
Congrats, you have a taxonomy! It is a strategic milestone for many organizations whether the taxonomy is instantiated in a taxonomy management system of some type, or, as we much more commonly see, stored in a spreadsheet. Regardless, your next step is to decide how you are going to implement the taxonomy and do so effectively. My previous blog discussed Taxonomy Implementation Best Practices such as knowing your use case(s), understanding the limits and features of your system(s), and addressing common implementation challenges, but today I want to discuss how to strategically implement the taxonomy, including how to know where to start, which fields to prioritize, and how to implement iteratively to avoid unnecessary burden on your users, system, and taxonomy team.
Step 1: Review Your Primary Taxonomy Use Cases
Whether you are trying to tackle some of the most common use cases (e.g., search, browsing, overall findability) or more advanced use cases (e.g., predictive analytics, chatbots, recommendation engines), it’s important to understand the business challenge you are trying to solve, or the new functionality you are looking to implement. A taxonomy is most effective when implemented in support of a specific business need or use case, and when each metadata field provides direct value in support of that need. It is not sustainable to implement every metadata field imaginable, as the manual burden and time needed to apply those tags can overshadow the intended value to users. As a result, we recommend implementing metadata fields strategically, in support of clear use cases, and not overburdening a system or users with too much metadata.
For this blog, let’s imagine that our primary use case is improving the findability of both content and people on our organization’s knowledge base. Our organization sells products and services in the Information Technology industry, everything from software licenses to implementation and consulting services. Over the past year, we’ve recognized the importance of a useful and user-friendly repository for sharing knowledge amongst colleagues, keeping up to date on current offerings, and being able to provide our customers with real-time information. As a result, we are working on a pilot with the goal of improving findability in our knowledge base, and have therefore designed a taxonomy that consists of the following metadata fields:
| Metadata Field | Description | Sample Values | Field Size | Potential Application | Scope |
| Topic | Subject matter of information or the subjects within which staff have expertise. | Cloud, Cyber Security, SaaS, etc. | 3 levels, 400 terms | Search Filter, Synonyms | Primary |
| Document Type | Type of information artifact. | Article, Contract, Report, etc. | 25 terms | Search Filter | Primary |
| Function | An employee’s primary work function. | Marketing, Sales, Knowledge Management, etc. | 2 levels, 50 terms | Navigation Menu | Primary |
| Project Phase | Progress or stage of a project. | Initiation, Execution, Monitoring, etc. | 1 level, 5 terms | Search Filter | Secondary |
| Customer Location | Primary location of the customer. | Alabama, Alaska, Arizona, etc. | 1 level, 50 terms | Search Filter | Secondary |
Along with designing our taxonomy, we’ve identified that we want to use said taxonomy as both search filters and navigation menus to improve the findability and discoverability of information in our knowledge base. We’ve also defined key criteria for each field to help us understand how each one may be used in support of our use cases:
- The kind of field (hierarchical or flat list);
- The composition and size of the field (how many levels of hierarchy and how many terms); and
- The scope of the field (primary – applicable to all content or secondary – applicable to subsets of content).
Step 2: Determine How to Implement Each Field
For immediate application of each of the fields from the taxonomy on content in our knowledge base, we need to determine how each field should be implemented based on our use cases. The three most common applications of metadata fields in a knowledge base are as navigation menus, search filters, or synonym dictionaries for the search index. Our taxonomy can be used as a tool to support each of these features in potentially different ways. For example, Function might be a good candidate for a navigation menu, so that employees who work within each function can readily find content related to their roles.
As you saw in the table above, Topic is a hierarchical list with 3 levels of depth and over 400 terms. As a result, we need to consider its size and composition when implementing. We’ve indicated that we would like to use Topic as both a search filter and to add synonyms to our search dictionary so users can enter similar or equivalent terms and receive the same results (e.g., SaaS and Software as a Service). The hierarchy and size of Topic doesn’t have any implications on the implementation of synonyms, but in order to use it for search filters, we need to make some decisions.
