
It has been over three years since OpenAI, an artificial intelligence research company, introduced ChatGPT in November 2022. While artificial intelligence has existed for decades prior, this release and development of Generative AI (GenAI), large language models (LLMs), and their impact on enterprises has been especially wide-reaching, making AI a topic from boardrooms to dinner table conversations.
Some organizations were well-positioned to quickly embrace this opportunity from the onset. These early adopters share two key traits: 1) they have already built strong technical foundations, such as modern cloud infrastructures and composable architectures, and 2) they have invested in robust knowledge and data management practices, enabling them to effectively integrate and operationalize their GenAI pilots. For many others, however, the path to AI adoption has been far less straightforward. Challenges like poor data quality, missing business context, access and entitlement concerns, limited resources, and a shortage of AI expertise continue to slow real progress. On top of that, leaders feel increasing pressure to “do something with AI,” only to discover that aligning initiatives to actual business needs, while navigating fragmented data and deeply entrenched legacy systems, is far more complex than expected. For many, that reality has taken the shine off the hype and replaced it with a sense of frustration and caution.
| Early AI efforts, often led by technical teams, have stalled in “PoC purgatory.” By the end of 2025, Gartner predicted that at least 30% of efforts will be abandoned after proof of concept, and nearly 50% will go unused – citing poor data quality, weak knowledge foundations, and unclear business value alignment. |
A key reason behind the struggles many organizations face lies in the absence of a proper framework and standardized approaches for organizing and interpreting the vast array of knowledge assets within their business context. The lack of a common language or shared understanding across organizational content and data is the main culprit, leading to inefficiencies, misinterpretations, and suboptimal outcomes. This disconnect between AI technology and the intricacies of a company’s data ecosystem is one of the most common causes of the wave of innovation for new AI startups. It is inspiring a new surge in creativity and momentum, pushing organizations to recognize that the key to unlocking long-term impact lies in how their organizational context, structure, and operating models evolve around it.
