
The volume of information organizations have available to them is far exceeding their ability to make sense of it all. A big part of the problem is the fact that enterprise data is scattered, disconnected and represented in inconsistent forms. In this article, we explore the role of Entity Resolution in the Semantic Layer as a means to bring enterprise data into context. Information in context, delivered via the Semantic Layer, allows organizations to make better decisions faster – across lines of business; whether the customer is facing decisions or optimizing operations.
In this blog, Lulit Tesfaye and Jeff Jonas discuss typical problems that would necessitate Entity Resolution, how to unify enterprise data with a Semantic Layer, and the role of entity-resolved knowledge graphs, all while bringing in real case studies and applications. Meet our experts!
- Lulit Tesfaye is a Partner and the VP for Knowledge & Data Services and Engineering at Enterprise Knowledge, LLC., the largest global consultancy dedicated to knowledge and information management. Lulit brings over 15 years of experience leading diverse information and data management initiatives, specializing in technologies and integrations. Lulit is most recently focused on employing advanced Enterprise AI and semantic capabilities for optimizing enterprise data and information assets.
- Jeff Jonas, founder and CEO of Senzing, is a data scientist and developer of entity resolution systems. Jonas sold his previous company to IBM in 2005, subsequently becoming an IBM Fellow and Chief Scientist of Context Computing at IBM. National Geographic has recognized him as the “Wizard of Big Data.” Jonas is most recently focused on bringing entity resolution to the graph community, unlocking the true potential of knowledge graphs in the form of Entity Resolved Knowledge Graphs (ERKG).

Typical Problems
1 |
Case 1: A global digital marketing initiative has accumulated (and continues to ingest) billions of records for only 240 million marketable households in the United States. Customer data is compiled from multiple storefronts and various touchpoints, including online purchases, in-store transactions, loyalty programs, etc. This data is ingested with variations in spelling, abbreviations, or slight differences in information (e.g., “Bob Smith” vs. “Robert Smith” or “123 Main St” vs. “123 Main Street”). The typos, misspellings, missing data, and incorrect information has made it an arduous task to associate records for real-world customers and gain a 360-view of a distinct customer. |
2 |
Case 2: An engineering firm contracts with numerous suppliers to source raw materials, components, and services. However, suppliers are referred to differently across various departments and systems. This has led to inefficiencies and discrepancies in procurement processes, as well as overlapping contractual agreements and terms that are hard to find or analyze. |
3 |
Case 3: A healthcare institution is investing in content and data management strategies to align diverse patient data across multiple systems, including electronic health records (EHRs), billing systems, and appointment scheduling platforms to ensure accurate patient matching and deliver quality care – without errors (e.g., wrong or duplicate medical records). |
These real-world examples share three challenges:
- Data quality and inconsistency – vast amounts of information that stream from various sources and come in disparate formats, riddled with inconsistent data formats, misspellings, abbreviations, and variations in data entry across different systems or departments.
- Duplicate and redundant records – duplicate and redundant records that proliferate within content and datasets due to data entry errors, system migrations, or lack of care when creating a record. Managing these duplicates manually has become time-consuming and error-prone, leading to inefficiencies and inaccuracies in data analysis.
- Interoperability and data silos – these organizations operate with disparate systems, databases, and data sources that are inherently incompatible. Integrating and harmonizing data from these diverse sources for a 360-degree view to enable cross-functional analysis and reporting is complex and challenging.
Unifying Enterprise Data With A Semantic Layer
Over the last decade, Semantic Layers have been gaining traction as a crucial component in the knowledge and data management arsenal, facilitating effective data aggregation, cleanup, and governance.
At its core, a Semantic Layer acts as a middleware that bridges the gap between disparate data sources by establishing common data definitions, relationships, and ontologies. It accomplishes this by serving as a standardized framework that organizes and abstracts organizational knowledge and data (structured, unstructured, semi-structured). This defines common business terms and relationships, thereby enabling data mapping and interpretation across all organizational knowledge assets.
The foundational step to getting started with a Semantic Layer begins with a practical approach to data mapping, cleansing, reconciling, relationship establishment, and governance. While many of these steps are rather straightforward data transformation work, reconciling real-world entities (who is who) while revealing hidden connections (who is related to who) has remained a vexing challenge.
