
In a recent blog post, my colleague Joe Hilger described how a knowledge graph can be used in conjunction with a componentized content management system (CCMS) to provide personalized content to customers. This post will show the example data from Hilger’s post being loaded into a knowledge graph and queried to find the content appropriate for each customer, using Python and the rdflib package. In doing so, it will help make these principles more concrete, and help you in your journey towards content personalization.
To follow along, a basic understanding of Python programming is required.
Aggregating Data
Hilger’s article shows the following visualization of a knowledge graph to illustrate how the graph connects data from many different sources and encodes the relationship between them.
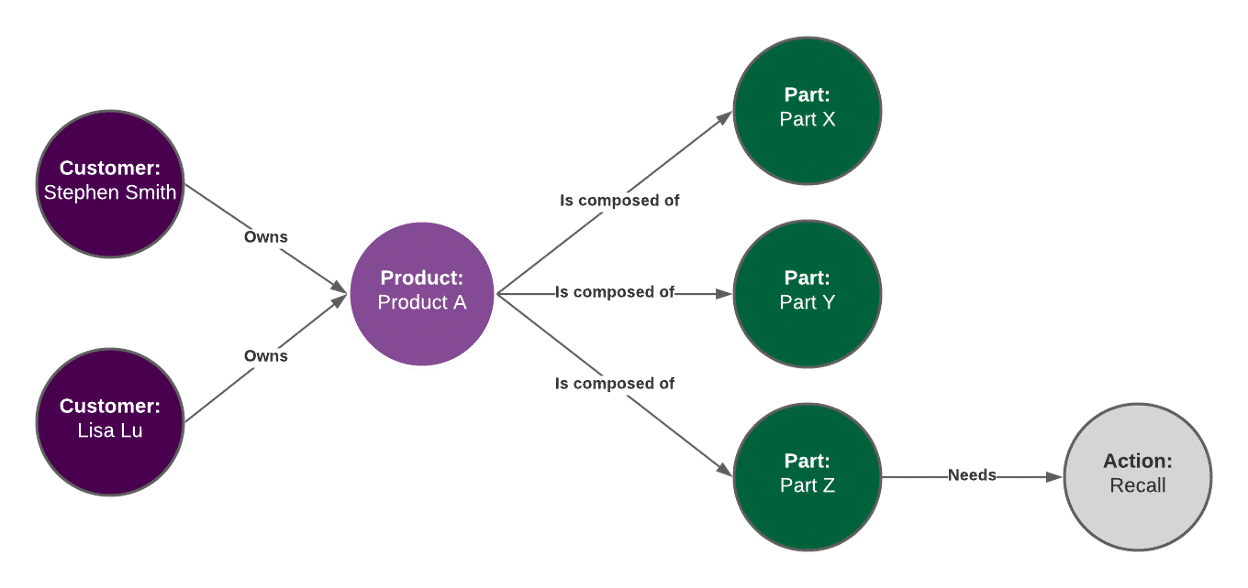
To show this system in action, we will start out with a few sets of data about:
- Customers and the products they own
- Products and the parts they are composed of
- Parts and the actions that need to be taken on them
In practice, this information would be pulled from the sales tracking, product support, and other systems it lives in via APIs or database queries, as described by Hilger.
customers_products = [
{"customer": "Stephen Smith", "product": "Product A"},
{"customer": "Lisa Lu", "product": "Product A"},
]
products_parts = [
{"product": "Product A", "part": "Part X"},
{"product": "Product A", "part": "Part Y"},
{"product": "Product A", "part": "Part Z"},
]
parts_actions = [{"part": "Part Z", "action": "Recall"}]
We will enter this data into a graph as a series of subject-predicate-object triples, each of which represents a node (the subject) and its relationship (the predicate) to another node (the object). RDF graphs use uniform resource identifiers (URIs) to provide a unique identifier for both nodes and relationships, though an object can also be a literal value.
Unlike the traditional identifiers you may be used to in a relational database, URIs in RDF always use a URL format (meaning they begin with http://), although a URI is not required to point to an existing website. The base part of this URI is referred to as a namespace, and it’s common to use your organization’s domain as part of this. For this tutorial we will use http://example.com as our namespace.
