
Traditional machine learning (ML) workflows have proven effective in a wide variety of use cases, from image classification to fraud detection. However, traditional ML leaves relationships between data points to be inferred by the model, which can limit its ability to fully capture the complex structures within the data. In enterprise environments, where data often spans multiple, interwoven systems—such as customer relations, supply chains, and product life cycles—traditional ML approaches can fall short by missing or oversimplifying relationships that drive critical insights into customer behavior, product interactions, and risk factors. In contrast, graph approaches allow these relationships to be explicitly represented, enabling a more comprehensive analysis of complex networks.
Graph machine learning (Graph ML) offers a new paradigm for handling the complexities of real-world data, which often exists in interconnected networks. For example, Graph ML can be leveraged to build highly effective recommender systems, to identify critical connections and enhance decision-making. Unlike traditional ML, which treats data as independent observations, Graph ML captures the interactions and connections between data points, revealing patterns that are invisible to traditional methods. Recognizing the pivotal role of graph technologies in driving innovation across data analytics, data professionals are increasingly optimizing their workflows to harness these powerful tools. But why should data professionals care about Graph ML? By understanding these differences and leveraging graph structures, data professionals can unlock new predictive capabilities that were previously out of reach. Whether you’re aiming to enhance fraud detection, optimize recommendation systems, or improve social network analysis, Graph ML is an increasingly valuable tool in the data scientist’s toolkit.
In this blog, we will explore the unique advantages that Graph ML offers over traditional approaches. We’ll dive into graph-specific considerations throughout each step of the machine learning process, from pre-processing to model evaluation, and provide expert advice for effectively integrating graph techniques into your ML workflow. While you can use standard machine learning processes to answer simple use cases and scenarios such as image classification, basic customer churn prediction, or straightforward regression analysis–graph machine learning allows you to tackle richer, network-driven scenarios, including fraud detection through network anomaly patterns, sophisticated recommendation engines built on user-item graphs, and social network influence analysis. If you haven’t yet built a graph for your organization, here are the high-level steps: identify the entities and relationships within your use-case, build a graph schema, and load your data into a graph database. For more in-depth guidance, see this detailed guide on developing an enterprise-level graph. This process often includes breaking down your data into triples (subject-predicate-object) and representing the connections between nodes through methods like adjacency matrices, embeddings, or random walks.
Understanding the ML Development Lifecycle
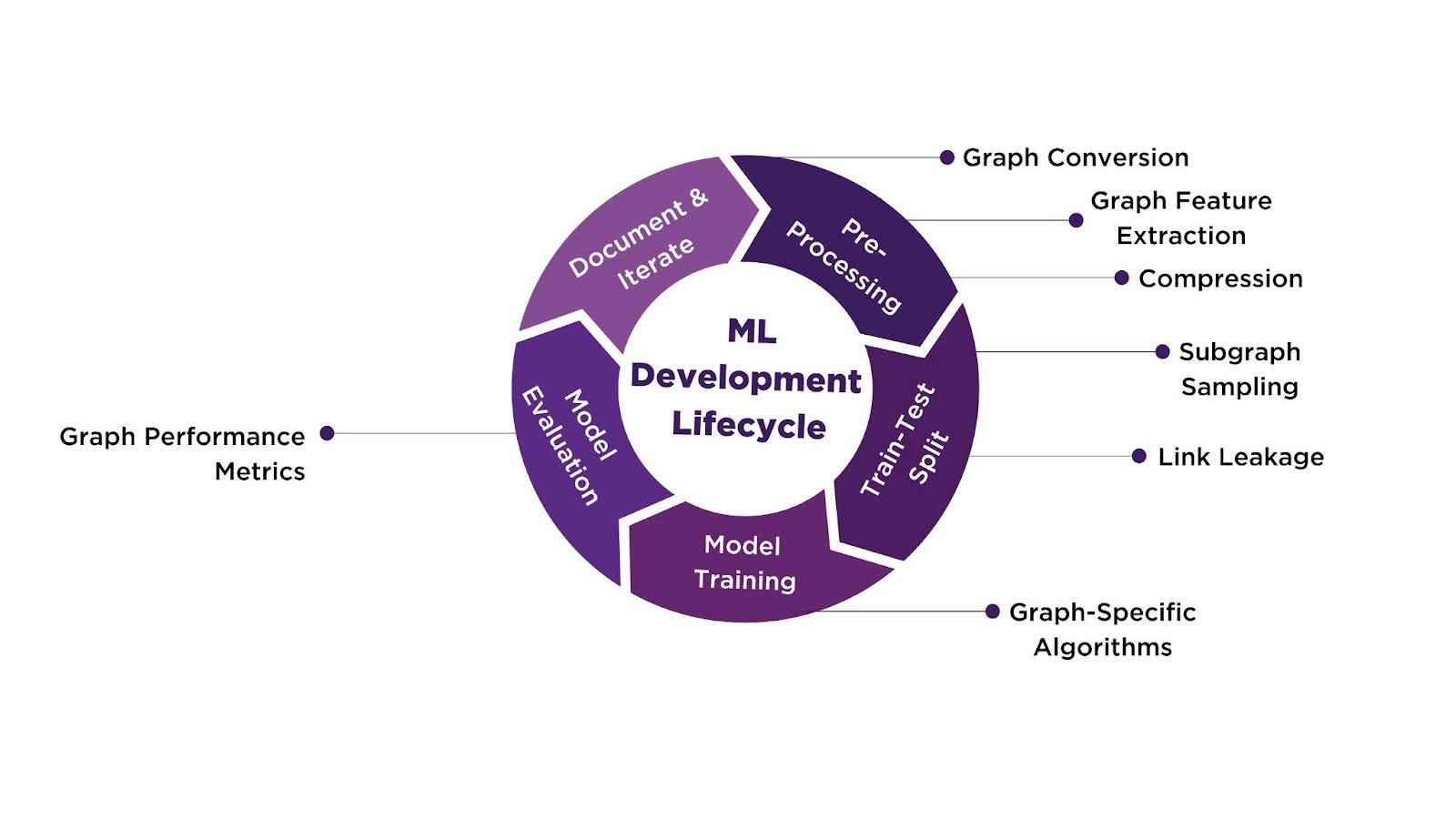
Take a moment to review the ML development lifecycle wheel above. The wheel is divided into five distinct sections: Pre-Processing, Train-Test Split, Model Training, Model Evaluation, and Document and Iterate. Below, we start with Pre-Processing, where we transform raw data into a graph structure, extract critical graph features, and apply compression techniques to manage complexity. Each subsequent section will build on these foundations by detailing the specific approaches and methodologies used in Train-Test Split, Model Training, and Model Evaluation. The wheel serves as our roadmap for understanding how Graph Machine Learning allows for deeper insights from complex, interconnected data.
