
Over the course of Enterprise Knowledge’s history, we have been in the business of connecting an organization’s information and data, ensuring it is findable and discoverable, and enriching it to be more useful to both humans and AI. Though use cases, scope, and scale of engagements—and certainly, the associated technologies—have all changed, that core mission has not.
As part of our work, we’ve endeavored to help our clients understand the expansive nature of their knowledge, content, and data. The complete range of these materials can be considered based on several different spectra. They can range from tacit to explicit, knowledge to information, structured to unstructured, digital to analog, internal to external, and originated to generated. Before we go deeper into the definition of knowledge assets, let’s first explore each of these variables to understand how vast the full collection of knowledge assets can be for an organization.
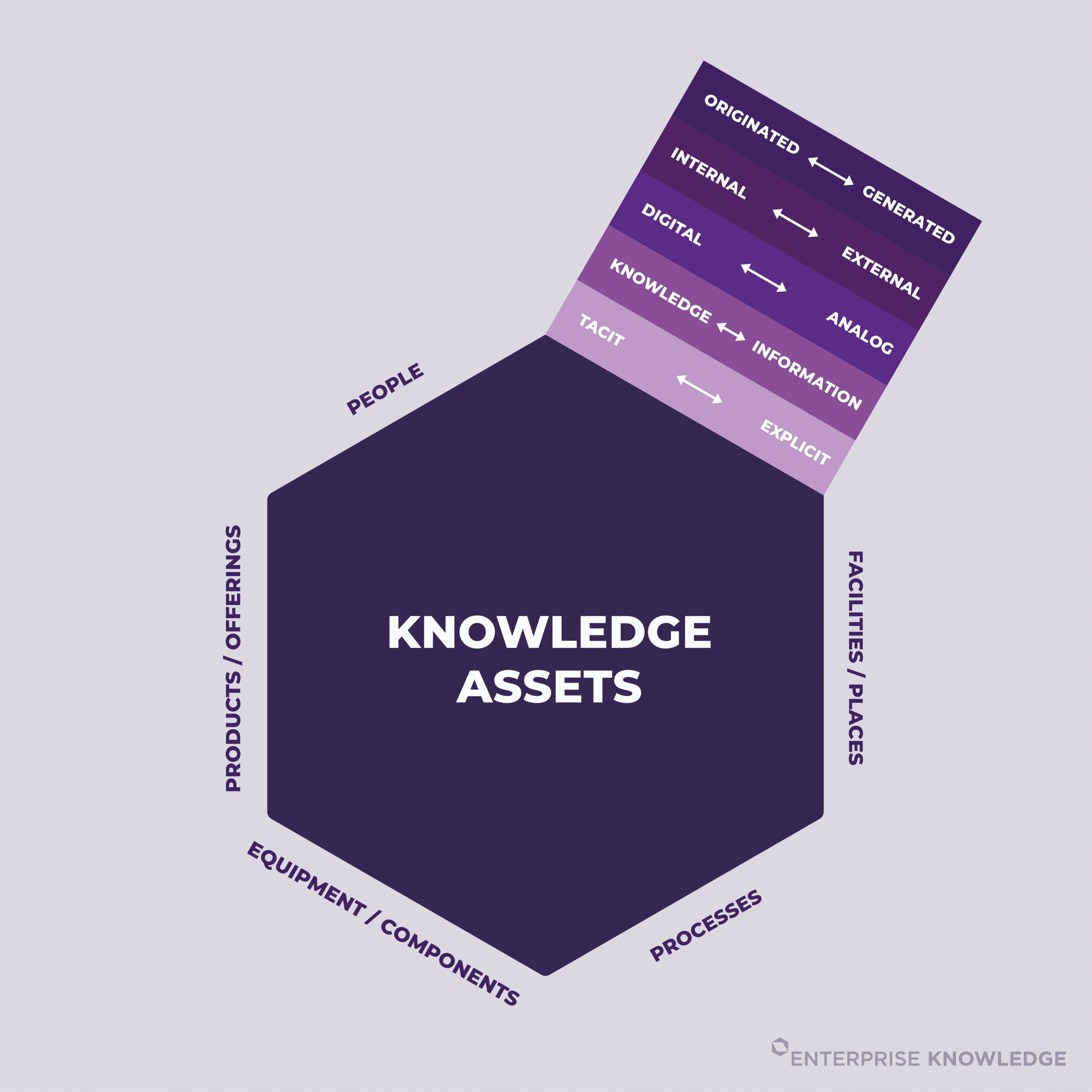
- Tacit and Explicit – Tacit content is held in people’s heads. It is inferred instead of explicitly encoded in systems, and does not exist in a shareable or repeatable format. Explicit content is that which has been captured in an independent form, typically as a digital file or entry. Historically, organizations have been focused on converting tacit knowledge to explicit so that the organization could better maintain and reuse it. However, we’ll explain below how the complete definition of a knowledge asset shifts that thinking somewhat.
- Knowledge and Information – Knowledge is the expertise and experience people acquire, making it extremely valuable but hard to convert from tacit to explicit. Information is just facts, lacking expert context. Organizations have both, and documents often mix them.
- Structured and Unstructured – Structured information is machine-readable and system-friendly and unstructured information is human-readable and context-rich. Structured data, like database entries, is easy for systems but hard for humans to understand without tools. Unstructured data, designed for humans, is easier to grasp but historically challenging for machines to process.