Now more than ever, organizations are seeking AI solutions that deliver real-world results, not just impressive demos. Forward-thinking teams are focusing on the “AI readiness” of their knowledge assets and operating models before technology. In breaking down silos between knowledge, data, content, and engineering, they are creating integrated structures that accelerate AI readiness and adoption while grounding innovation within the enterprise context. A key, vendor-agnostic approach to help organizations take practical steps to ready assets for AI (no matter their technical maturity) is the semantic layer framework. This includes well-defined metadata, taxonomies, ontologies, business glossaries, and graph solutions that, for decades, have provided the standards and proven methods for organizing knowledge and data while enabling companies to separate their core knowledge assets from specific applications.
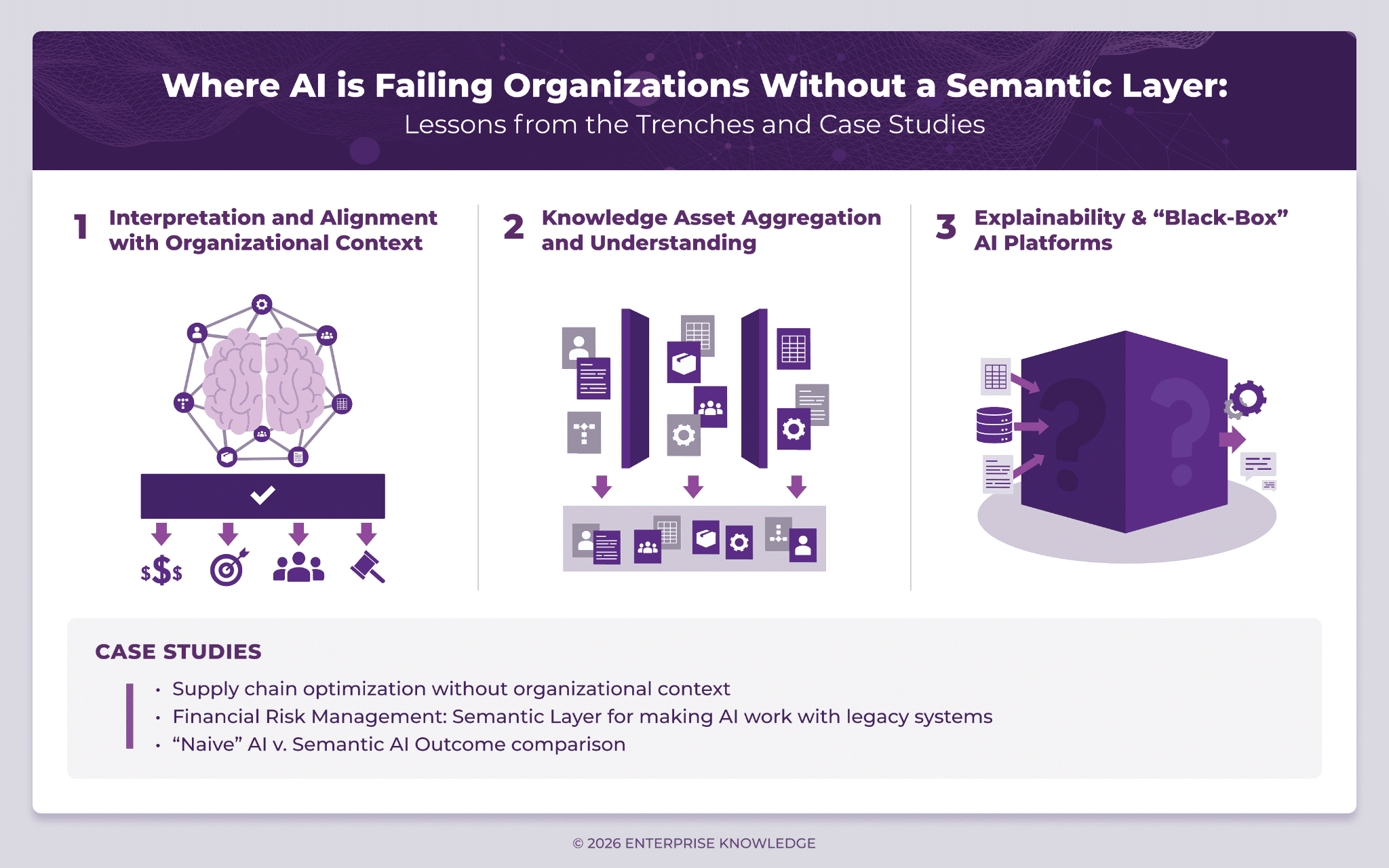
In this article, I will outline how the lack of this context and meaning layer is resulting in AI challenges, the specific ways semantic solutions continue to deliver value, along with case studies from organizations that faced challenges, and the lessons learned when overlooking these foundational practices.
1. Interpretation and Alignment with Organizational Context
One way to break down organizational context is to look at the different types of knowledge assets an organization relies on every day; its structured and unstructured data, the expertise people carry in their heads, the processes, operational logic that guide decisions, the cultural norms that shape behavior, and the shared language or “organizational vernacular” that everyone uses to get work done. For AI to truly enable an enterprise, it needs access to this context. It must understand intent, know what information matters most, and make decisions that align with the organization’s unique reality.
Where AI Works Well
In my previous article, How to Inject Organizational Knowledge in AI: 3 Proven Strategies to Achieve Knowledge Intelligence, I outlined several ways we’ve been helping companies embed domain knowledge and organizational context into their AI systems. One of the most relevant approaches here is the effective use of Retrieval Augmented Generation (RAG), which feeds LLMs with the right organizational information at the right time.
Basic or “naive” or vector-based RAG solutions have matured quickly. They work well when the goal is to pull together and summarize specific information from large collections of content or datasets that don’t change frequently. Paired with LLMs, this approach has proven especially useful for straightforward Q&A use cases that rely on retrieving direct facts and offering focused recommendations.