Step 1: Pre-Processing
Graph Conversion
Business Value: In traditional ML, raw data is processed as independent feature vectors–meaning models often miss the relationships between entities and can’t leverage network effects. In contrast, graph conversion allows for the systemic mapping of raw data into a structured network of entities and relationships, revealing new insights and perspectives.
The first step in Pre-Processing is graph conversion. Graph conversion is the process of transforming unstructured, semi-structured, or structured data into a graph model where individual entities become nodes and the connections, or relationships, between them are represented as edges. This conversion lays the groundwork for advanced graph analysis by explicitly modeling the relationships within the data, rather than leaving all of the connections to be inferred.
This foundational graph conversion not only organizes the raw data into a clear structure but also enables the extrapolation of clusters, central nodes, and intricate, multi-hop relationships. This structured representation not only enhances the clarity of data analysis, but also establishes a foundation for scalable predictive modeling and clearer understanding of intricate linkages. This base sets the stage for the next step of Pre-Processing: Graph Feature Extraction.
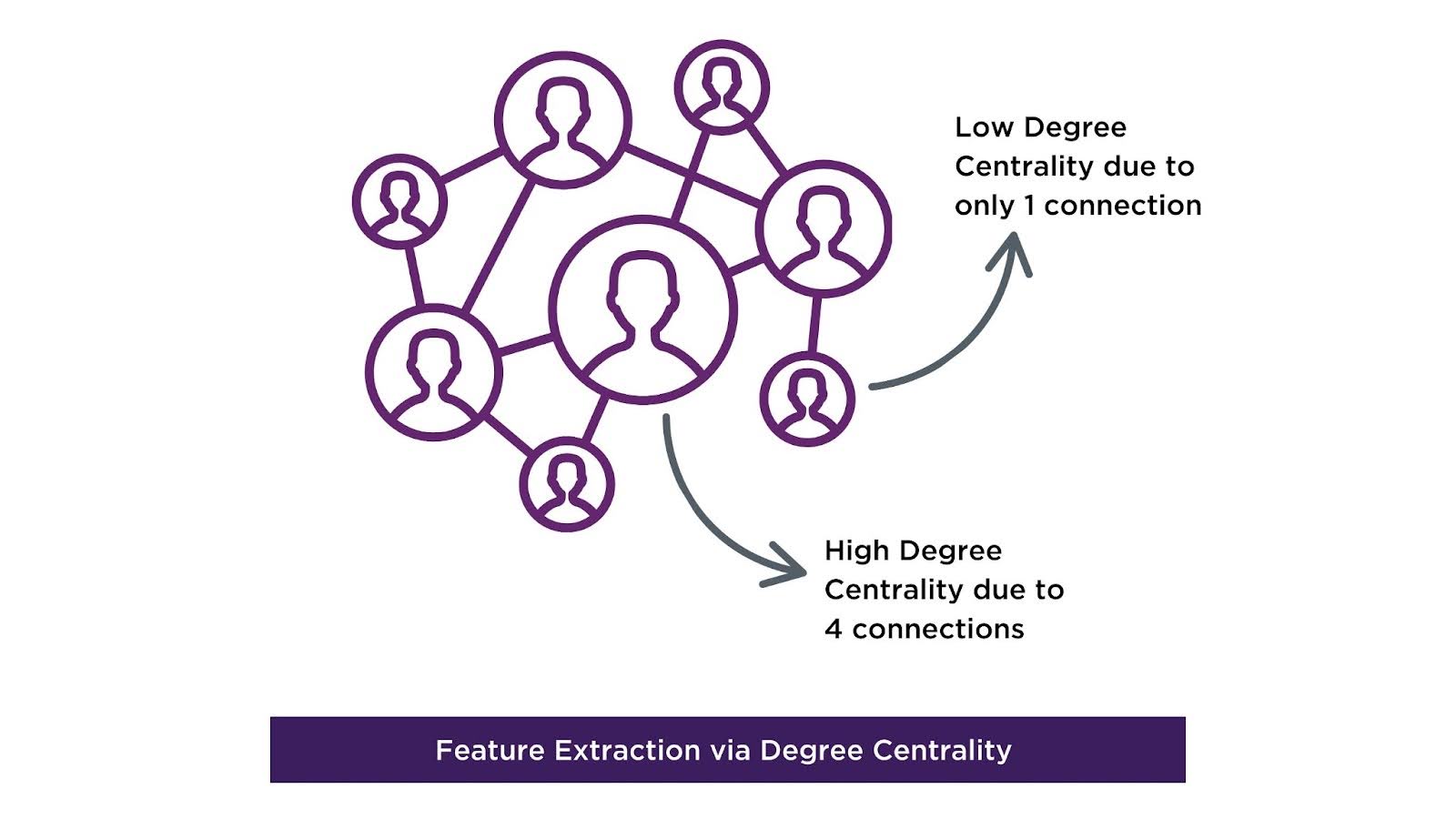
Graph Feature Extraction
Business Value: Conventional feature extraction methods treat each data point in isolation, often missing how entities connect in a network. Graph features capture both individual data attributes and relational patterns, allowing models to assess influence, connectivity, and community dynamics, providing a richer context compared to traditional feature extraction.