Entity Resolution: The Secret Weapon
Entity Resolution is a process that determines if multiple apparently different database records actually represent the same real-world entity (e.g., person, organization, vehicle). In the image below note the many differences between the first two records. Despite these differences, Entity Resolution allows one to reasonably conclude that they represent the same individual entity.

At the same time, Entity Resolution must be able to detect when records containing very similar information are, in fact, different real-world entities. Note in the above image, the only difference between records two and three is one character: “J” vs “S” (Junior vs. Senior). It is quite interesting that the record on the left can be confidently called the same person, while the person on the right is clearly a different person. Discovering relationships between entities (connectedness) is what should be a fundamental aspect of your Entity Resolution technology.
While various technologies perform this task of Entity Resolution, they are referred to – quite ironically – by different names such as link detection, record matching, or identity resolution. This term can also be named after a specific mission such as patient record matching, debtor matching, or profile unification (often associated with marketing use cases).
Whether organizations opt to purchase or develop in-house Entity Resolution solutions, precision remains paramount. Additional key factors to consider include things such as batch or real-time processing, scalability (i.e. does the organization have 20 thousand records or 10 billion records to process), ease of use, multi-language support, and explainability.
Role of Entity Resolution and a Semantic Layer
A Semantic Layer architecture typically employs a variety of solutions and technologies aimed at providing a unified and understandable view of data across different sources. Core components of a Semantic Layer architecture include:
- Metadata Management Solution: Enterprise data catalogs, master data management (MDM) systems, or content/data storage solutions aimed at preserving the coherence of essential metadata across numerous storages.
- Data and Content Modeling – Taxonomy/Ontology Managers: Solutions that gears towards the governance and growth of data models through established frameworks (e.g., OWL, RDF, SKOS) and incorporate the selection of Content Management Systems (CMS) offering taxonomy/ontology features.
- Graph Data Storage: Graph databases tend to consist of Labeled Property Graph (LPG) databases, which conceptualize data through nodes, edges, and properties, and RDF (Resource Description Framework) databases, also called triple stores, which conceptualize data using triples (subject-predicate-object).
- Entity Resolution: Semantic layer support that identifies and connects instances of the same real-world entity within and across data sources into a distilled representation – served to the knowledge graph. This can be implemented in the form of an Entity Resolution API that performs this process in real-time.
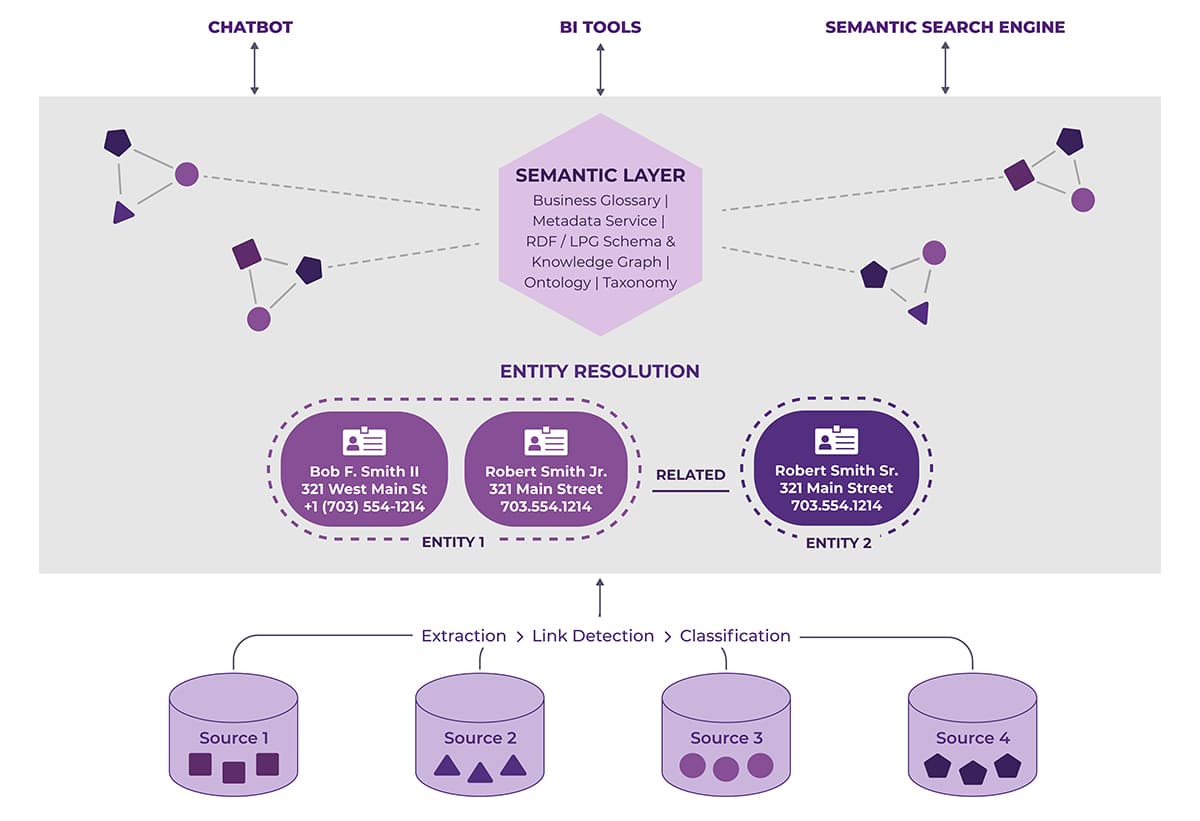
Semantic Layers and Entity Resolved Knowledge Graphs