Where AI Fails
One of the most damaging consequences leading to failed AI efforts is when AI is unable to properly interpret organizational data and proceeds to make up stuff (hallucinate). Most pre-built, generic, or “naive” AI models can only work with the data they were trained on. If that data is incomplete, outdated, or flawed, their outputs will be too. Additionally, methods like RAG assume that the retrieved content and data are already clean and reliable, free of quality issues, and that the business need is a simple, one-time task. In reality, organizational data is rarely pristine, and most use cases involve ongoing, interconnected workflows.
Basic or “naive” RAG systems also struggle because they reduce rich organizational knowledge into isolated numerical vectors. By chunking documents into fixed sizes and indexing them by similarity, these systems often break the logical flow of information and lose critical relationships between ideas. This is especially problematic for complex materials (think legal documents tied to policies and procedures) where meaning depends on how sections relate to one another. As a result, these systems are reinforcing existing data silos or fragmentation instead of providing true meaning and understanding.
The real risk appears when retrieved data isn’t aligned with the organization’s goals, processes, or domain-specific context. Vector search may surface information that seems relevant but is actually misleading, leading to what’s now called “context poisoning.” AI then generates answers based on information that is close, but wrong. This disconnect between how organizations understand their own data and how AI interprets it is a major driver of AI failure, ultimately producing decisions that don’t reflect the organization’s true needs or intent, resulting in a lack of adoption.
How the Semantic Layer Addresses this AI Challenge
Semantic models and standards, such as business glossaries, taxonomies, ontologies, and knowledge graphs, establish a shared language and structured schema for interpreting and organizing information. They act as the meaning layer and connective tissue between disparate knowledge, data, and content, providing the richness, context, and interoperability necessary for AI readiness. At the heart of this foundation are several critical enablers grounded in knowledge, data, and content management best practices, now evolving to serve AI as one of its consumers:
- Contextual Metadata & Structure: Using controlled vocabularies, ontologies, and taxonomies to capture contextual meaning and attributes (authorship, subject matter, topic or “aboutness”, ownership, lifecycle), and maintain relationships across documents, structured data, and entities such as lifecycle stages and lineage through hierarchical indexing and knowledge graphs.
- Semantic Content Chunking & Retrieval: Content chunking involves breaking down large amounts of text into smaller, meaningful segments, which improves data processing, accuracy, and relevance. Basing this on semantic models, using AI to split text based on its meaning allows AI to chunk and consume chunks of content that are more semantically coherent. This chunking approach provides strategies that respect document structure while preserving semantic cohesion through hybrid retrieval (keyword, semantic, and graph-based search), thus improving machine understanding and helping to surface both exact matches while combining relevant information based on context and relationships.
- Flexible Architecture for Repeatable Delivery: A semantic layer architecture gives AI a flexible, composable foundation for AI applications to reuse the organization’s concepts, relationships, rules, and terminology instead of rebuilding context from scratch. This shared semantic layer allows new use cases to be deployed quickly, adapts easily as the business evolves, and prevents AI efforts from becoming isolated prototypes – driving consistent interpretation and enterprise-wide alignment.
These semantic-layer-backed capabilities are especially critical in high-value enterprise use cases that accelerate functionality and regulatory compliance, enhance decision support, or enable customer-facing self-service applications and agents.
Case Study
A compelling real-world example comes from a supply chain consultancy we’ve partnered with, which aims to help clients reduce their carbon footprints. Their out-of-the-box supply chain AI optimization system was designed to recommend the most cost-effective transportation options. However, the system kept prioritizing the cheapest routes, which often resulted in significantly higher emissions. This misalignment occurred because AI was trained to optimize solely for cost, without taking into account the environmental impact. While the system achieved financial efficiency, it failed to align with the clients’ Environmental, Social, and Governance (ESG) goals, highlighting the importance of planning for a more holistic, organizational-context-aware framework (through semantic enrichment) when designing AI solutions.
