

The Challenge
A federally funded engineering research center has an extensive “project library” where technical documents, certifications, and reports related to various engineering projects are stored. Many of these documents are often scanned versions of handwritten notes or files and, consequently, have little metadata attributed to them and are very difficult to surface in search. Additionally, when employees start working on new projects, it’s difficult to ascertain what was done on previous projects, who did the work, and when that work occurred.
Similarly, project managers struggled to discern which employees possessed specific skill sets or experience when they were staffing new projects. The specificity of these needs was not easily captured in structured formats and often covered one-off, rather than repetitive, use cases (e.g., “who worked on this project and what role did they play?”). The best option for locating someone with a specific ability or experience was to rely on personal networks or institutional memory, making it difficult to leverage institutional knowledge or onboard new employees effectively.

The Solution
To help connect the dots between people, projects, engineering components, and engineering topics, Enterprise Knowledge (EK) developed a proof of concept enterprise knowledge graph. Leveraging and enriching an existing taxonomy and ontology at the organization, EK was able to automatically extract key entities from a repository of unstructured documents, using the documents as the “glue” to form connections between the aforementioned entities.
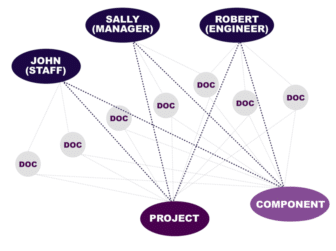
The benefits of semantic technology allowed EK to expand the knowledge graph by incorporating existing structured information about individuals at the organization, creating a more holistic understanding of who these people are, what they’ve worked on, and how to contact them.
Finally, EK incorporated the knowledge graph into a semantic search platform to enable faceted search and navigation across individuals, projects, and the unstructured text documents (e.g., the scanned, handwritten notes and files). This search platform allows users to drill down to a small group of individuals that worked on a specific project and/or have experience with a particular engineering topic or component, reducing time in finding a qualified individual from weeks to a few minutes.

The EK Difference
To achieve the above solution, it was necessary to develop a plethora of integrations between graph databases, relational databases, content management systems, taxonomy management tools, and data pipeline (ETL) tools. Through our expertise in designing and implementing the top semantic tools in the industry, EK was able to develop a scalable solutions architecture while leveraging web standards and providing guidance on integration best practices to deliver timely, effective, and scalable integration solutions.
Additionally, EK leveraged advanced capabilities to drive enhanced and automated tagging and classification of content, making the process more efficient, while mitigating the possibility of human error. We further partnered with the organization’s key subject matter experts and leveraged an Agile methodology that allowed us to quickly show results and provide incremental value to the organization.

The Results
The foundational knowledge graph and semantic search interface allow users to browse documents by person, project, and topic, providing supporting links to source data so that they can analyze the relationships between people and projects directly. End users can now easily browse and discover relationships that were previously uncaptured or buried in disparate data repositories, reaching the ‘goal’ information in a fraction of the time. Further, the flexibility of the knowledge graph solution allows for greater agility to modify and improve data flows without making extensive changes to architectures or schemas, resulting in quick turn-around times for updates as project staff change and requirements evolve.