Graph-specific feature extraction captures not only individual data point attributes but also the relationships and structural patterns between data points that traditional methods miss. Graph features, such as Degree Centrality and Betweenness Centrality, reveal the importance of a node within the overall network, allowing models to predict how influential or well-connected an entity is in relation to others.
Features like PageRank Scores help in ranking nodes based on their connectivity and importance, making them especially useful in recommendation systems and fraud detection, where influence and connectivity play a key role. Clusters and community detection features capture groups of interconnected nodes, enabling tasks like identifying suspicious behavior within certain groups or detecting communities in social networks. These rich, interconnected features allow Graph ML models to make predictions based on the broader context, not just isolated points, giving them a deeper understanding of the data’s inherent relationships. This comprehensive feature extraction naturally leads into the next step in Pre-Processing: Compression, where we streamline the data while preserving these critical relational insights.
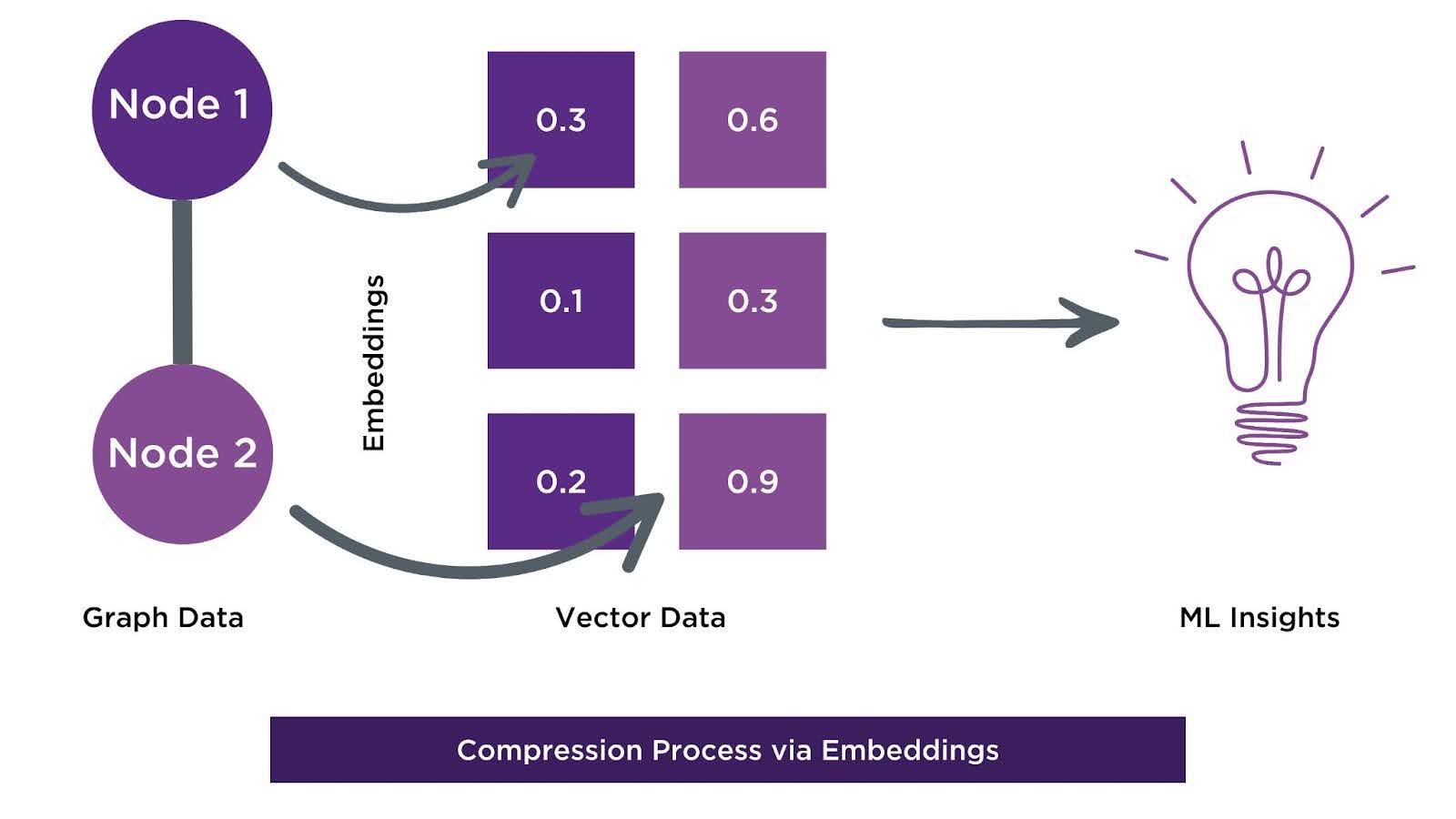
Compression
Business Value: Graph compression preserves structural relationships while reducing complexity, enabling efficient analysis without sacrificing key insights embedded in the graph’s intricate connections.
