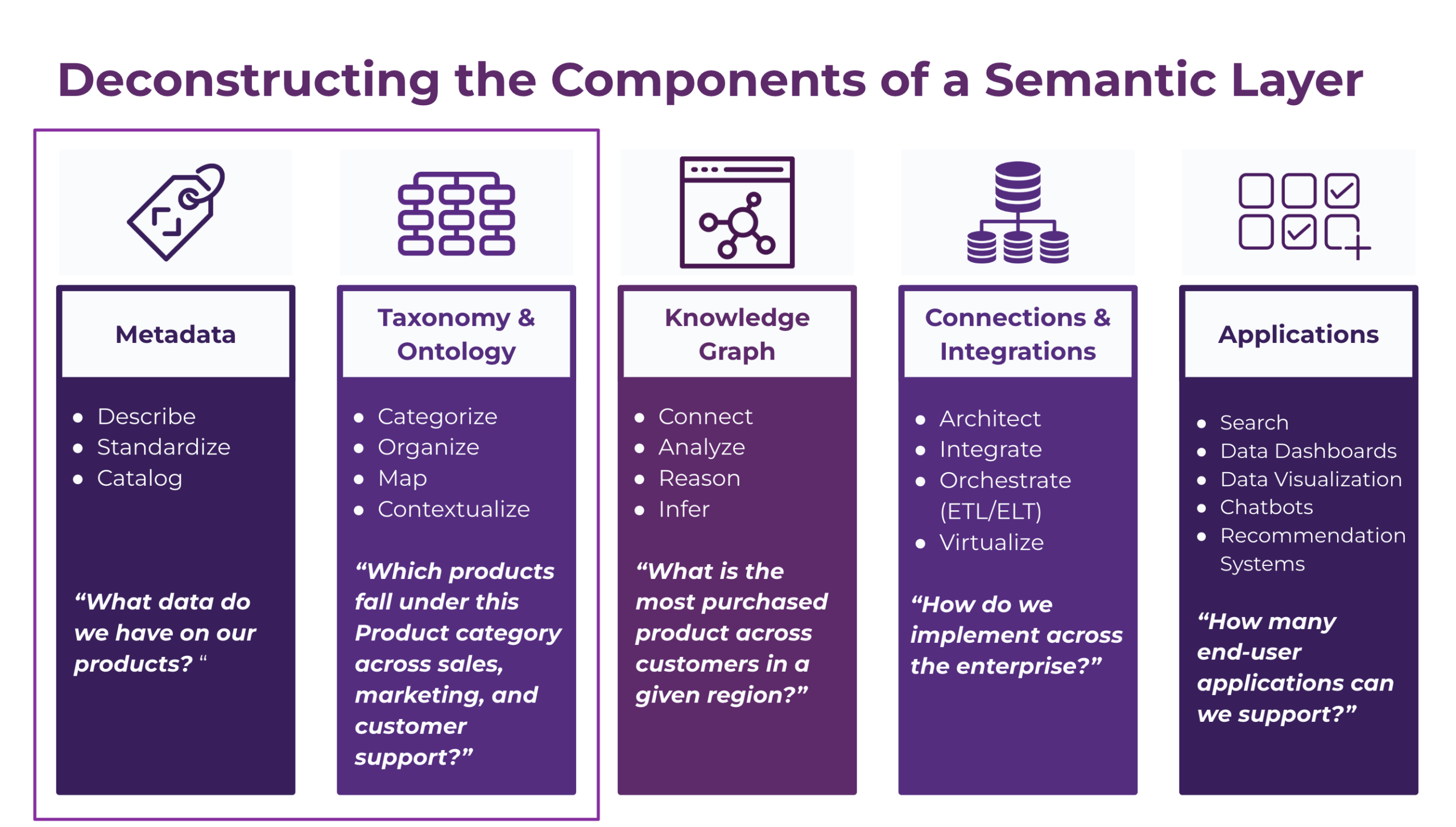
Whether you are striving to enhance user experiences by improving search or navigation, or by improving asset management or reporting, in a single system or across multiple systems—you need metadata.
But not just any metadata. You need metadata that provides the information and context needed to leverage assets effectively and meaningfully.
For those seeking to extend or enhance the metadata for their organizational assets, it can be difficult to ascertain what metadata should be captured. In this blog post, I provide an overview of the role of metadata, and guidance on what to consider when defining metadata.
The Role of Metadata in a Semantic Layer
Metadata codifies characteristics of an asset—what it is about, how it should be managed and used, and what contexts it is relevant for. For example, a document may have metadata to identify its title, publication date, lifecycle status, document type, and topic.
Additionally, metadata should capture actionable characteristics of an asset, reflecting the characteristics necessary for finding, managing, using, and understanding assets. In other words, if the characteristic is used to support a requisite interaction with the asset, it should be captured as metadata.
By codifying actionable characteristics, metadata enables user experiences by providing the connection between a specific asset and supported interactions.
