
In my previous post, I described Enterprise Knowledge Graphs and their importance to today’s organization. Now that we understand the value of Enterprise Knowledge Graphs, I want to address questions like how we create one for a specific organization, where do we begin, and what factors we should consider. The topic is extensive and could fill a book, but below are the highlights.
While the process of designing, implementing, and leveraging your Enterprise Knowledge Graph may seem daunting at first, Rome was not built in a day. This is one of the reasons we recommend to our clients that they start small and iterate. Knowledge graphs are not just another application or database. They are, and should be, a core component of your operations, a way of understanding and leveraging your comprehensive organizational information to help you with your business. They are not the destination. They are a critical tool in the path to improving your efficiency, decision making, and competitive advantage.
In this article, I will address the following key aspects of building an Enterprise Knowledge Graph (EKG):
- Define the business purpose of the EKG
- Three-layer view:
- Data Ingestion and Integration
- Ontology
- ETL v. Data-in-place access
- Data Storage
- Knowledge Consumption
- Data Ingestion and Integration
We begin with the defining purpose.
What is the Purpose of Your Enterprise Knowledge Graph?
The first step in building a comprehensive, efficient, and relevant knowledge graph is to determine what is the problem it is intended to solve. Is it intended to be the base for a chatbot application in a specific domain, for example, a support desk? Is it targeted toward defining and discovering experts and expertise in an organization? Or is it supposed to support one, unified enterprise semantic search?
Even more narrowly, what are the business questions that the knowledge graph should be able to answer? Do we want to find the person with the best matched skills for a new project we are starting? Or are we interested in providing recommendations based on interests, user activities, employee seniority, role, etc.?
The intended purpose of an Enterprise Knowledge Graph will help us define what data sources should be ingested and how the data should be integrated, i.e., how the semantic data model will be designed.
At EK, we conduct a series of workshops and focus groups with key stakeholders to elicit and agree on the answers to the questions above. With that, we can now turn toward the more technical piece.
Three Key Layers