For many enterprise use cases, Entity Resolved Knowledge Graphs (ERKG) play a pivotal role in scaling a Semantic Layer solution, offering a flexible framework for representing complex relationships between similar or related data entities. Baking Entity Resolution early in the process of data modeling facilitates scaled data integration while ensuring consistency and quality of the data represented within a Semantic Layer. Furthermore, it provides a unified view of data enhancing search and discovery – ultimately improving performance and speed of analytics and data engineering.
In the context of creating an ERKG, it is essential to choose a method that not only identifies matches but also uncovers hidden connections between records that may only contain one similar attribute (e.g. same address despite messy representation). In this scenario, what you want is Entity Resolution that can reveal non-obvious connections between records. For example, two records sharing only this address feature should be surfaced to the knowledge graph as connected or related entities.
Entity Resolution brings clarity by converting what one might call a “data graph” into a knowledge graph. While duplicate nodes are collapsed/consolidated, new or previously unseen relationships between entities are revealed. The image below illustrates the transition from a knowledge graph to an ERKG.

A well-engineered ERKG is scalable and adaptable to evolving data requirements. As new data sources emerge or existing ones change, the graph is updated to reflect these changes, ensuring the utility of the Semantic Layer. Organizations that entity resolve their knowledge graphs will have increased accuracy and better insight from enterprise data. With this, organizations are able to reduce fraud, better serve customers, and become more competitive in the industry.
Case Studies and Applications
Over recent years, Entity Resolution technology has become more accessible to the masses. With advances in technology, the practical application of ERKG’s across use cases and industries has never been easier. The following case studies (which can be clicked on for additional information) provide an example of the wide-ranging utility of ERKGs:
Conclusion
The core value proposition of a successful technical solution today is to make better sense of an organization’s information assets while ensuring the integrity of information and trust. Ultimately, this helps organizations be more competitive in their respective industries.
In the context of a Semantic Layer, harmonizing disparate data sources and establishing clear connections between organizational entities are the foundations for reliable management of organizational knowledge, data and information. Entity Resolution serves as the linchpin for effective data integration, semantic enrichment, and advanced analytics through its ability to disambiguate and reconcile conflicting information. The impact of this synergistic approach has an impact that resonates across industries, from enhancing customer experiences, data quality, and risk management to informing strategic decision-making and enforcement of protective data and privacy policies at all levels of an organization.
By implementing effective semantic solutions with Entity Resolution as a foundation, we have seen a 70-80% increase in data matching rates and 5 times the capacity to ingest and align similar data from multiple sources across diverse industries.
Click here to learn more from our knowledge base or contact us.