
One of the most common Knowledge Management (KM) pitfalls at any organization is the inability to find fresh, reliable information at the time of need.
One of, if not the most prominent, causes of this inability to quickly find information that EK has seen more recently is that an organization possesses multiple content repositories that lack a clear intention or purpose. As a result, users are forced to visit each repository within their organization’s technology landscape one at a time in order to search for the information that they need. Further, this problem is often exacerbated by other KM issues, such as a lack of proper search techniques, organization mismanagement of content, and content sprawl and duplication. In addition to a loss in productivity, these issues lead to rework, individuals making decisions on outdated information, employees losing precious working time trying to validate information, and users relying on experts for information they cannot find on their own.
Along with a solid content management and KM related strategy, EK recommends that clients experiencing these types of findability related issues also seek solutions at the technical level. It is critical that organizations take advantage of the opportunity to streamline the way their users access the information they need to do their jobs; this will allow for the reduction of time and effort of users spent searching for information, as well as the assuage of the aforementioned challenges. This blog will explain how organizations can proactively mitigate the challenges of siloed information in different applications by instituting a unique set of technical solutions, including taxonomy management systems, metadata hubs, and enterprise search, to alleviate these problems.
With the abundance and variety of content that organizations typically possess, it is often unrealistic to have one repository that houses all types of content. There are very few, if any, content management systems on the market that can optimally support the storage of every type of content an organization may have, let alone possess the search and metadata capabilities required for proper content management. Organizations can address this dilemma by having a unified, centralized search experience that is able to search all content repositories in a secure and safe manner. This is achieved through the design and implementation of a semantic layer – a combination of unique solutions that work together to provide users one place to go to for searching for content, but behind the scenes allow for the return of results from multiple locations.
In the following sections, I will illustrate the value of Taxonomy Management Systems, Enterprise Search, and Metadata Hubs that make up the semantic layer, which collectively enable a unique and highly beneficial set of solutions.
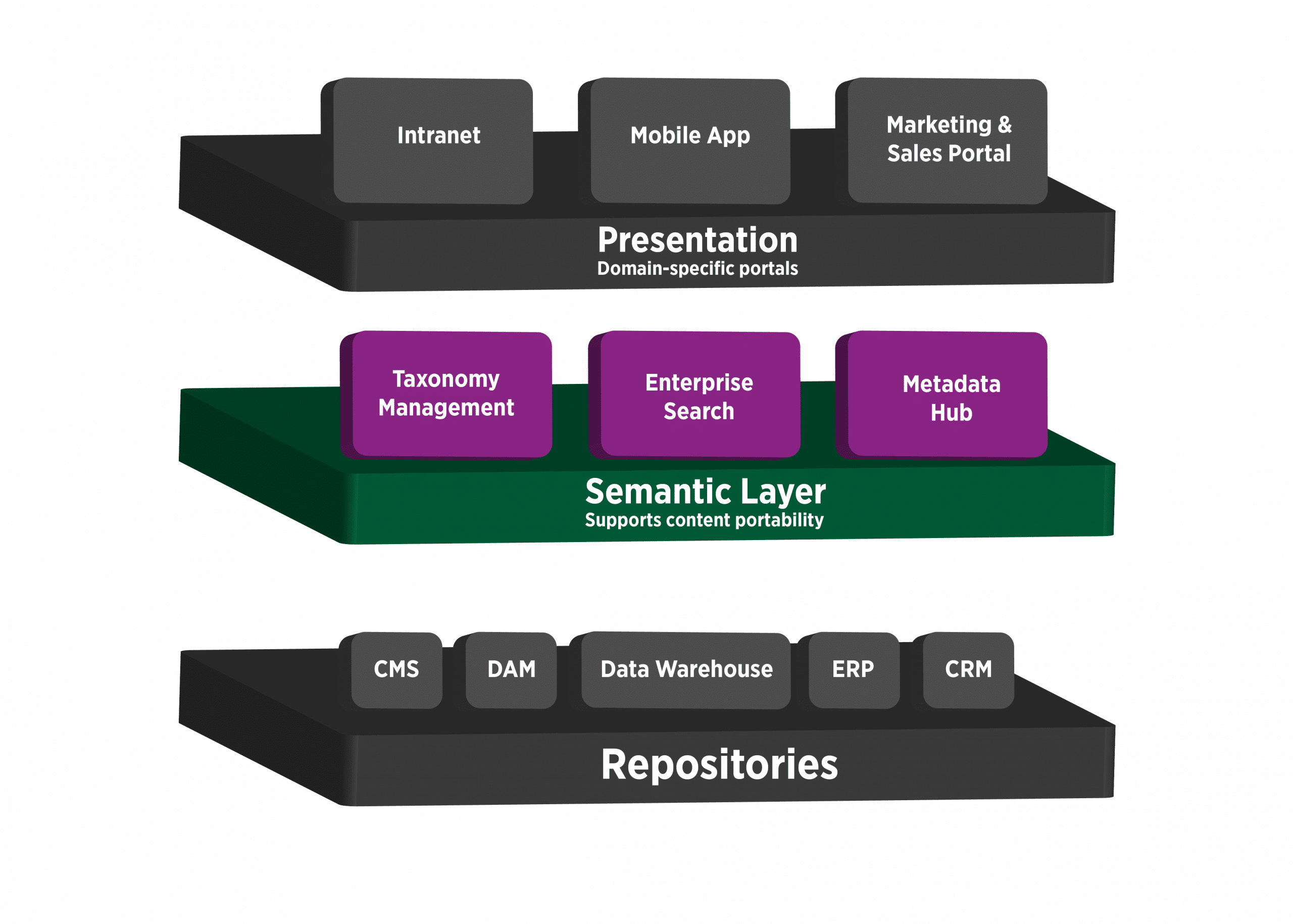
Taxonomy Management Systems
In order to pull consistent data values back from different sources and filter, sort, and facet that data, there must be a taxonomy in place that applies to all content, in all locations. This is achieved by the implementation of an Enterprise TMS, which can be used to create, manage, and apply an enterprise-wide taxonomy to content in every system. This is important because it’s likely there are already multiple, separate taxonomies built into various content repositories that are different from one another and therefore cannot be leveraged in one system. An enterprise wide taxonomy allows for the design of a taxonomy that applies to all content, regardless of its type or location. An additional benefit of having an enterprise TMS is that organizations can utilize the system’s auto-tagging capabilities to assist in the tagging of content in various repositories. Most, if not all major contenders in the TMS industry provide auto-tagging capabilities, and organizations can use these capabilities to significantly reduce the burden on content authors and curators to manually apply metadata to content. Once integrated with content repositories, the TMS can automatically parse content, assign metadata based on a controlled vocabulary (stored in the enterprise taxonomy), and return those tags to a central location.
Metadata Hub
The next piece of this semantic layer puzzle is a metadata hub. We often find that one or more content repositories in an organization’s KM ecosystem lack the necessary metadata capabilities to describe and categorize content. This is extremely important because it facilitates the efficient indexing and retrieval of content. A ‘metadata hub’ can help to alleviate this dilemma by effectively giving those systems their needed metadata capabilities as well as creating a single place to store and manage that metadata. The metadata hub, when integrated with the TMS can apply the taxonomy and tag content from each repository, and store those tags in a single place for a search tool to index.