2. Knowledge Asset Aggregation and Understanding
Content and data for the average enterprise are housed in five or more distinct systems. For many large organizations, this could span 30+ bespoke or overlapping platforms – all with diverse but interrelated information spread throughout the organization in various types and formats. Whether it’s finance, marketing, engineering, sales, or customer service, each corner of the organization handles its knowledge assets differently, using unique terminology, processes, and methods for data/content creation and curation. For AI models to effectively address complex organizational problems that are typically shared across these groups, they need access to a significant amount of these dispersed organizational knowledge assets and understand what they mean and how they are related.
Where AI Works Well
One of the most effective applications of AI today lies in machine learning (ML) and analytics, particularly in aggregating data from multiple sources into an combined view, detecting patterns and similarities. ML algorithms especially excel when trained on clean, harmonized data drawn from across departments. This is why data and analytics teams independently continue to deliver foundational capabilities, data visualizations, and reporting dashboards with some transformation – ingestion processes that transform content and data inputs into unified formats based on historical or real-time data and patterns.
Another area where AI, especially LLMs, performs strongly is in processing and summarizing unstructured assets, such as text, emails, chat logs, documents, and files. These asset types account for more than 80% of an organization’s information landscape. When enhanced with Natural Language Processing (NLP) and Named Entity Recognition (NER), AI systems are able to extract entities, concepts, relationships, and sentiments from a massive corpus of content, structuring the unstructured – and ultimately getting it ready for aggregation.
Where AI Fails
Across all these scenarios, the persistent challenge remains in the deep misalignment between where organizations invest their resources and how their teams actually spend their time. Instead of generating organizational insights, data and AI teams are often trapped in the heavy lifting of asset preparation; gathering, cleaning, validating, and simply trying to understand the data before they can do meaningful work (~70% of their time according to IBM).
At the same time, AI models alone struggle to scale knowledge in a way that creates real, organization-wide impact. Whenever a task requires synthesizing information across multiple datasets, documents, or layers of context, the gap between pattern recognition and true comprehension becomes painfully clear. The data AI needs is never just a table or a document. It also needs the meaning that shifts by department, context, and purpose. When AI attempts to merge these knowledge assets from different parts of the organization without the right grounding and understanding of what is relevant and how they are connected, its limitations become even more pronounced. AI models have challenges when it comes to reliably integrating, interpreting, and acting on the organizational assets without proper frameworks. This includes common definitions, shared structures, and a collective understanding of how data is related. They falter in “stitching together” facts coherently, especially when confronted with complex, multi-dimensional questions and asset types. In short, the challenge becomes about not just having data, but also ensuring AI understands what the data actually means.
What results is fragmented and incomplete AI outputs that continue to reinforce the need for better context – a clear understanding of concepts and how they are connected (semantic grounding). This gap has fueled years of scattered AI initiatives and inconsistent decision-making across many large enterprises.
How a Semantic Layer Addresses this AI Challenge
AI works effectively when working with properly structured data/content and a solid semantic framework to aggregate and harmonize information across an organization and ultimately, make the right decisions. Specifically, a knowledge graph, a core component of the semantic layer, helps aggregate assets from multiple structured and unstructured sources (e.g., databases, data warehouses, CRM systems, CMS, etc.) into a unified view without the need to physically move or migrate data. In doing so, it provides a comprehensive view of organizational knowledge assets for AI models, serving as a logical map for AI to draw knowledge and meaning from broader sources. Furthermore, metadata graphs allow organizations to create semantic mappings between different content and data schemas (e.g., mapping “customer ID” in one system to “client ID” in another). They also help AI understand the meaning and domain-specific relationships of the concepts within diverse knowledge assets, ensuring models interpret data consistently while normalizing asset quality across various sources.
The most successful organizations are employing a hybrid, semantic-AI model, which augments knowledge model development by automatically identifying and classifying entities such as people, places, and things within unstructured content to create enterprise metadata, taxonomies, and knowledge graphs.
