
A better way to manage data using semantic graphs for dataset metadata modeling.
A recent study from Gartner found that expensive data science resources are often “misaligned” due to the fact that data science teams are spending a majority of their time on foundational tasks, such as preparing data for analysis. Thus, a key capability for the promotion of an industry-leading data science operation is the ability for data scientists to easily find, manage, and keep track of the data that is available and relevant to their needs. This problem is fundamentally a knowledge and information management challenge, and we find it is commonly overlooked by data-driven organizations that prioritize the end products of data analysis – the insightful graphs, the key predictions, the finely-tuned machine learning models – rather than the amount of time their data scientists are spending simply locating and managing the data for the enterprise.
How data scientists want to spend their time:
How data scientists actually spend their time:
The Data vs. Enterprise Knowledge Graph
As experts in findability and metadata management, we understand that the best way to make datasets easier to manage is to enhance them with rich, descriptive metadata.
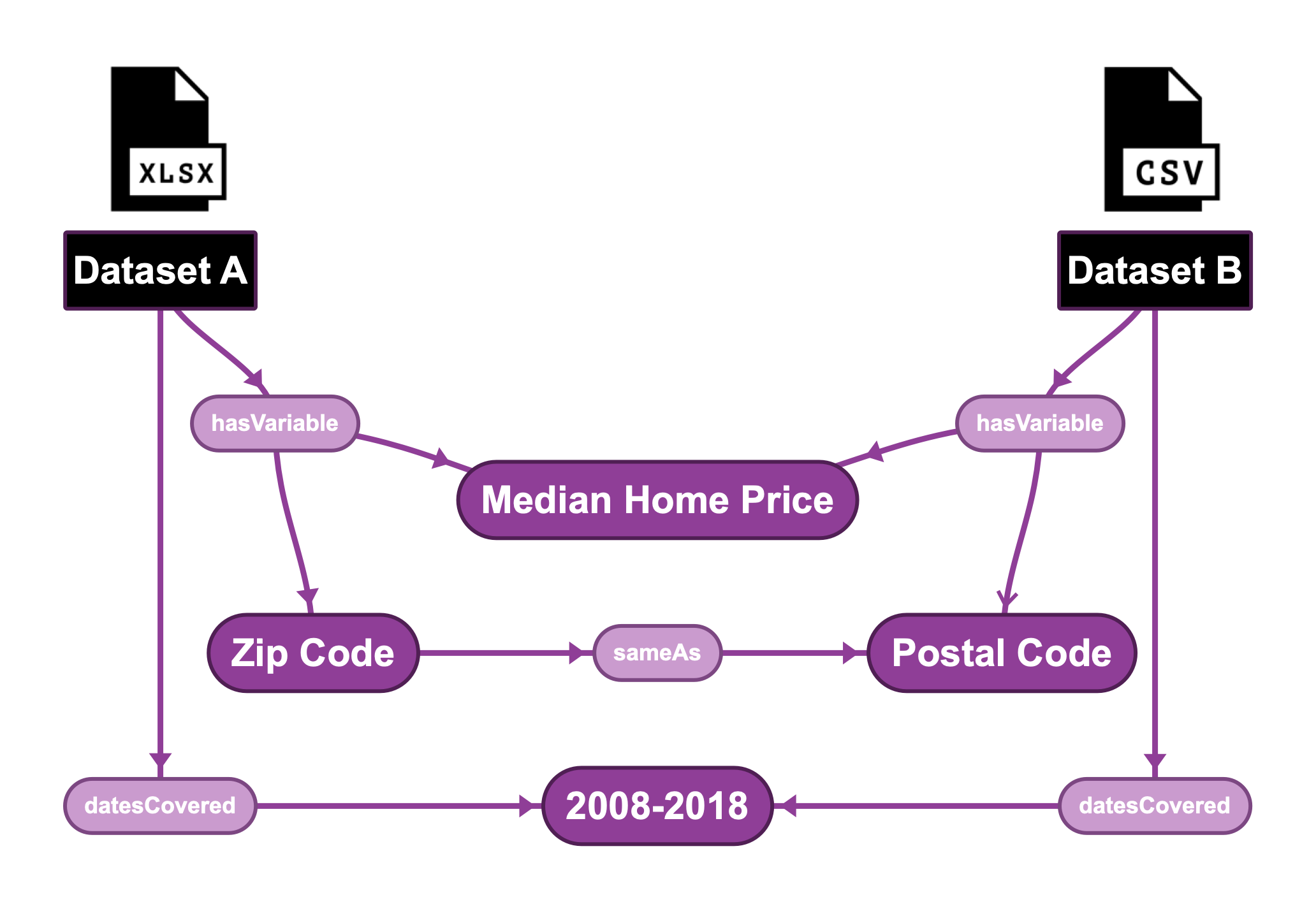
A common data format, tabular data, is formatted in a structure of observations and variables and may have a data dictionary to interpret the units of the values, the meaning of the variables, the topics that the data addresses, etc. Instead of having this information separated from the data, or worse, in the minds of a few subject matter experts or data owners, it can be stored as metadata of the datasets in a data knowledge graph.
A data knowledge graph is a special implementation of an enterprise knowledge graph that models the relevant knowledge domain, or contextual metadata, for datasets. Knowledge graphs are extremely flexible. As a result, they allow different types of data and metadata to be associated with each other.