We also need a way to represent these relationship predicates. For most enterprise RDF knowledge graphs, we start with an ontology, which is a data model that defines the types of things in our graph, their attributes, and the relationships between them. For this example, we will use the following relationships:
| Relationship | URI |
| Customer’s ownership of a product | http://example.com/owns |
| Product being composed of a part | http://example.com/isComposedOf |
| Part requiring an action | http://example.com/needs |
Note the use of camelCase in the name – for more best practices in ontology design, including how to incorporate open standard vocabularies like SKOS and OWL into your graph, see here.
The triple representing Stephen Smith’s ownership of Product A in rdflib would then look like this, using the URIRef class to encode each URI:
from rdflib import URIRef
triple = (
URIRef("http://example.com/Stephen_Smith"),
URIRef("http://example.com/owns"),
URIRef("http://example.com/Product_A"),
)
Because typing out full URLs every time you want to add or reference a component of a graph can be cumbersome, most RDF-compliant tools and development resources provide some shorthand way to refer to these URIs. In rdflib that’s the Namespace module. Here we create our own namespace for example.com, and use it to more concisely create that triple:
from rdflib import Namespace
EG = Namespace("http://example.com/")
triple = (EG["Stephen_Smith"], EG["owns"], EG["Product_A"])
We can further simplify this process by defining a function to transform these strings into valid URIs using the quote function from the urlparse module:
from urllib.parse import quote
def create_eg_uri(name: str) -> URIRef:
"""Take a string and return a valid example.com URI"""
quoted = quote(name.replace(" ", "_"))
return EG[quoted]
Now, let’s create a new Graph object and add these relationships to it:
from rdflib import Graph
graph = Graph()
owns = create_eg_uri("owns")
for item in customers_products:
customer = create_eg_uri(item["customer"])
product = create_eg_uri(item["product"])
graph.add((customer, owns, product))
is_composed_of = create_eg_uri("isComposedOf")
for item in products_parts:
product = create_eg_uri(item["product"])
part = create_eg_uri(item["part"])
graph.add((product, is_composed_of, part))
needs = create_eg_uri("needs")
for item in parts_actions:
part = create_eg_uri(item["part"])
action = create_eg_uri(item["action"])
graph.add((part, needs, action))
Querying the Graph
Now we are able to query the graph, in order to find all of the customers that own a product containing a part that requires a recall. To do this, we’ll construct a query in SPARQL, the query language for RDF graphs.
SPARQL has some features in common with SQL, but works quite differently. Instead of selecting from a table and joining others, we will describe a path through the graph based on the relationships each kind of node has to another:
sparql_query = """SELECT ?customer ?product
WHERE {
?customer eg:owns ?product .
?product eg:isComposedOf ?part .
?part eg:needs eg:Recall .
}"""
The WHERE clause asks for:
- Any node that has an owns relationship to another – the subject is bound to the variable
?customerand the object to?product - Any node that has an isComposedOf relationship to the
?productfrom the previous line, the subject of which is then bound to?part - Any node where the object has a needs relationship to an object which is a Recall.
Note that we did not at any point tell the graph which of the URIs in our graph referred to a customer. By simply looking for any node that owns something, we were able to find the customers automatically. If we had a requirement to be more explicit about typing, we could add triples to our graph describing the type of each entity using the RDF type relationship, then refer to these in the query.
We can then execute this query against the graph, using the initNs argument to map the “eg:” prefixes in the query string to our example.com namespace, and print the results:
results = graph.query(sparql_query, initNs={"eg": EG})
for row in results:
print(row)
This shows us the URIs for the affected customers and the products they own:
(rdflib.term.URIRef('http://example.com/Stephen_Smith'), rdflib.term.URIRef('http://example.com/Product_A'))
(rdflib.term.URIRef('http://example.com/Lisa_Lu'), rdflib.term.URIRef('http://example.com/Product_A'))
These fields could then be sent back to our componentized content management system, allowing it to send the appropriate recall messages to those customers!
Summary
The concepts and steps described in this post are generally applicable to setting up a knowledge graph in any environment, whether in-memory using Python or Java, or with a commercial graph database product. By breaking your organization’s content down into chunks inside a componentized content management system and using the graph to aggregate this data with your other systems, you can ensure that the exact content each customer needs to see gets delivered to them at the right time. You can also use your graph to create effective enterprise search systems, among many other applications.
Interested in best in class personalization using a CCMS plus a knowledge graph? Contact us.