Compression is used to reduce the size, complexity, and redundancy of a graph while ensuring its structure and information are preserved. In traditional ML, dimensionality reduction methods like PCA or feature selection are used to reduce data complexity, but these methods overlook the relational structure between entities. In contrast, graph compression techniques, such as node embeddings, graph pruning, and adjacency matrix compression, preserve the graph’s inherent connections and patterns while simplifying the data. Node embeddings, in particular, are a powerful way to represent nodes as feature-rich vectors, capturing both the attributes of a node and its relational context within the graph.
Compression is an essential step in Graph ML because graphs often contain far more intricate details about the relationships between entities, which require high computing power to analyze. Compression helps reduce the noise and irrelevant connections that can distract the model, allowing it to focus on the most critical relationships within the graph. This ability to retain the most meaningful structural information while reducing computational overhead gives Graph ML an edge over traditional methods, which may lose key insights during dimensionality reduction. With Compression, the Pre-Processing phase is complete, setting a clear and efficient foundation as we move into Step 2: Train-Test Split.
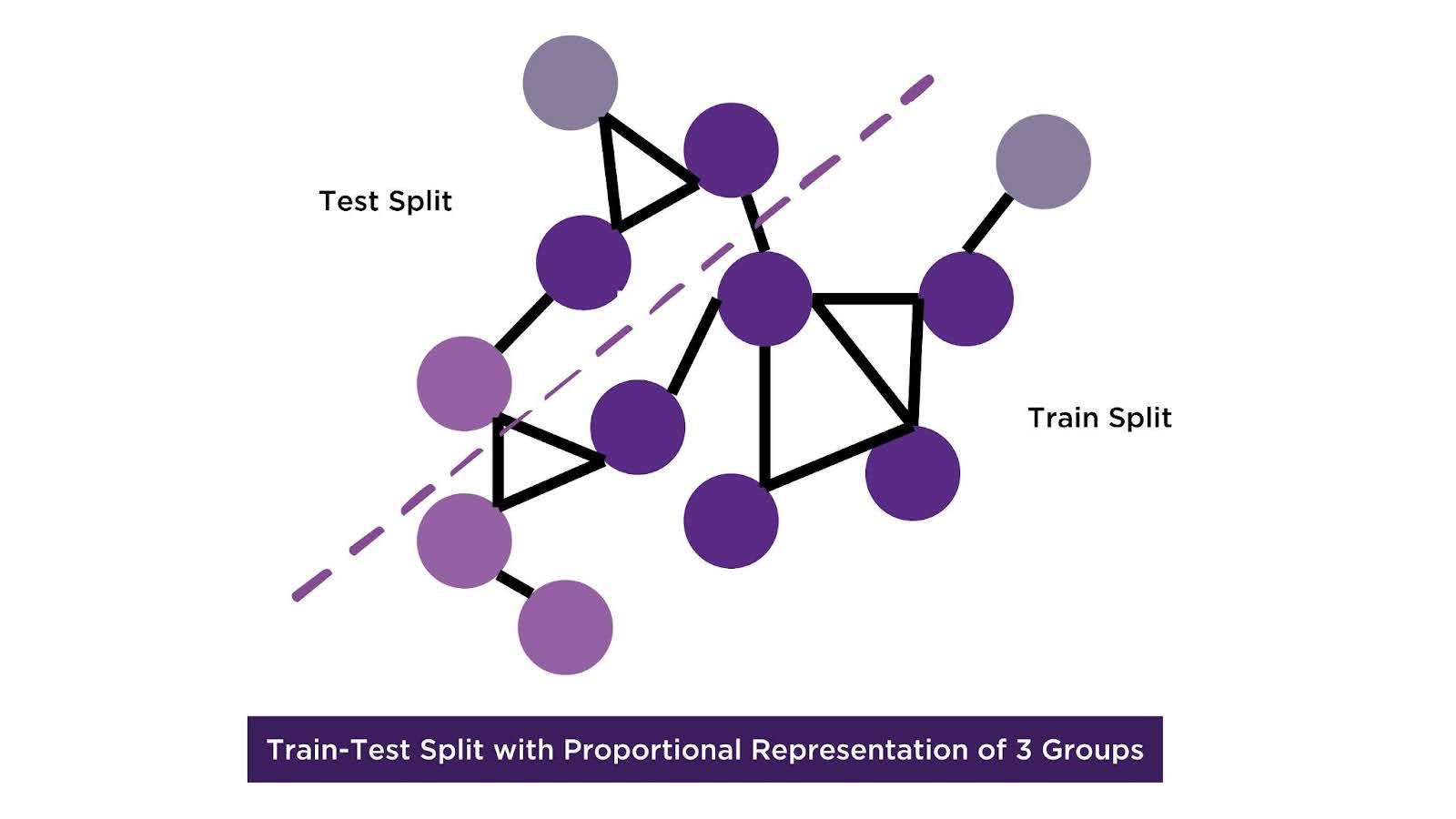
Step 2: Train-Test Split
Subgraph Sampling
Business Value: Basic train-test splitting methods sample instances without regard to connectivity, which can sever critical network links, so subgraph sampling ensures the test set reflects the overall graph structure, allowing models to learn and generalize from complex relationships present in real-world data.