Search filters often appear on the left side of a search results page and in most systems, can only display as flat lists, without hierarchy. This is largely due to system limitations and/or the concern of overburdening a user with too much information on one screen. Can you imagine if you had search results with 4 filters, one of which has over 400 terms listed? That would most likely mean the filters on the left would require scrolling or expanding to even be able to read all of the terms. Instead, we can do some research with users to understand if there is a specific level of Topic that would be most helpful for filtering content in a search result. For example, Level 1 of Topic has only 15 terms, which would be a much more reasonable filtering list. Document Type, Project Phase, and Customer Location may also be search filter candidates, and with simple, flat hierarchies, they will not have the same complexity as Topic.

Step 3: Determine Which Fields to Implement First
Our taxonomy has five metadata fields, three of which are primary and two are secondary. In order to decide whether or not we should tackle implementing them all as part of this initial pilot of our knowledge base, let’s go back to the use case and decide what will give us the most value for our effort. Our knowledge base improvement pilot is focused on improving the findability of operational content related to our offerings and our current customers. We are not including project-related content in this first iteration. Knowing this, it likely makes the most sense to spend our time and effort on implementing Topic, Document Type, and Function as they are primary metadata fields, and will be applicable to all content in the knowledge base. We may also want to implement Customer Location as one of our initial information types in the pilot is customer information, but we can wait to implement Project Phase as we aren’t including that content yet. By implementing the most important or relevant metadata fields first, we can save some time and effort in the pilot.
Step 4: Establish Metrics to Measure Taxonomy ROI
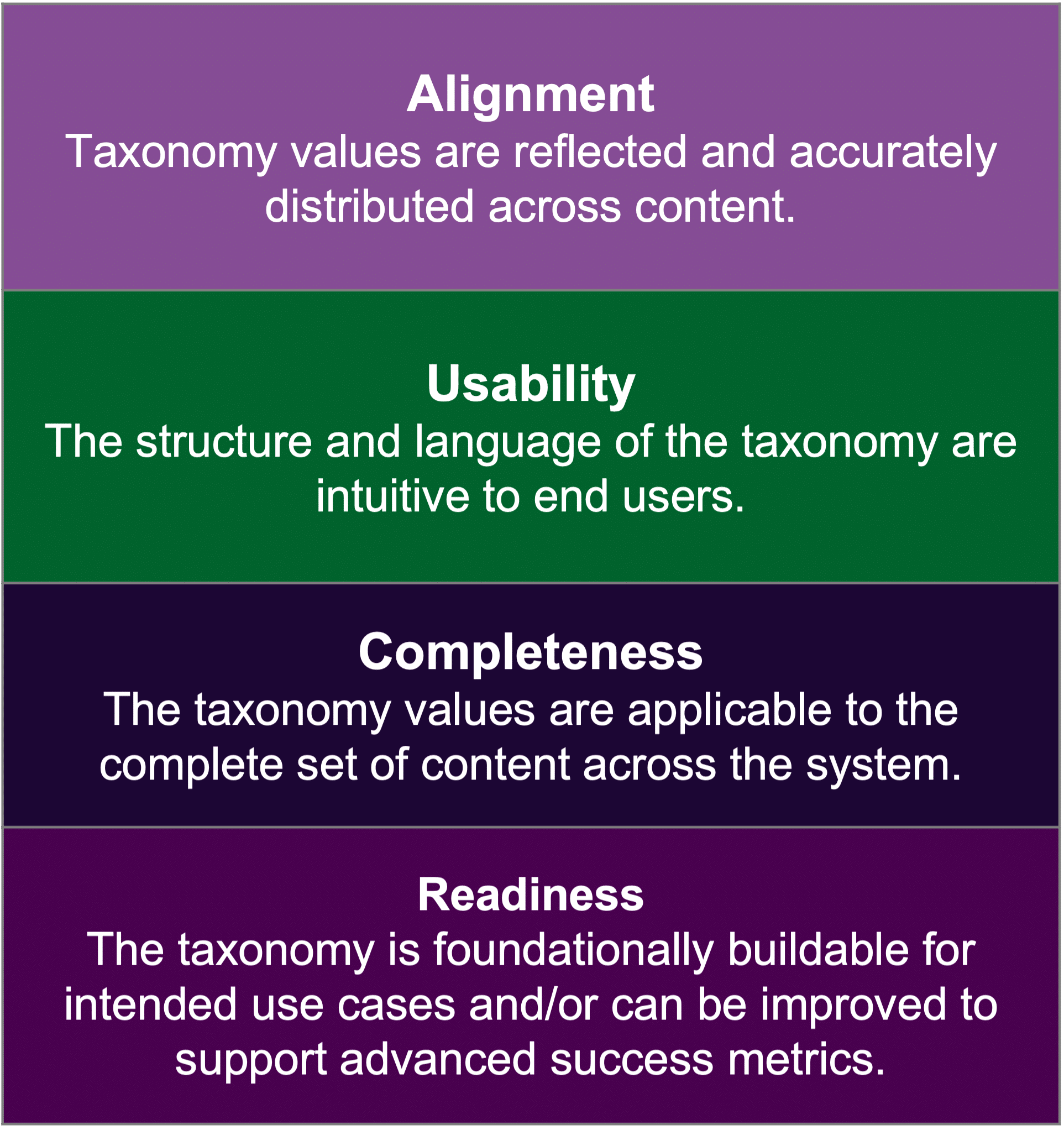 During and continuing after implementation of the primary taxonomy, keep track of any key performance indicators (KPIs) or metrics that you can use to measure the Return on Investment (ROI) of your new taxonomy. The value of the taxonomy lies in the support of our intended use cases, in addition to being a foundation for future efforts. It may be helpful to evaluate both the taxonomy and its ROI by using the four themes of Alignment, Usability, Completeness, and Readiness, remembering that the ROI of the taxonomy, both hard and soft, can be found in the use cases which are improved by the taxonomy. In our example use case of improving findability in the knowledge base, our potential ROI metrics may come from documenting the time spent searching for information, a reduction in unsuccessful searches, or the tracking of search terms and logs, to name a few starting points. Ideally, once we’ve identified which metrics we would like to track, we should take baseline measurements before the implementation is complete so that we can track improvements based on our new taxonomy.