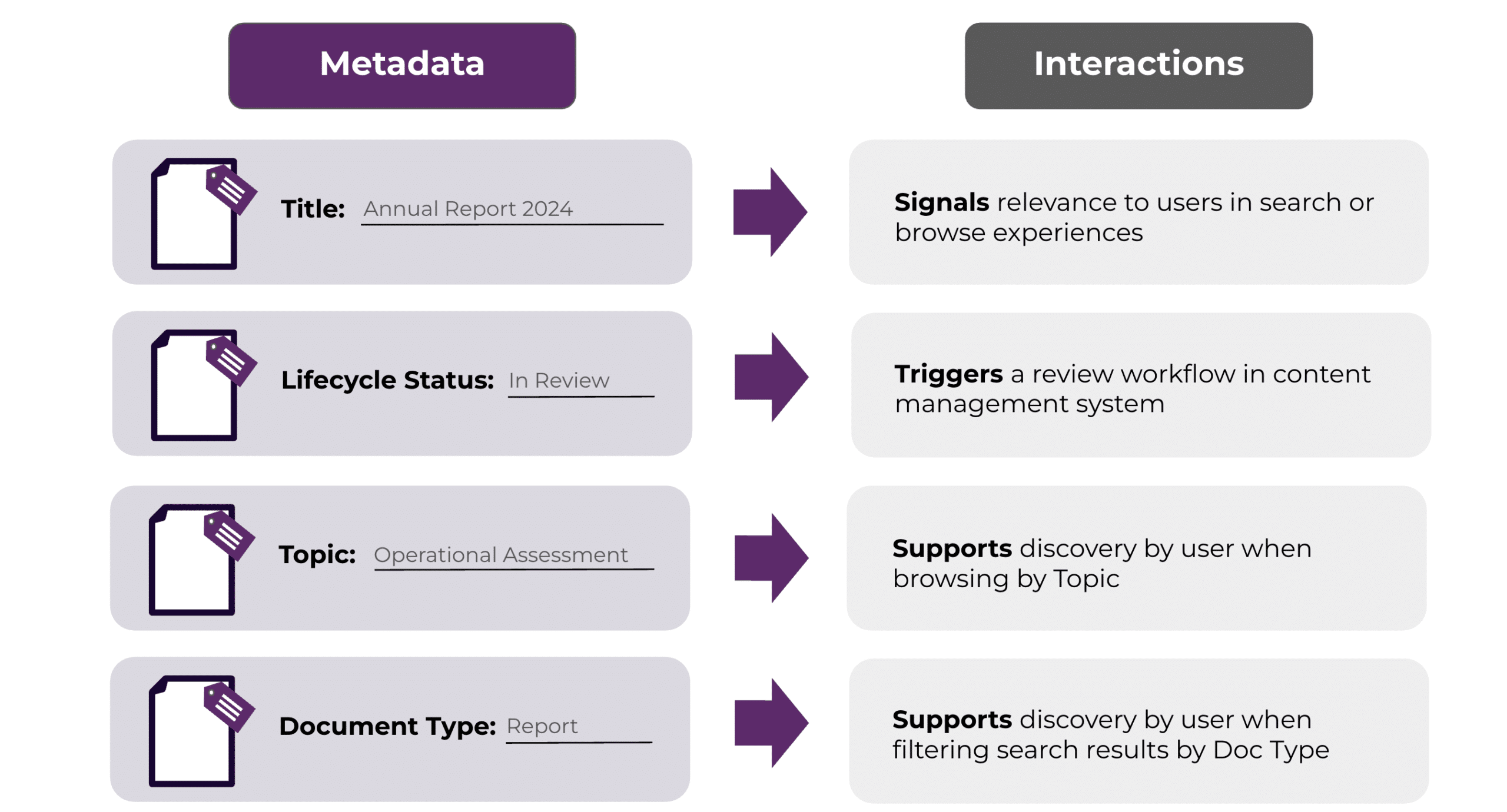
Metadata also enables AI-supported interactions. As an explicit signal of an asset’s characteristics, metadata ensures that AI-powered tools can reference and leverage the asset when appropriate. For instance, a semantic search engine can be tuned to prioritize information in assets marked with specific Document Types, or a content generation tool can be directed to summarize the most recent, published assets on a topic.
The utility of metadata is limited by any differences in its definition or application. If different terms are used to identify the same topic, it is more difficult to identify assets that are about the same, or related, topics. Similarly, if a topic is applied inconsistently—missing on relevant assets or present on irrelevant assets—it is more difficult to identify similar or related assets.
This underscores the importance of standardizing metadata. To ensure concepts, like dates and topics, are identified and applied consistently, metadata should be defined as a shared representation; that is, characteristics common to assets across systems should share the same metadata definition, and common concepts, like topics and document types, should be standardized with a taxonomy. This approach controls what data should be captured for an asset and what terms can be used to identify concepts, helping to enforce a shared representation across assets.