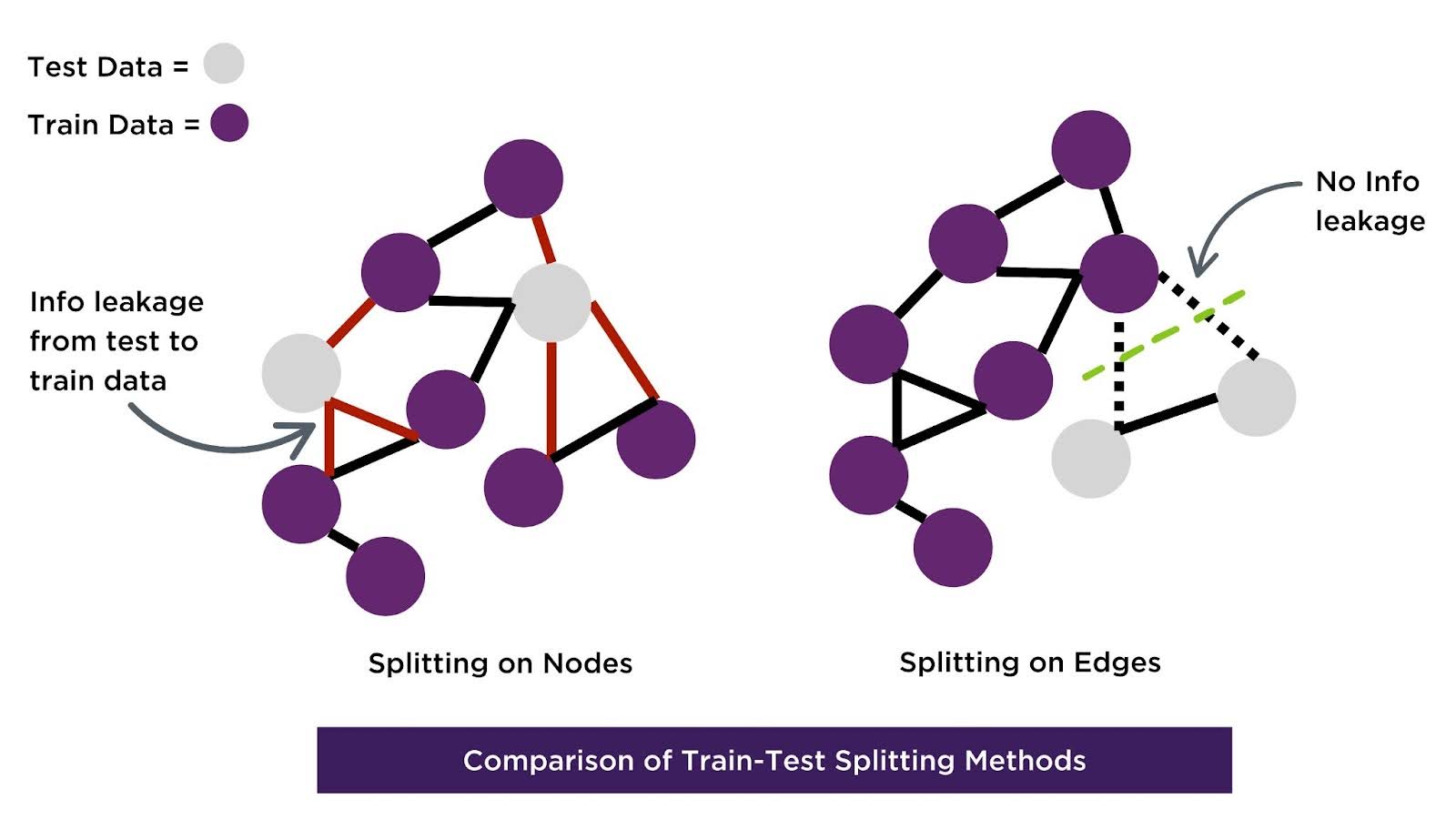
Subgraph sampling is an essential part of graph machine learning, as it ensures the test set is representative of the entire graph structure by sampling subgraphs that reflect the entities and relationships in the overall graph. In traditional ML, splitting data into training and test sets is straightforward because data points are often independent, but graph data introduces dependencies between nodes. Complex graph data captures interconnected relationships such as communities, hierarchies, and long-range dependencies that traditional models would overlook. Subgraph sampling preserves these relationships, enabling the model to learn from the complex structures and generalize better to unseen data. By capturing these dependencies in the train-test split, the model maintains a more complete understanding of how entities interact, allowing it to make better predictions in cases where the relationships between data points are key, such as social network analysis or fraud detection. This careful sampling also highlights the need to address potential overlaps in relationships, which leads us into the next critical consideration: Link Leakage.
Link Leakage
Business Value: Random or node-based splitting can place connected nodes across sets, allowing information to leak via edges. Edge-based splitting prevents information leakage between training and test sets, preserving the integrity of graph relationships and delivering reliable, unbiased predictions.
Link leakage occurs when connections between nodes in the training data indirectly reveal information about the test data. Traditional ML doesn’t face this issue because data points are independent, but in graph ML, relationships between nodes can lead to unintended overlap between the training and test sets. To mitigate this, consider splitting the data by edges to ensure that the test set remains independent of the training set’s connections. Splitting on edges maintains the graph’s inherent relational information, which is a crucial advantage of graph data. This method allows the model to learn from the complex interdependencies within the graph, leading to more accurate predictions in real-world applications like fraud detection or recommendation systems. It also helps avoid biases that may arise from overlapping connections, enhancing the overall reliability of the model. This edge-based approach is vital in graph ML, where traditional methods fall short in addressing these complex dependencies. With a robust solution for link leakage in place, we are now ready to transition into the next major phase: Step 3, Model Training.
Step 3: Model Training
Business Value: Conventional ML models treat instances independently and can’t model dependencies across entities, so graph-specific algorithms capture complex dependencies and relationships that traditional ML models often overlook, enabling deeper insights and more accurate predictions for tasks driven by connections.