- Digital to Analog – Digital information exists in an electronic format, whereas analog information exists in a physical format. Many global organizations are sitting on mountains of knowledge and information that isn’t accessible (or perhaps even known) to most people in the organization. Making things more complex, there’s also formerly analog information, the many old documents that have been digitized but exist in a middle state where they’re not particularly machine-readable, but are electronic.
- Internal to External – Internal content targets employees, while external content targets customers, partners, or the public, with differing tones and styles, and often greater governance and overall rigor for external content. Both types should align, but are treated differently. You can also consider the content created by your organization versus external content purchased, acquired, or accessed from external sources. From this perspective, you have much greater control over your organization’s own content than that which was created or is owned externally.
- Originated and Generated – Originated content already exists within the organization as discrete items within a repository or repositories, authored by humans. Explicit content, for example, is originated. It was created by a person or people, it is managed, and identified as a unique item. Any file you’ve created before the AI era falls into this category. With Generative AI becoming pervasive, however, we must also consider generated information, derived from AI. These generated assets (synthetic assets) are automatically created based on an organization’s existing (originated) information, forming new content that may not possess the same level of rigor or governance.
If we were to go no further than the above, most organizations would already be dealing with petabytes of information and tons of paper encompassing years and years. However, by thinking about information based on its state (i.e. structured or unstructured, digital or analog, etc), or by its use (i.e. internal or external), organizations are creating artificial barriers and silos to knowledge, as well as duplicating or triplicating work that should be done at the enterprise level. Unfortunately, for most organizations, the data management group defines and oversees data governance for their data, while the content management group defines and oversees content governance for their content. This goes beyond inefficiency or redundancy, creating cost and confusion for the organization and misaligning how information is managed, shared, and evolved. Addressing this issue, in itself, is already a worthy challenge, but it doesn’t yet fully define a knowledge asset or how thinking in terms of knowledge assets can deliver new value and insights to an organization.
 If you go beyond traditional digital content and begin to consider how people actually want to obtain answers, as well as how artificial intelligence solutions work, we can begin to think of the knowledge an organization possesses more broadly. Rather than just looking at digital content, we can recognize all the other places, things, and people that can act as resources for an organization. For instance, people and the knowledge and information they possess are, in fact, an asset themselves. The field of KM has long been focused on extracting that knowledge, with at best mixed results. However, in the modern ecosystem of KM, semantics, and AI, we can instead consider people themselves as the asset that can be connected to the network. We may still choose to capture their knowledge in a digital form, but we can also add them to the network, creating avenues for people to find them, learn from them, and collaborate with them while mapping them to other assets.
If you go beyond traditional digital content and begin to consider how people actually want to obtain answers, as well as how artificial intelligence solutions work, we can begin to think of the knowledge an organization possesses more broadly. Rather than just looking at digital content, we can recognize all the other places, things, and people that can act as resources for an organization. For instance, people and the knowledge and information they possess are, in fact, an asset themselves. The field of KM has long been focused on extracting that knowledge, with at best mixed results. However, in the modern ecosystem of KM, semantics, and AI, we can instead consider people themselves as the asset that can be connected to the network. We may still choose to capture their knowledge in a digital form, but we can also add them to the network, creating avenues for people to find them, learn from them, and collaborate with them while mapping them to other assets.
In the same way, products, equipment, processes, and facilities can all be considered knowledge assets. By considering all of your organizational components not as “things,” but as containers of knowledge, you move from a world of silos to a connected and contextualized network that is traversable by a human and understandable by a machine. We coined the term knowledge assets to express this concept. The key to a knowledge asset is that it can be connected with other knowledge assets via metadata, meaning it can be put into the organization’s context. Anything that can hold metadata and be connected to other knowledge assets can be an asset.

Another set of knowledge assets that are quickly becoming critical for mature organizations are components of AI orchestration. As organizations build increasingly complex systems of agents, models, tools, and workflows, the logic that governs how these components interact becomes a form of operational knowledge in its own right. These orchestration components encode decisions, institutional context, and domain expertise, meaning they are worthy of being treated as first-class knowledge assets. To fully harness the value of AI, orchestration components should be clearly defined, governed, and meaningfully connected to the broader knowledge ecosystem.
Put into practice, a mature organization could create a true web of knowledge assets to serve virtually any use case. Rather than a simple search, a user might instead query their system to learn about a process. Instead of getting a link to the process documentation, they get a view of options, allowing them to read the documentation, speak to an expert on the topic, attend training on the process, join a community of practice working on it, or visit an application supporting it.
A new joiner to your organization might be given a task to complete. Currently, they may hunt around your network for guidance, or wait for a message back from their mentor, but if they instead had a traversable network of all your organization’s knowledge assets, they could begin with a simple search on the topic of the task, find a past deliverable from a related task, which would lead them to the author of that task from whom they could seek guidance, or instead to an internal meetup of professionals deemed to have expertise in that task.
If we break these silos down, add context and meaning via metadata, and begin to treat our knowledge assets holistically, we’re also creating the necessary foundations for any AI solutions to better understand our enterprise and deliver complete answers. This means that we’re building the better answer for our organization immediately, while also enabling our organization to leverage AI capabilities faster, more consistently, and more reliably than others.
The idea of knowledge assets will be a shift both in mindset and strategies, with impacts potentially rippling deeply through your org chart, technologies, and culture. However, the organizations that embrace this concept will achieve an enterprise most closely resembling how humans naturally think and learn and how AI is best equipped to deliver.
If you’re ready to take the next big step in organizational knowledge and maturity, contact us, and we will bring all of our knowledge assets to bear in support.