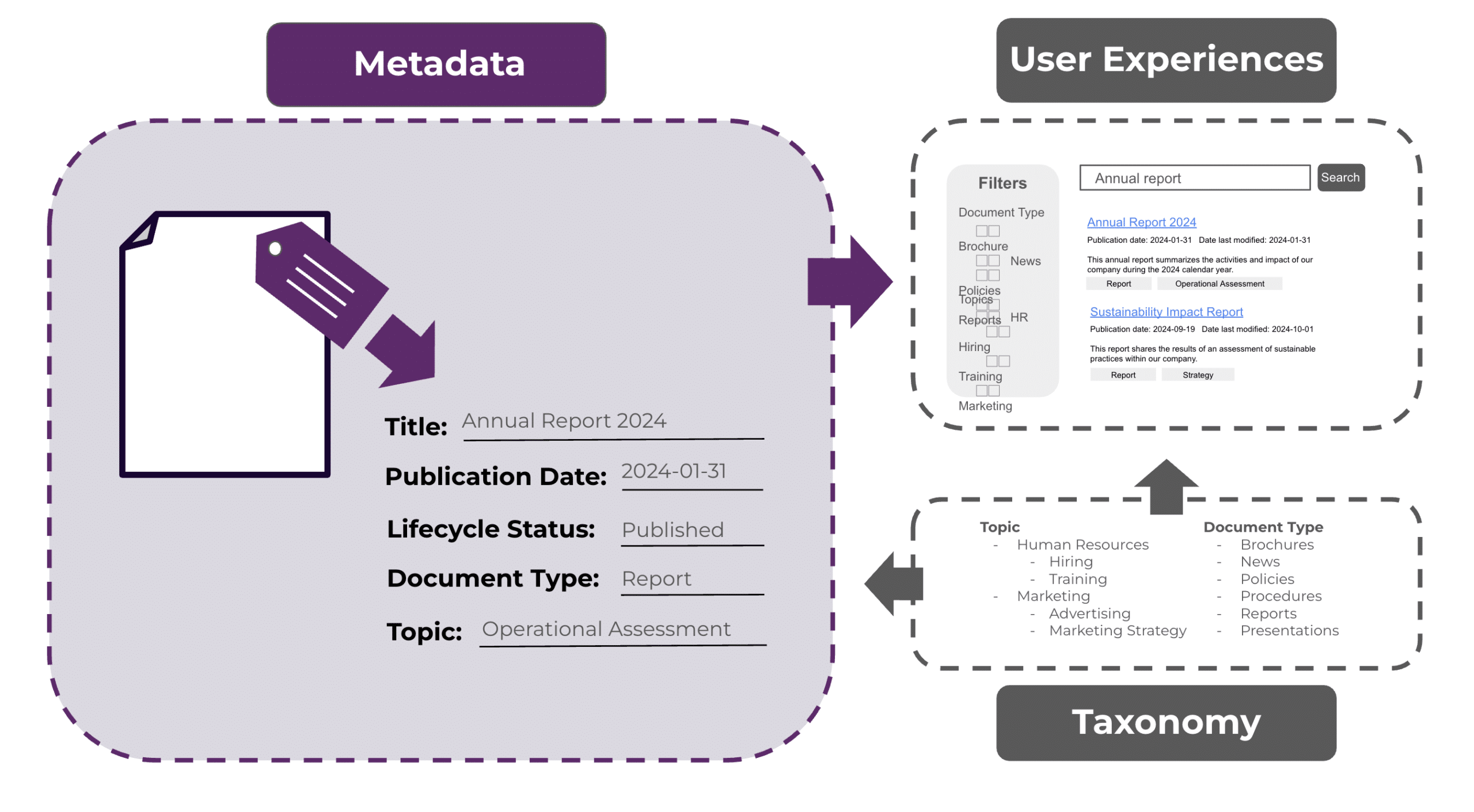
When metadata is standardized, it is possible to improve user experiences, such as improving asset discovery within a repository via a common metadata definition and taxonomy or across repositories by establishing a metadata knowledge graph.
How to Define Metadata for a Semantic Layer
The process for defining metadata within your organization may look different, depending on what metadata, taxonomies, or other Semantic Layer components you already have in place. There are fundamental considerations, however, that can be useful regardless of what you have in place to date. These include:
- Determining use cases: Consider what specific use cases you need to support. This will help you focus on the metadata that will be most actionable and impactful. Look to your users to understand what their tasks are and what pain points they have, like finding documents for research or identifying data sets for reporting.
- Identifying metadata fields: Investigate the ways users describe, look for, or interact with the assets for the use cases you’ve identified. Consider the different kinds of information and context that may be required to support the use cases.
- Allocating metadata fields: Consider which assets and systems will need to use the metadata field. Identify metadata fields that are applicable to all assets on all (in-scope) systems or some assets on all (in-scope) systems. These metadata fields will be the focus for standardization.
- Standardizing metadata fields: Establish definitions for each metadata field and ensure those definitions can be upheld across in-scope systems. Specify the role of each field, the type of data they capture, and, if applicable, whether they accommodate single or multiple values. For metadata fields that leverage a controlled list of terms, design taxonomies to further standardize and enrich the capture of information and context.
Importantly, you don’t have to define all the metadata all at once. These considerations can be applied to a specific, priority use case to start, then revisited and expanded as needed. Even a small initial set of metadata can help transform user experiences.
Contact us if you are grappling with how to define and standardize your metadata, or are interested in learning more about the Semantic Layer.