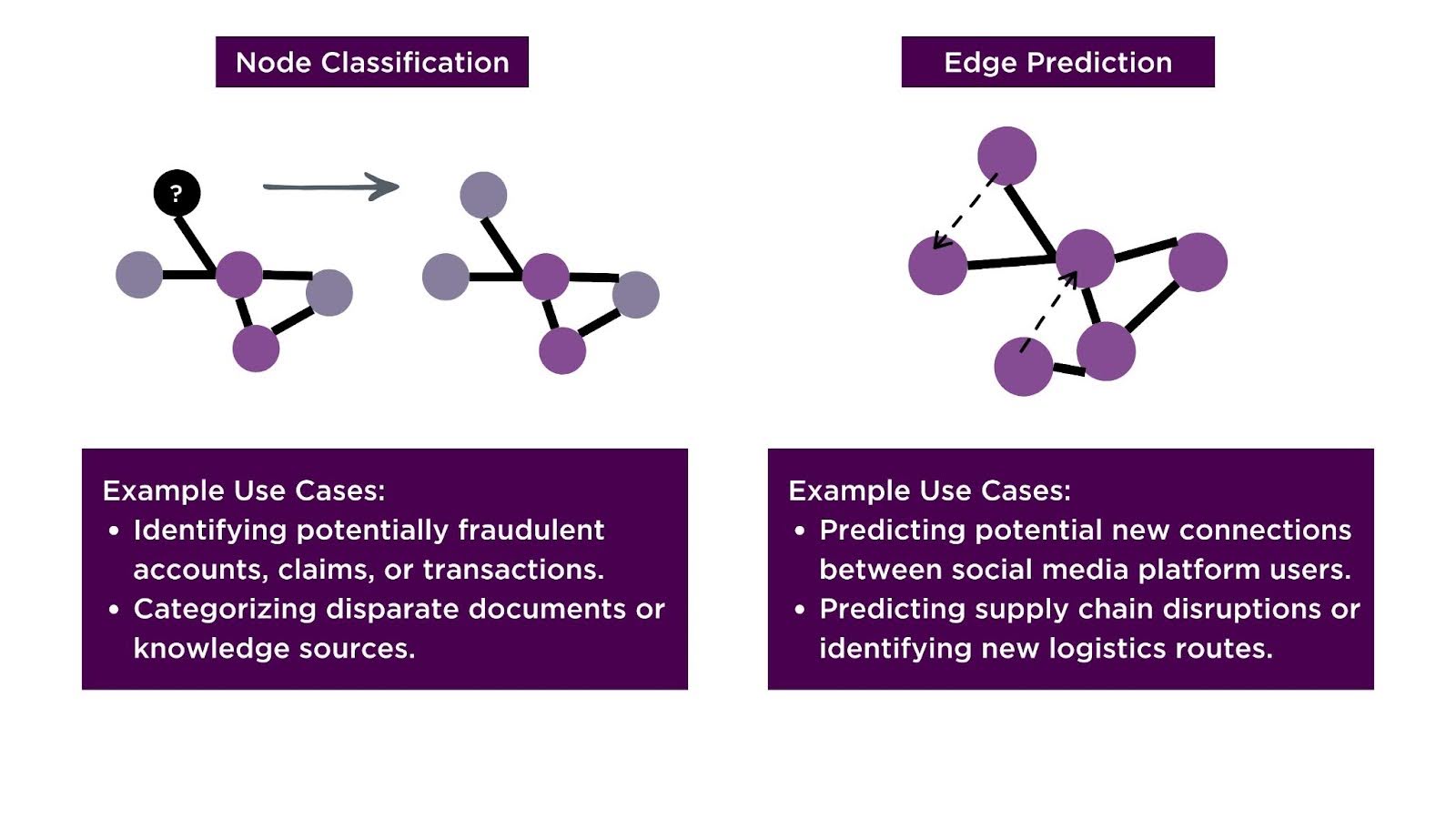
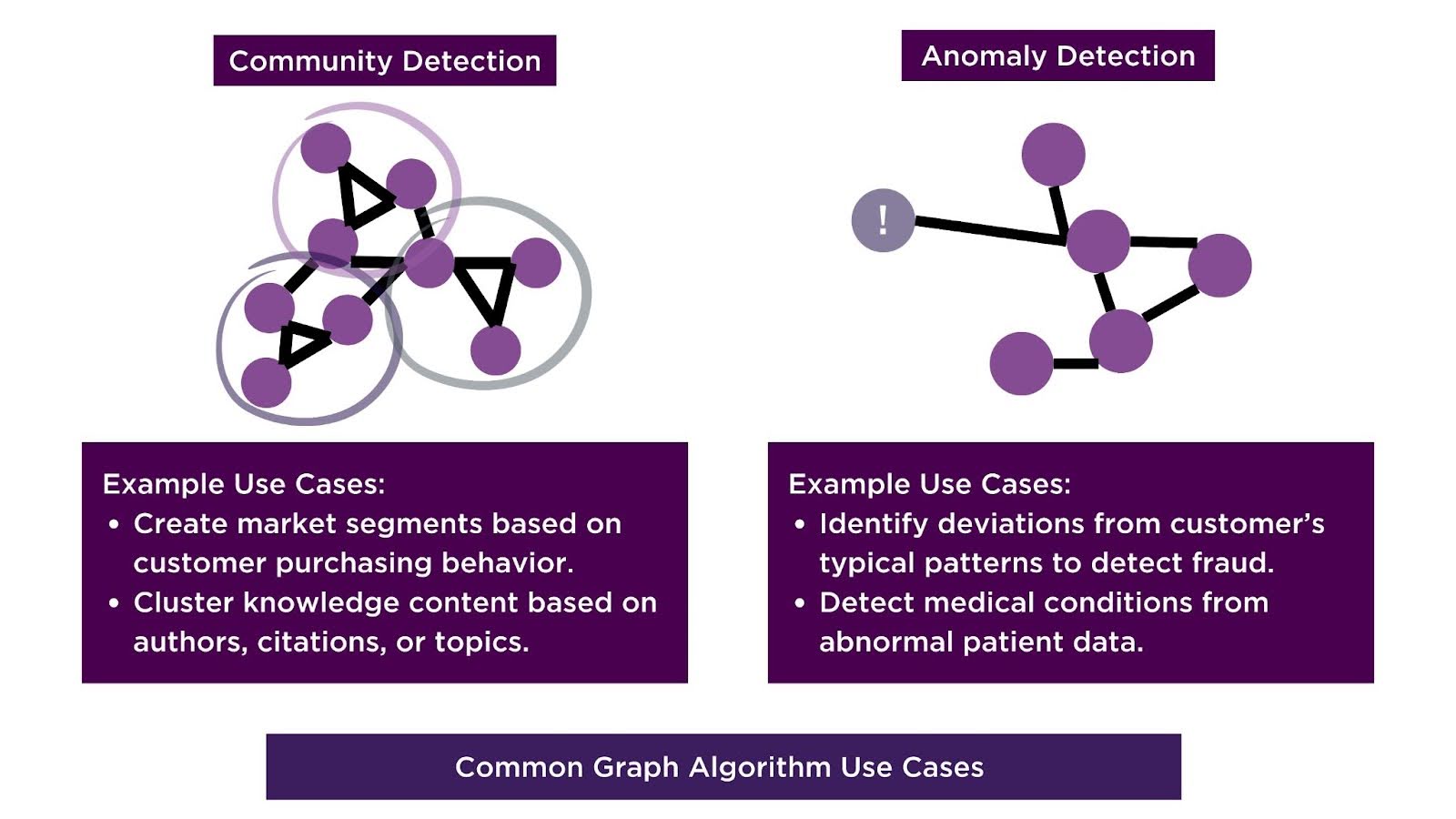
Using algorithms designed specifically for graph data allows you to fully leverage the unique relationships and structures present in graph data, such as the connections between nodes, the importance of specific relationships, and the overall topology of the graph. Traditional ML models, such as decision trees or linear regression, assume that data points are independent and often fail to capture complex dependencies. In contrast, graph algorithms—like node classification, edge prediction, community detection, and anomaly detection—are built to capture the interdependencies between nodes, edges, and their neighbors. These algorithms can uncover patterns and dependencies that are hidden from traditional approaches, such as identifying key influencers in a network or detecting anomalies based on unusual connections between entities.