Case Study
We partnered with a global financial firm looking to overhaul its risk management program. The firm relied on more than 20 bespoke legacy applications, each covering a different slice of the risk process, which meant building a complete risk report could take nearly two months. Even simple questions like “What controls and policies relate to this risk?” required days of digging across disconnected systems.
To break this cycle, we worked with the firm over a phased engagement to enhance their data transformation efforts with a semantic layer. We started by piloting a conceptual graph of their risk landscape, defining shared taxonomies and controlled vocabularies (thesauri) that linked data scattered across the organization. Using ontologies, we made the relationships between risks, controls, issues, and policies and regulations explicit. Then, with the help of large language models, we summarized and reconciled more than 50,000 risks previously written in free text. Today, users can look up a risk and see everything connected to it in seconds, as opposed to weeks, through an intuitive graph interface. Just 18 months later, this semantic layer now powers several major tools: a searchable risk library with 360 risk-view panels, four recommendation engines, and a comprehensive dashboard with threshold and tolerance analytics and LLM integrations. A key reason for the project’s success was a composable architecture strategy. Instead of forcing the semantic model into every legacy app, the firm treated the semantic data models (metadata, taxonomies, etc.) as standalone data products. This made the semantic layer feel like a set of modular “Lego bricks” that teams and machines could plug into as needed without overhauling the old infrastructure.
3. Explainability & “Black-Box” AI Platforms
If an AI solution makes a mistake, who is held accountable? How can the issue be resolved if no one understands how a decision was made? Within the context of enterprise AI, “explainability” is having the ability to reconstruct the path from input to output – a way to trace content and data inputs that are causing the outputs and decisions from your AI solutions. Explainability is thus the bridge between a machine-generated suggestion and the specific data points, document versions, or organizational rules that triggered it. Without this bridge, AI remains a “black box,” a system where data goes in and answers come out, but the “why” remains a mystery.
In this case, the absence of a clear understanding of how business goals and data interact is leading not only to failed AI projects but also to lasting reputational damage with legal and ethical ramifications.
Where AI Works Well
AI really shines when the job is about speed, scale, and pattern-spotting rather than clear explanations. We have seen many organizations demonstrate that they are able to significantly scale and optimize their data operations by leveraging AI as a first-pass assistant, quickly scanning huge volumes of messy content, surfacing trends, and generating ideas that would take humans far longer to uncover on their own.
AI is able to deliver on this by ingesting millions of knowledge assets (emails, documents, images, tabular data, etc.) without needing a structure or schema up front. Used this way, AI reduces the black box risk by staying in the role it does best, handling first-pass work and uncovering signals and possibilities, while humans provide the meaning, judgment, and final decisions.
However, the challenge starts to emerge when AI is unable to provide logical reasoning on what that pattern means in the context of your specific business rules or why it decided to prioritize one document or data point over another.
Where AI Fails
Many modern AI platforms are attempting to solve this explainability crisis by providing a list of documents as “sources.” However, this often shifts the burden of proof back onto the human user. Remember when Google only returned a list of blue links? We are seeing a regression now where users must manually sift through four or five long files or PDFs to verify if their AI actually interpreted the text correctly or simply found a keyword match. Consider the common enterprise scenario wherein an employee feeds an AI platform all of their organization’s Standard Operating Procedures (SOPs) to answer employee questions about health benefits. In this simple but very common scenario, what we are consistently seeing is these top two traps:
- The versioning challenge: Many organizations have multiple versions of the same policy floating around. If AI provides an answer, how do you know the answer summary it generated didn’t come from a 2023 document instead of the 2025 update?
- The logic gap: Without organizational content, AI lacks the “rules of the road.” It cannot distinguish between a “draft” tag and a “final” metadata marker unless those concepts are formally defined and machine-readable.
As a result, many complex AI models end up delivering results (sometimes wrong ones) without a clear explanation of how decisions were reached, which undermines trust and makes auditing for compliance difficult.