At a high level, there are three key layers to help us dissect an Enterprise Knowledge Graph. Data Ingestion and Integration, Data Storage, and Knowledge Consumption. Here we will focus more on the first step and only highlight key concepts in the latter steps. Below is a simplified logical diagram highlighting the general key components that we will discuss here:
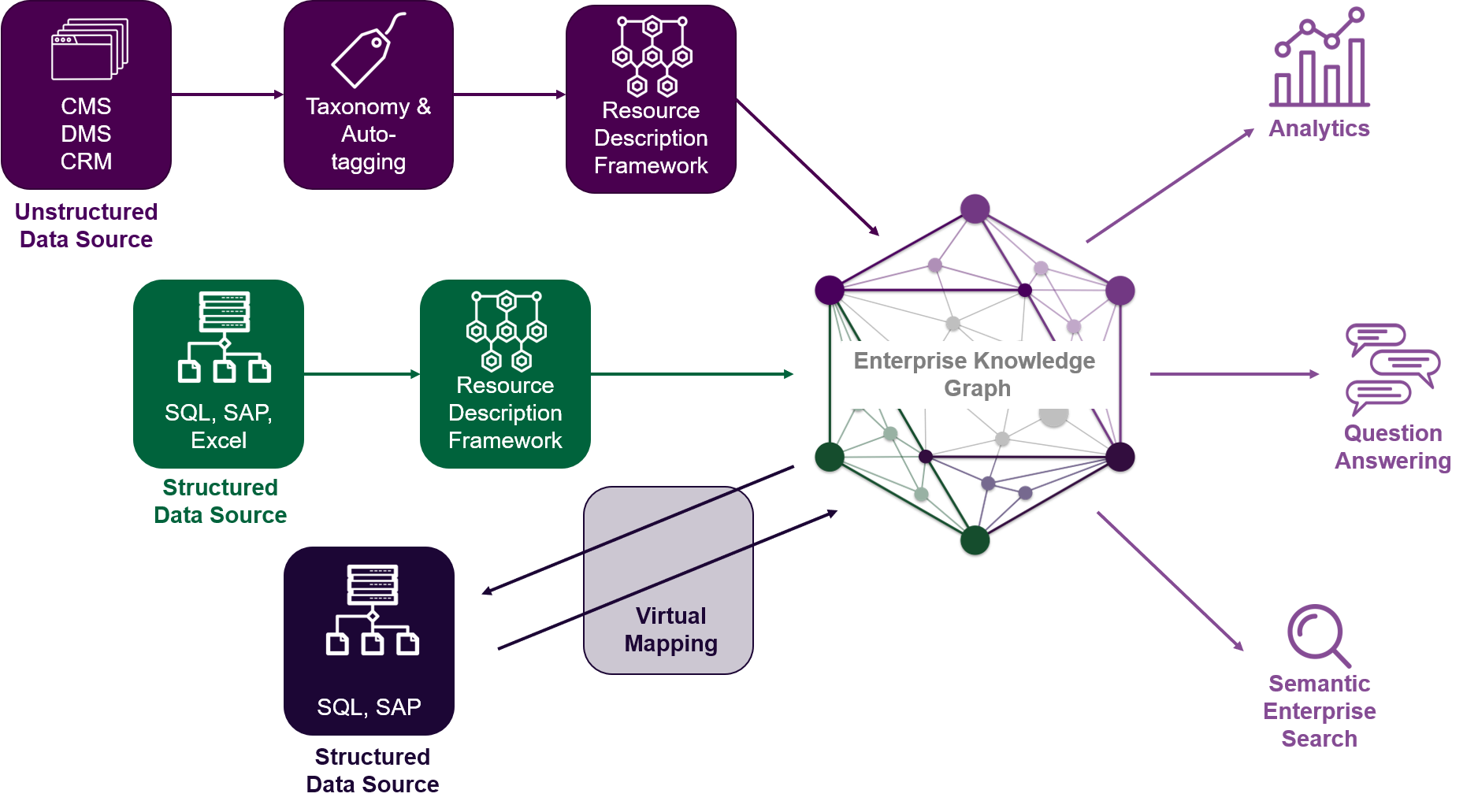
1. Data Ingestion and Integration
Having determined the purpose of our Enterprise Knowledge Graph, we next need to determine and prioritize the information that should be included in the graph so that it can provide answers to the business questions we previously defined. Should we include all data sources we have throughout the organization, or should we focus on a specific domain? When working with our clients, we recommend starting small, prioritizing the data sources, and growing the knowledge graph iteratively.
As part of this data ingestion process, there are two main pieces to address:
Knowledge Graph Schema (Ontology)
This is where we need to start designing and implementing the semantic data model (ontology) for our Enterprise Knowledge Graph. In previous articles, namely Ontology Design Best Practices (Part 1 and Part 2), we’ve provided key suggestions to help you with your ontology design. The goal of an ontology is to allow us to add meaning to the data in the knowledge graph. Building a sound ontology will provide the basis for implementing advanced applications later that can query and understand the data, discover explicitly defined facts (relationships between entities), as well as leverage the power behind inference and reasoning.
A key consideration when designing your ontology is whether you start from scratch and build a highly custom model specifically geared for your organization’s domain, or you instead investigate and leverage pre-defined ontologies that are widely used and then enhance them to fit your needs. In our approach, we commonly start by reviewing common public ontologies like FOAF, GEO, ORG, and schema.org to determine their alignment with the specific use case we are working on. We then leverage these ontologies and the organization’s business taxonomy to develop a tailored model for our client organizations. This approach allows us to ensure data interoperability, especially for publicly facing systems and sites, as well as a well-fitting model that can answer the business questions we started with.
Data Ingestion
Once we have a model for our graph, we can apply it to incoming data so that we can ensure quality and consistency of the knowledge graph. But before we start populating the graph with data, we need to make some decisions on the process and methods of doing that.