By utilizing graph algorithms, you can gain deeper insights and make more accurate predictions, especially in tasks where relationships between entities play a critical role, such as fraud detection, recommendation systems, or social network analysis. These insights, driven by the relational data that graph models are designed to exploit, give graph ML a clear advantage when interactions between entities drive outcomes. Following model training, it is essential to evaluate the performance of these specialized models.
Step 4: Model Evaluation
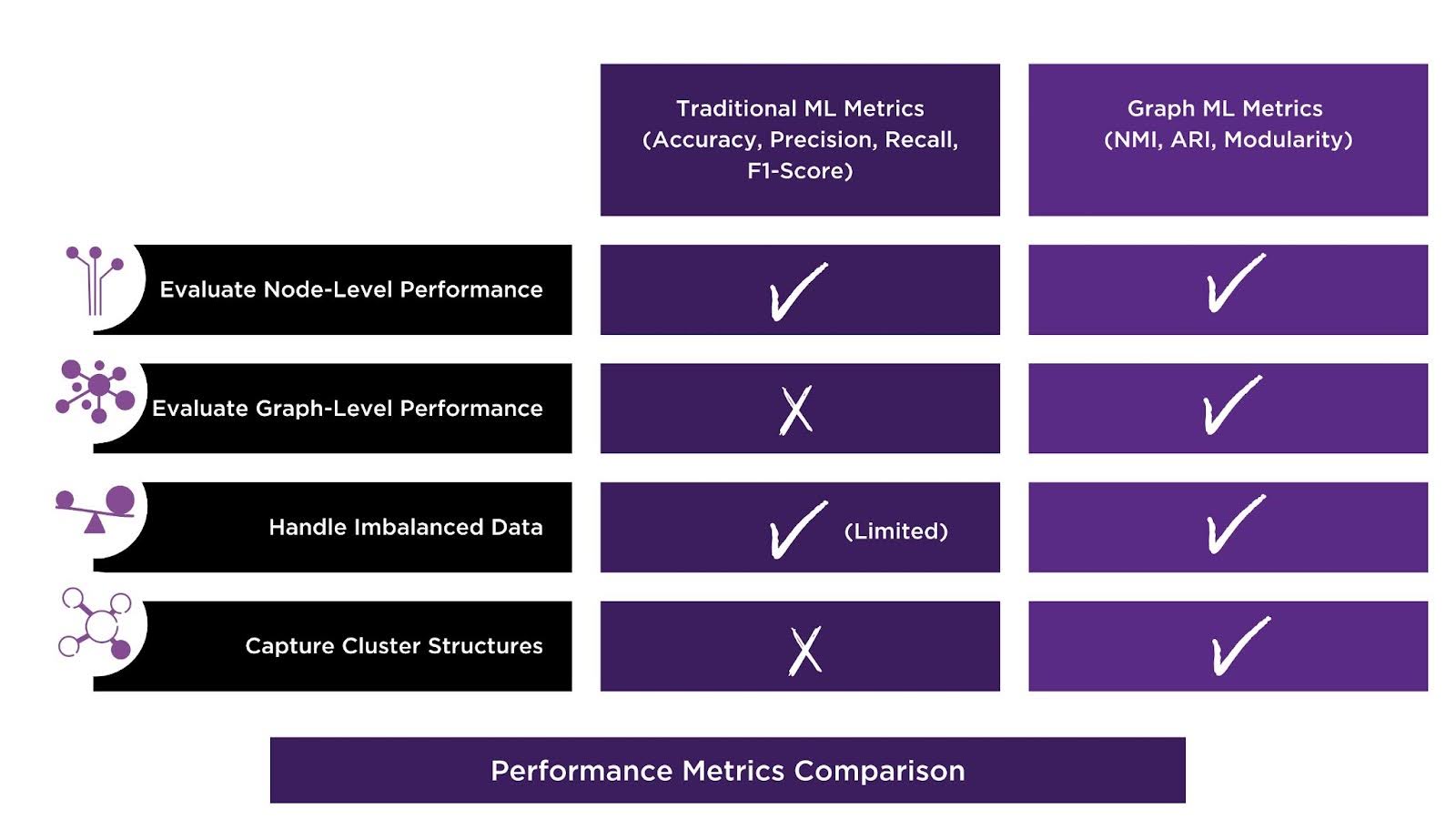
Business Value: Standard evaluation metrics measure prediction independently and ignore graph structure. However, graph-specific metrics offer a more nuanced assessment of graph model performance, capturing structural relationships that traditional metrics overlook.