During and continuing after implementation of the primary taxonomy, keep track of any key performance indicators (KPIs) or metrics that you can use to measure the Return on Investment (ROI) of your new taxonomy. The value of the taxonomy lies in the support of our intended use cases, in addition to being a foundation for future efforts. It may be helpful to evaluate both the taxonomy and its ROI by using the four themes of Alignment, Usability, Completeness, and Readiness, remembering that the ROI of the taxonomy, both hard and soft, can be found in the use cases which are improved by the taxonomy. In our example use case of improving findability in the knowledge base, our potential ROI metrics may come from documenting the time spent searching for information, a reduction in unsuccessful searches, or the tracking of search terms and logs, to name a few starting points. Ideally, once we’ve identified which metrics we would like to track, we should take baseline measurements before the implementation is complete so that we can track improvements based on our new taxonomy.
Step 5: Establish Governance & Iteratively Implement Additional Fields
As soon as you’ve begun implementing the taxonomy, it’s important to begin meeting as a taxonomy governance team and reviewing user feedback from the implementation in real-time. Remember that all changes or suggestions must be evaluated from the enterprise perspective to ensure standardization and to analyze impacts for all stakeholders.
Then, as an operational taxonomy governance team, you can work with your stakeholders to implement additional metadata fields from the taxonomy as necessary. Often these fields are secondary or tertiary for the initial use case, or primary for new use cases. For example, once we’ve decided to bring in project-related content, we may want to consider implementing the Project Phase metadata field and tagging content appropriately as it is migrated into the knowledge base. The governance team will also receive and process requests for additional secondary metadata for specific teams or subsections of content, and ensure the taxonomy grows in a sustainable and scalable manner.
Conclusion
Many of our clients have little to no metadata applied to their content when we first engage. Or, in a few cases, they have a ton of disparate systems all with their own metadata. In either situation, it’s not enough to just design a new taxonomy. We also need to implement the taxonomy in a way that is usable, intuitive, and serves our users’ information needs.
If this sounds like your organization, we’d love to help you tackle taxonomy design, validation, and implementation. Contact us!