This metadata hub acts as a ‘manage in place’ solution. The metadata hub points to content in its source location. Tags and metadata that are being generated are only stored in the metadata hub and are not ‘pushed’ down to the source repositories. This “pushing down” of tags can be achieved with additional development, but is generally avoided as not to disrupt the integrity of content within its respective repository. The main goal here is to have one place that contains metadata about all content in all repositories, and that this metadata is based on a shared, enterprise-wide taxonomy.
Enterprise Search
The final component of the semantic layer is Enterprise Search (ES). This is the piece that allows for individuals to perform a single search as opposed to visiting multiple systems and performing multiple searches, which is far from the optimal search experience. The ES solution acts as the enabling tool that makes the singular search experience possible. This search tool is the one that individuals will use to execute queries for content across multiple systems and includes the ability to filter, facet, and sort content to narrow down search results. In order for the search tool to function properly, there must be integrations set up between the source repositories, the metadata hub, and the TMS solution. Once these connectors are established, the search tool will be able to query each source repository with the search criteria provided by the user, and then return metadata and additional information made available by the TMS and metadata hub solutions. The result is a faceted search solution similar to what we are all familiar with at Amazon and other leading e-commerce websites. These three systems work together to not only alleviate the issues created by a lack of metadata functionalities in source repositories, but also to give users a single place to find anything and everything that relates to their search criteria.
Bringing It All Together
The value of a semantic layer can be exemplified through a common use case:
Let’s say you are trying to find out more information about a certain topic within your organization. In order to do this, you would love to perform a search for everything related to this certain topic, but realize that you have to visit multiple systems to do so. One of your content repositories stores digital media, i.e. videos and pictures, another of your content repositories stores scholarly articles, and another one stores information on individuals who are experts on the topic. There could be many more repositories, and you must visit each one separately and search within each system to gather the information you need. This takes considerable time and effort and in a best case scenario makes for a painstakingly long search process. In a worst case scenario, content is missed and the research is incomplete.
With the introduction of the semantic layer, the searchers would only have to visit one location and perform a single search. When doing so, searchers would see the results from each individual repository all in one location. Additionally, searchers would have extensive amounts of metadata on each piece of content to filter to ensure that they find the information they are looking for. Normally when we build these semantic layers the search allows users the option to narrow results by source system, content type (article, person, digital media), date created or modified, and many more. Once the searcher has found their desired content, a convenient link is provided which will take them directly to the content in its respective repository.
Closing
The increasingly common issue of having multiple, disparate content repositories in a KM technology stack is one that causes organizations to lose valuable time and effort, while hindering employees’ ability to efficiently find information through mature, proven metadata and search capabilities. Enterprise Knowledge (EK) specializes in the design and implementation of the exact systems mentioned above and has proven experience building out these types of technologies for clients. If your company is facing issues with the findability of your content, struggling with having to search for content in multiple places, or even finding that searching for information is a cumbersome task, we can help. Contact us with any questions you have about how we can improve the way your organization searches for and finds information within your KM environment.