
Natural Language Processing (NLP) is a branch of artificial intelligence (AI) that processes and analyzes human language found in text. Some of the exciting capabilities that NLP offers includes parsing out the significant entities in content through a statistical analysis and identifying contextual relationships between different words. Taxonomy also aims to provide a hierarchical context for concepts and the words used to describe them. Taxonomists care about how people use language to categorize and identify concepts, in an effort to make information usable for both people and technology.
At EK, depending on the scope of a project, we incorporate NLP into the taxonomy design process in order to deliver highly detailed, relevant, and AI-ready designs that are backed by statistical processes generated from unstructured text data. One of EK’s key differentiators is our hybrid approach to designing business taxonomies. Our top-down approach leverages subject matter experts and business stakeholders to ensure a taxonomy is accurate and relevant for a domain or organization, while our bottom-up approach analyzes existing content and systems to ensure a taxonomy design is useful for the people and systems that will be using the taxonomy. Essentially, NLP in taxonomy design is a type of bottom-up process in which Named Entity Recognition (NER) collects the lowest level terms found in the content. The taxonomist can then identify broader categories for these terms. This is complemented by top-down analysis when engaging SMEs to help name and fine tune the categories, thus fulfilling EK’s hybrid methodology for taxonomy design.
However, NLP is far from automating the human judgment that is required in taxonomy design-data scientists and taxonomists (as well as subject matter experts) need to work together to determine why and how the data generated by NLP will be incorporated into a taxonomy. Here, I outline the ways in which NLP can enhance taxonomy design, and why taxonomists should consider teaming up with data scientists.
Named Entity Recognition and Taxonomy Development
 Named Entity Recognition (NER) is a branch of NLP that identifies entities in text. NER can be implemented using powerful Python libraries like spaCy, a NLP library that can be used to train an initial NER model from annotations of sample content. For specific industries, NER models will have to be trained to find entities in different domains. For example, a general scientific model can be used for a medical domain, though the model will have to be further trained to identify entities such as medications, conditions, and medical procedures.
Named Entity Recognition (NER) is a branch of NLP that identifies entities in text. NER can be implemented using powerful Python libraries like spaCy, a NLP library that can be used to train an initial NER model from annotations of sample content. For specific industries, NER models will have to be trained to find entities in different domains. For example, a general scientific model can be used for a medical domain, though the model will have to be further trained to identify entities such as medications, conditions, and medical procedures.
 An NER pipeline can run on a volume of content in order to identify and extract the entities found in the content. Once the NER extracts terms, a data scientist can use semantic word embeddings to cluster the entities in an unsupervised learning process; this means the algorithm makes inferences about a data set without human input or labeling. This results in clusters of terms that have a statistical relationship to each other, derived from the way the terms are used in the language of the content.
An NER pipeline can run on a volume of content in order to identify and extract the entities found in the content. Once the NER extracts terms, a data scientist can use semantic word embeddings to cluster the entities in an unsupervised learning process; this means the algorithm makes inferences about a data set without human input or labeling. This results in clusters of terms that have a statistical relationship to each other, derived from the way the terms are used in the language of the content.
Usually, taxonomists can derive a theme from these clusters by reviewing the types of terms that are in each cluster. Can you see a theme in the two clusters below?
| Two Clusters |
| morphine, opioid, opioids, cocaine, benzodiazepine, benzodiazepines, overdose, opiate, antagonist, methamphetamine, analgesic, methadone, stimulant, Benzodiazepines, buprenorphine, flumazenil, heroin, methamphetamines, naloxone, Naloxone, opioid-induced, sedative, narcotic, self-administering, self-administration |
| rash, erythema, acrocyanosis, pedis, itchy, conjunctivitis, blistering, eczema, impetigo, urticaria, herpetiformis, Tinea crurisi, atopic dermatitis, Erythema toxicum neonatorum, hyperpigmentation, papules, photosensitivity, Tinea corporis, cutaneous, pruritic |
Since word embeddings are statistical estimations of a word’s usage in a given language, the clusters generated using word embeddings aren’t always perfect from a human perspective. They do make it easier, however, to identify similar types of words and phrases in a body of content. The clusters and word embeddings won’t be able to tell you exactly what that relationship is between the terms, but in our clusters above, a trained taxonomist can deduce that the first cluster has to do with medications, specifically opioids (and other words that are closely related to opioids, such as overdose and antagonists). The second cluster generally has to do with skin conditions.
Once you have identified the various cluster themes (this particular process resulted in several hundred clusters), you can group those themes into another level of broader categories and continue to go up the ladder of the taxonomy into Level 3, Level 2, or Level 1 concepts. For instance, if we continue with the medication example, we may have another cluster of specific antibiotic drugs, as well as antihypertensives. We now know that we need a broader Medication/Chemicals/Drugs category in order to group these themes (opioids, antibiotics, antihypertensives) together. And voila! We have a taxonomy created with the assistance of Natural Language Processing.