How a Data Scientist Can Benefit from a Data Knowledge Graph
Using a data knowledge graph, we can create a model to associate a dataset with all of its crucial contexts: the unique variables it records, the subject matter it describes, past versions and derivations, as well as its most common users, all in the same model. This unlocks a wealth of potential avenues that data scientists can use to find relevant and related datasets quickly and effectively. Additionally, a data knowledge graph offers data scientists the opportunity to unlock a myriad of other benefits, including the ability to:
- Identify datasets that are currently in use by their colleagues, and what other datasets are provided to the organization by specific vendors and data aggregators.
- Keep track of the latest versions of datasets as they are manipulated and cleaned by other users.
- Manage data security by managing user access rights for each dataset.
The most impactful use case of a data knowledge graph is improved dataset search, a capability that is often missing in organizations with large data repositories that lack useful metadata and have ineffective search capabilities. Metadata is valuable because it captures what the datasets are “about.” It allows the data knowledge graph to model the connections in the metadata and enhances one’s ability to identify the numerous relationships between datasets that data scientists can capitalize on to develop their analysis.
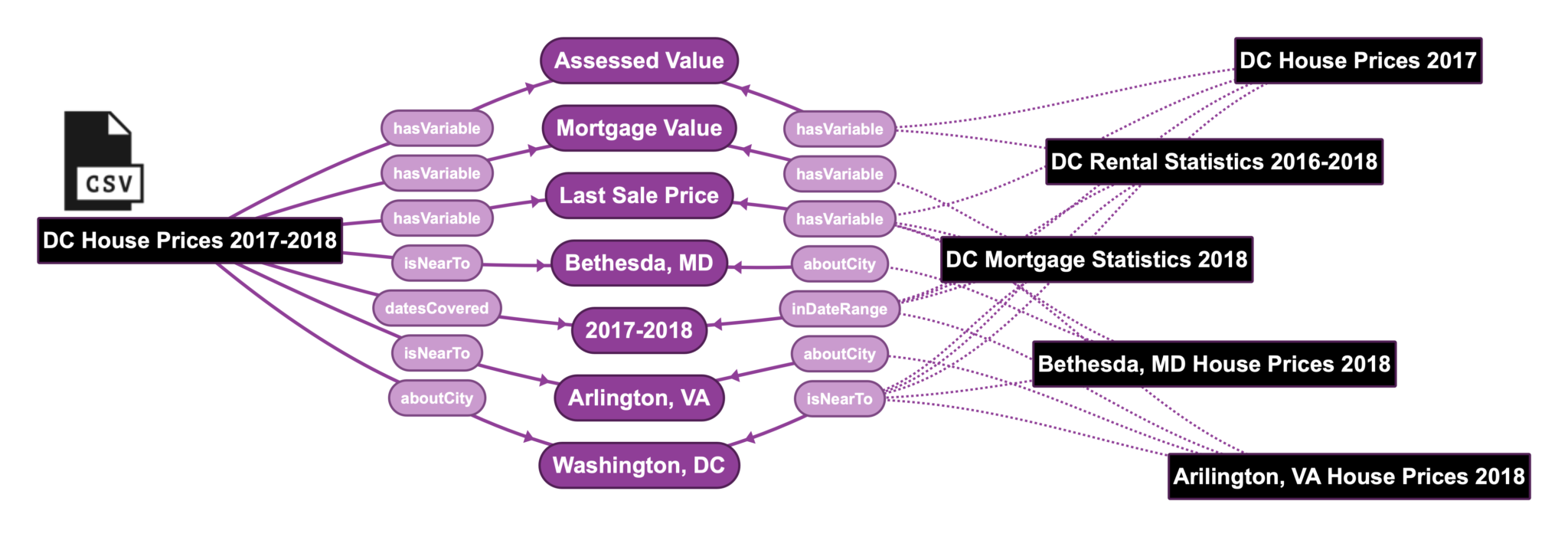
The following image illustrates how a sample data ontology or metadata model helps data scientists relate datasets based on their metadata.
If a data scientist is looking for all the datasets for the home prices in a given zip code, the data knowledge graph can handle their query with ease, revealing all datasets by the relevant variables and dates covered.
The elegance of this solution is that all this contextual information about datasets is available to the data scientist regardless of the file type (XSLX, CSV, HDF5, etc.) or the database where the data is actually stored.
The Data Knowledge Graph for the Data-Driven Business
Data scientists are not the only ones who benefit from a data knowledge graph. Businesses can leverage the data knowledge graph to better manage their data portfolio. The modeling of topics and variables can reveal duplicate or obsolete datasets or highlight topics that need better data coverage.
Moreover, associating datasets with user history provides information on which purchased subscriptions to datasets are actually being used and which datasets are the most popular among particular types of users. Finally, new analysts and users who infrequently use data will find it easier to access the information they need using a vocabulary closely modeled after the language they use to describe data in normal conversation, including synonyms, abbreviations, and acronyms. Datasets that are easier to interpret have a much greater chance of being discovered and utilized by data scientists who mine them for the insights that provide measurable returns to the business.
Good data science takes time and a dedicated effort. As more and more data is becoming available that contains the insights a business needs to act on, data professionals need to be equipped with the right tools and resources to find these useful insights and put them to use on behalf of the business.
If you are looking for the best methods to manage your datasets and arm your data scientists with the tools that will have the greatest impact on their work, learn more or contact us directly. We are happy to partner with you to develop your data strategy and implement a data knowledge graph for your datasets.