Semantic Layer as the “Glass Box” Solution
Successful AI efforts have demonstrated that AI becomes far more trustworthy when it’s anchored to organizational logic and semantic foundations. Semantic models like metadata, business glossaries, taxonomies, and ontologies give AI something tangible (and machine-readable) to reason against. Semantics ground AI decisions in a structured knowledge framework with traceable reasoning paths instead of relying purely on probabilistic guesses. Specifically, semantic frameworks strengthen AI’s independent work through:
- Traceability back to trusted sources: By using metadata, organizations can implement citation and provenance tracking. AI outputs can be tied directly to verified “golden” source documents. This links every AI-generated output back to a verifiable source grounded in “ready” organizational knowledge assets.
- Context-aware decisions and ranking: Instead of just looking for word overlaps, a semantic model provides AI the blueprint to understand the intent behind a query. It helps prioritize decisions and results based on organizational contextual information such as metadata around the user’s role, department, or geographic location.
- Human-in-the-loop scoring: Semantic frameworks allow for confidence scoring. If AI is unable to navigate the path through the semantic framework or finds certain requests ambiguous, this can be used as a business rule and a precursor for it to be flagged as uncertain for human review instead of presenting false confidence and hallucinations.
Case Study
We have been working with a global foundation that had previously been through failed AI experiments as part of a mandate from their CEO for their data teams to “figure out a way to adopt LLMs”. The mandate was to use LLMs to evaluate the impact of their investments on strategic goals by synthesizing information from publicly available domain data, internal project reports and documents, and internal investment/financial data. The initial challenge for previously failed efforts lay in connecting diverse and unstructured information to structured data and ensuring that the insights generated were precise, explainable, reliable, and actionable for executive stakeholders.
To address these challenges, we took a hybrid approach that leveraged LLMs that were augmented through advanced graph technology and a semantic RAG agentic workflow. To provide the relevant organizational metrics and connection points in a structured manner, the solution leveraged an Investment Ontology as a semantic backbone that underpins and explicitly defines how their disconnected, investment-related data in siloed source systems is connected (from structured datasets to narrative reports) and harmonized under a common language. This semantic backbone supports both precise data integration and flexible query interpretation. To effectively convey the value of this hybrid approach, we leveraged a chatbot that served as a user interface to toggle back and forth between the basic GPT or naive AI model versus the graph RAG solution. The result is a solution that consistently outperforms the basic/naive LLMs for complex questions, demonstrating the value of semantics for providing organizational context and alignment, and ultimately, delivering coherent and explainable insights that bridge structured and unstructured investment data. The solution provided a transparent AI mapping that allowed stakeholders to see exactly how each answer was derived.

Closing
The failure of many AI initiatives stems from the absence of a clear understanding of how business goals, organizational knowledge assets, technology, and AI interact. When paired with strong semantic frameworks, AI performs best by using business rules and context as a guide, prioritizing the right information and flagging uncertainty when confidence is low. Without this grounding, we have seen many organizations’ AI initiatives stall in delivering meaningful value. As experimentation with AI continues, those who don’t establish clear semantic foundations continue to find themselves stuck in a cycle of frustration, rework, and ultimately failed efforts.
This trend explains the significant uptick in investment we are seeing for semantic solutions and the specialized expertise required to build them across various industries and platforms. The organizations successfully pivoting from AI frustration to measurable ROI are those that have stopped treating AI as a standalone capability. Instead, they are integrating AI as a core component of a larger, more robust knowledge architecture. By grounding AI capabilities in a structured context and standard layer, these leaders are ensuring that their AI initiatives are reliable and aligned with the reality of their business.
Is your organization looking into semantic frameworks to ensure the success of your AI efforts? Explore our case studies and knowledge base on how other organizations are tackling this, self-evaluate your organization’s AI readiness, or email us at info@enterprise-knowledge.com for more information or assistance with implementing a semantic layer.