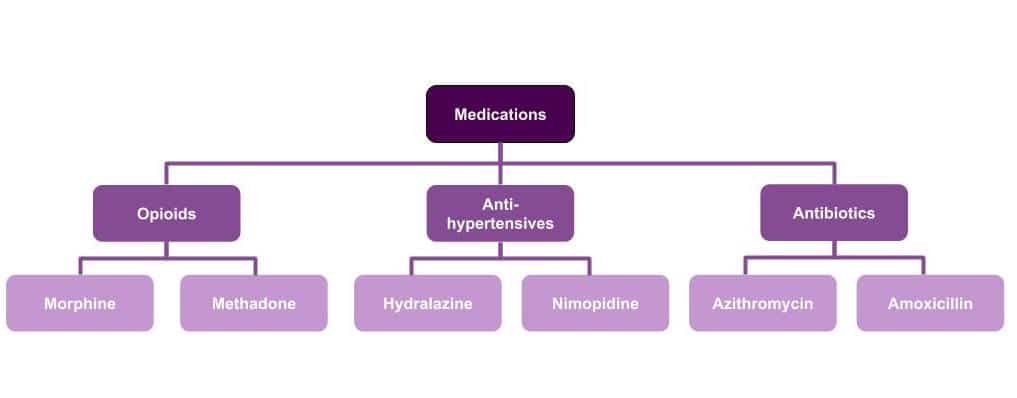
Relevancy and Taxonomy Use Cases
Not all clusters will be relevant to a taxonomy. Sometimes the themes of a cluster will be a certain part of speech, such as adjectives or verbs that seem meaningless on their own; these usually have to be paired with other entities to create a phrase that then becomes meaningful to the domain. These entities most likely exist in other clusters, so it will be helpful to have a tool to look up these phrases in the content to see how they are paired with other entities.
Even though the NER process has found a statistical relationship to form these clusters, this doesn’t mean that we need to incorporate those clusters into our taxonomy. This is when good old human judgement and defined taxonomy use cases will help you decide what is needed from the NER results. A use case is the specific business need that a taxonomy is intended to fulfill. Use cases should always be the signal guiding your way through any taxonomy and ontology effort.

Taxonomy and NLP Iteration
Just like taxonomy design, an NLP process should be iterative. Think of the entire process as a feedback loop with your taxonomy. A data scientist can use the fledgling taxonomy to improve the NER models to be more accurate by annotating content manually with the new labels, which improves the desirability of the clusters returned. A more accurate and repeatedly trained model will be able to look for more precise and narrow concepts. For instance, certain medical conditions and medications would have to be annotated in order to be recognized as part of a conditions or medications model.
Once this has been done, you can train the model on the annotations as many times as needed in order to return an increasingly accurate set of terms relevant to the model. Depending on the results, this may necessitate a restructuring of the taxonomy; perhaps another grouping or subgrouping of medical conditions is discovered, which weren’t previously included in the initial NER analysis, or it becomes clear your taxonomy needs an ontology.
Leverage a Gold Standard
It’s highly suggested that you create a “gold standard” (with the critical input of SMEs and business stakeholders) for the most significant types of semantic relationships that are needed to achieve your goals. In creating a gold standard, SMEs and other stakeholders identify the logic/patterns between concepts that best support your use cases-and then focus only on these specific patterns, at least in the first iteration.
If your use case is a recommendation engine, for example, you need to prioritize the relationships between concepts that help facilitate the appropriate recommendations. In our healthcare example, we may find that the best recommendations are facilitated by ontological relationships-perhaps we need an ontology to describe the relationship between bacterial infections and antibiotics, or the relationship between symptoms and diagnosable conditions.
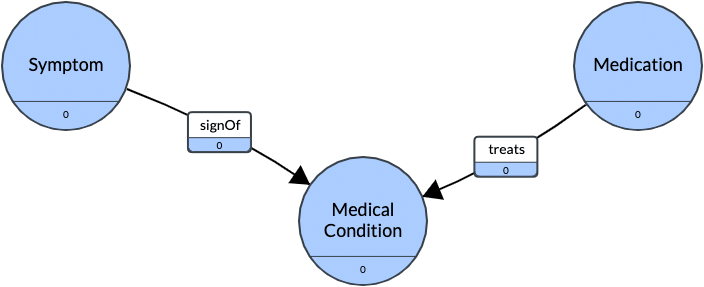
If your use case is for search and findability, you could utilize user research methods such as card sorting to gain a better understanding of how users will relate the concepts to one another. This may also provide guidance on how to build an initial taxonomy with the term clusters, by allowing users to sort the terms into predefined or user-created categories. From there, an analysis of the general relationship patterns can be used as a gold standard to prioritize how the NLP data will be used.
The purpose of a gold standard is to prioritize and set a strict scope on how NLP will assist taxonomy design. The NLP process of entity extraction, clustering, labeling, annotating, and retraining is an intensive process that will generate a lot of data. It can be difficult and overwhelming to decide how much and which data should be incorporated into the taxonomy. A gold standard, basically a more detailed application of use cases, will make it much easier to decide what is a priority and what is outside the scope of your use cases.
Conclusion
NLP is a promising field that has many inherent benefits for taxonomy and ontology design. Teams of data scientists, taxonomists, and subject matter experts that utilize NLP processes, alongside a gold standard and prioritized use cases, are well positioned to create data models for advanced capabilities. The result of this process will be a highly detailed and customized solution derived from an organization’s existing content and data.
If your taxonomy or ontology effort seems to frequently misalign with the actual content or domain you are working in, or if you have too much unstructured data and content to meaningfully derive and conceive a taxonomy that will accurately model your information, an NLP assisted taxonomy design process will provide a way forward. Not only will it help your organization gain a complete sense of its information and data, it will also glean valuable insights about the unseen connections in data, as well as prepare your organization for robust enterprise data governance and advanced artificial intelligence capabilities-including solutions such as recommendation engines and automated classification.
Interested in seeing how NLP can assist your taxonomy and ontology design? Contact Enterprise Knowledge to learn more.