ETL v. Data-in-place (Virtual Graph)
One of the first considerations we need to address is whether to actually import data and content (or references to those) in the graph database, or keep it in-place in its source system and only provide a map for the graph to access that data. Here are some thoughts on each:
ETL Approach
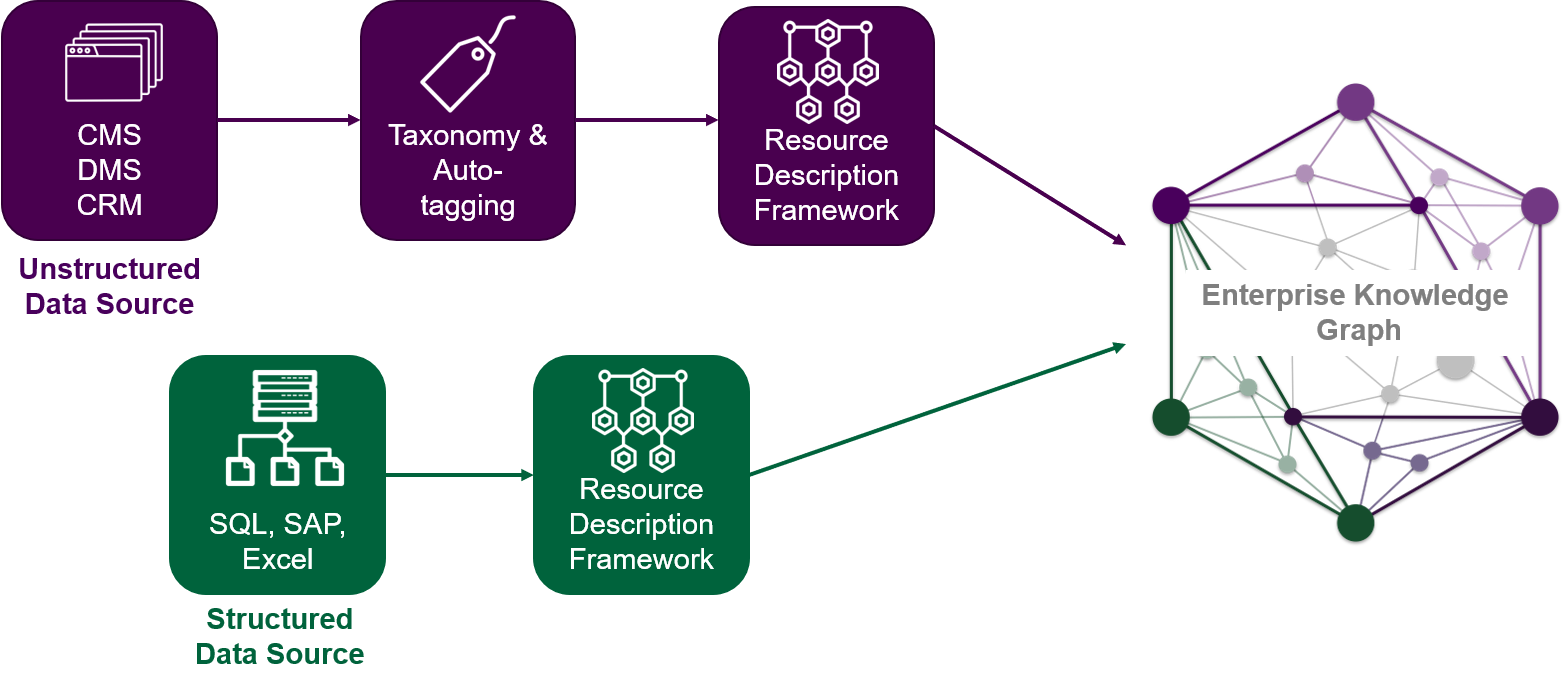
In simple terms, the ETL (Extract, Transform, Load) approach establishes a repeatable process to extract relevant content from a source system on a regular basis, and populate and update the Enterprise Knowledge Graph accordingly. With this process, we identify relevant data or content from a data source, transform it to native graph data representation, i.e., RDF (Resource Definition Framework), and load it in the graph database.
There are two additional steps in this process: apply semantic tags, and apply the ontology before the data is loaded in the graph database. The purpose of applying semantic tags to incoming content or data is to provide additional context for information coming in the graph. In combination with applying the ontology, we can now tell that Rome is actually a geographic location, specifically a city. Depending on what else we know about Rome in the graph already, we may later be able to tell that it is the capital of Italy and other facts about it that may have come from other data sources. We work with market-leading software tools that have matured in the last few years to allow us to manage this process from start to end, from taxonomy definition, to auto-tagging, ontology management, and converting content to RDF, among other key functionalities.
The ETL approach is more suited to extracting data from sources of unstructured content, e.g., CMS, DMS, and others, as well as sources that have relatively low update velocity.