While common performance metrics apply broadly to most graph ML use cases, there are also specialized metrics for graph ML—such as Normalized Mutual Information (NMI), Adjusted Rand Index (ARI), and Modularity. Traditional ML evaluation metrics like accuracy or F1-score work well for independent data points, but they don’t fully capture the nuances of graph structures, such as community detection or link prediction. Graph-specific performance metrics provide a more nuanced evaluation of models, ensuring that the unique aspects of graph structures are effectively measured and optimized. When you are evaluating a graph ML model, you are able to determine model performance with enhanced structural awareness, contextual evaluation, and imbalanced data handling—areas where traditional ML metrics often fall short.
Graph ML Solution Components
To implement Graph ML successfully, an organization needs a cohesive set of features that support the entire graph workflow. At a minimum, you must have:
(1) a scalable graph storage layer that can ingest and index heterogeneous data sources (including batch and streaming updates) while enforcing a flexible schema;
(2) a pre-processing engine capable of automatically extracting and managing entity and relationship attributes (e.g., generating node and edge-level features);
(3) integrated support for generating and storing graph embeddings and/or handcrafted graph features (such as centrality scores, community assignments, or path-based statistics);
(4) a library of graph algorithms and GNN (Graph Neural Network) frameworks that can train on large-scale graphs, ideally with GPU-acceleration and distributed compute options;
(5) real-time inference capabilities that preserve graph connectivity (so predictions like link-forecasting or node classification remain aware of the surrounding network);
(6) visualization and exploration tools that let data teams inspect subgraphs, feature distributions, and model explainability outputs; and
(7) robust security, access controls, and lineage tracking to ensure data governance across the graph pipeline.
Case Studies – Adapt and Overcome
Bioscience Technology Provider Case Study
With the methodology now established, let’s take a look at a real-world situation. A leading bioscience technology provider’s e-commerce platform struggled to connect its 70,000 products and related educational content–each siloed across more than five different systems–using only keyword search, so we applied the same GraphML workflow outlined above to bridge those gaps. We ingested data from their various platforms into an in-memory knowledge graph, generated vector embeddings to capture content relationships, and trained a custom link-prediction model (sampling known product-content links rather than enforcing link-leakage controls) to infer new connections. The resulting similarity-index and link-classifier views were delivered via an interactive dashboard, validated through human-in-the-loop sessions, and backed by comprehensive documentation and a repeatable AI validation framework. While we skipped graph-specific metrics (favoring standard ML measure like AUC, precision, and recall) to accelerate delivery, this guideline-driven approach demonstrates how the techniques in this blog can be pragmatically adapted to real-world constraints.
Occupational Safety Government Agency
Another applied use case revolves around an occupational safety government agency. Enterprise Knowledge prototyped a semantic recommender that could infer potential workplace hazards from diverse site features–taxonomy values, structured historical datasets, and thousands of unstructured incident reports–so planners could rapidly assess risks and compliance requirements. We began by designing a custom taxonomy and ontology to model construction site elements and regulations, then processed data with zero-shot NLP on a distributed GPU cluster and loaded everything into an RDF knowledge graph. From there we generated vector embeddings and trained a custom edge-prediction classifier to link scenarios to likely risks, deploying the results in a cloud-hosted web app. Guided by performance metrics on a held-out test set, each step was iteratively refined through user feedback and expert workshops. EK maintained continuous collaboration with agency experts through regular design sessions and concluded with a detailed technical walkthrough to ensure transparency and client buy-in. Backed by detailed documentation and a clear roadmap for expanding feedback loops and analysis dimensions, this solution underscores that the GraphML lifecycle is a flexible framework–teams should tailor or simplify steps as needed to align with real-world constraints like timelines, data availability, and resource limits.
Conclusion
Graph machine learning offers a transformative approach to working with complex, interconnected datasets. By leveraging graph-specific techniques like feature extraction, compression, and graph algorithms, you can unlock deeper insights that go beyond what traditional ML can achieve. Whether it’s in community detection, fraud prevention, or recommendation systems, graph ML provides a way to model relationships and structures that traditional methods often miss. As we move toward a future where graph technologies are increasingly integrated into data workflows, it’s clear that understanding and applying these methods can lead to more accurate predictions, better decision-making, and ultimately, a competitive edge. If you’re interested in unlocking the potential of graph ML for your organization, contact EK to learn more!