Data-in-Place Approach
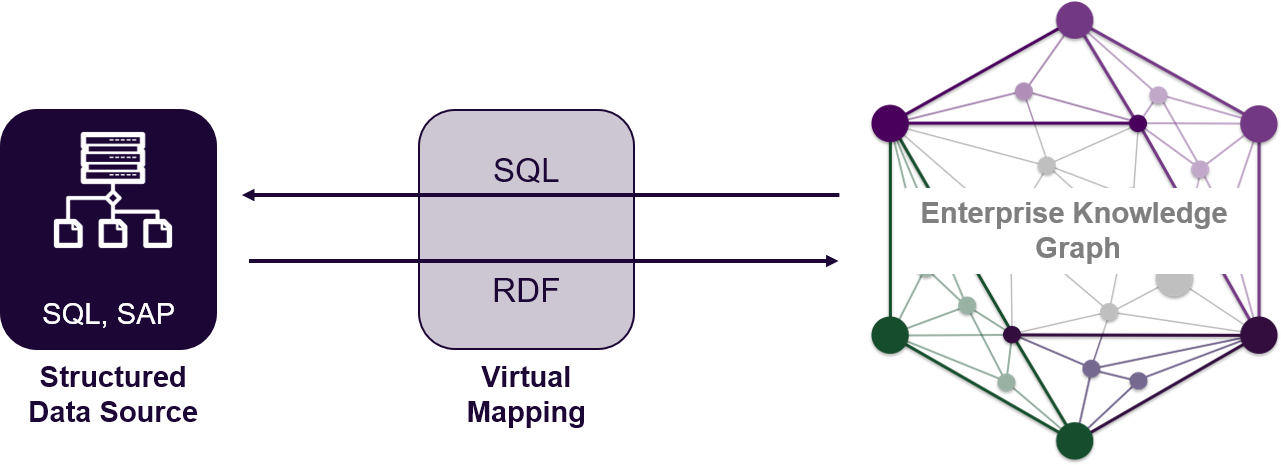
Another approach is leveraging graph database systems that allow you to use virtual graphs. Think of a virtual graph as a mapping from SPARQL (the graph database query language) to SQL. It is a way to tell the graph database that that it can connect to a relational data source, leverage that map, and query the relational database on query-execution time. Thus, you always get the live (or near-live) data from the source itself and there is no duplication of structured data.
The benefit of the virtual graph approach is, of course, freshness of data. This approach is well-suited for connecting to structured data sources like relational database and data sources with high update rate. The downside: potentially degraded performance while querying the external source.
2. Data Storage
There are a variety of graph database platforms on the market, also known as triple stores. For the purposes of knowledge graphs, we generally work with RDF triple stores which are based on W3C standards. In their basic form, they store triples: in simple terms, an entry composed of two entities and the relationship between them.
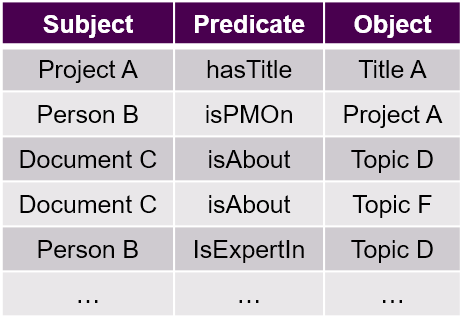
Triple stores can store billions of triples which define each entity in the graph, its attributes, and its relationships to other entities.
Most triple stores cover the basic features and standards like RDF and SPARQL. Depending on your use case and needs, you may want to investigate products specializing in a specific domain like geospatial data, predictive analytics, or even products that are geared specifically toward knowledge graph solutions.
3. Knowledge Consumption
Back to the purpose of our knowledge graph. Now that we have the relevant knowledge integrated in one place (or its first iteration), we can set about implementing the actual end user application that will allow us to discover and extract the true value from our organizational knowledge.
Depending on your use case, whether it is a recommendation engine, cognitive search, question answering service, structured data service, chatbots, or other advanced and AI applications, the Enterprise Knowledge Graph can now be queried with SPARQL to extract explicitly defined relationships between things, places, and people, as well as infer implicit relationships based on various factors like proximity in the graph, transitive properties, and others. You will notice that we are now searching for “things, not strings,” as Google defined it first back in 2012.
Concluding Thoughts
While there are a variety of business use cases for leveraging Enterprise Knowledge Graphs, one of the most common is a semantically enhanced search that improves findability and relevance of your results. The blog “A Knowledge Graph Feast” discusses one example of how we can enhance the traditional search by leveraging an Enterprise Knowledge Graph.
Implementing an effective Enterprise Knowledge Graph is a process, not a result. At EK, we are happy to support your mission. If you are just embarking on the Enterprise Knowledge Graph path, or you have already started and need further assistance with methodology, ontology design, data integration, product selection, or actually implementing the solution, we are here to help.