
For many projects at Enterprise Knowledge, making information more findable and discoverable is a common ask. Clients often ask questions like:
- Does my organization have any documents that detail the role of product owners on search projects?
- Have we previously done work for a client that utilizes this set of technologies or capabilities?
- Given what I know of my customers, what solutions, services, or products should I offer them?
- Who at my organization could help me complete this work or provide the input of a subject matter expert?
Knowledge Graphs allow organizations to answer all of these questions in one system, regardless of where the source information resides.
Use Case 1: Search Application
The first three questions may be interpreted as search queries enhanced with some sweet facets. For example, an organization could set up a search portal that supports faceting on “Document” as a content type, “Product Owner” as a role, and “Search” as a topic.  Almost every content management system has some flavor of search, so search isn’t limited to knowledge graphs. However, a knowledge graph enables an organization to perform searches across multiple platforms by:
Almost every content management system has some flavor of search, so search isn’t limited to knowledge graphs. However, a knowledge graph enables an organization to perform searches across multiple platforms by:
- aggregating content and/or metadata into a graph database;
- enhancing the metadata through auto-tagging and classification; and
- providing links back to the source system.
By aggregating content from multiple systems, users can access information in one place and more easily synthesize information. Similar to Google’s results page, when a user searches a knowledge graph, the result is a link to the source system, making it easier to find and view organizational information.
The search experience can be enhanced even further with an organizational business taxonomy. A business taxonomy, applied consistently to all of an organization’s content, allows users to apply common filters to content and more efficiently refine search results from across previously siloed content sources. User questions are answered by providing one unified search system instead of many.
Use Case 2: Expert Finder
The fourth question is a commonly requested solution – an expert finder. If we can pull content from multiple systems and store it in a graph database, then why not also store information about people? Every employee, author, and document reviewer in your organization is also represented in the knowledge graph. In knowledge graphs, we define relationships between people and content:
- Who was mentioned in the full-text?
- Who reviewed the content before it was published?
- Who is the author of the content?
- Who was on the team which produced the document?
How content is related to people is unique to each organization, but the result is a dataset that powers an expert finder.
We add a classification model on top of the graph database that analyzes each individual, determining which metadata values are most related to the individual. As an example exercise, go to the EK Knowledge Base and pick any topic from the facets on the left-hand side. You will notice that some authors appear more frequently depending on which topic you choose.
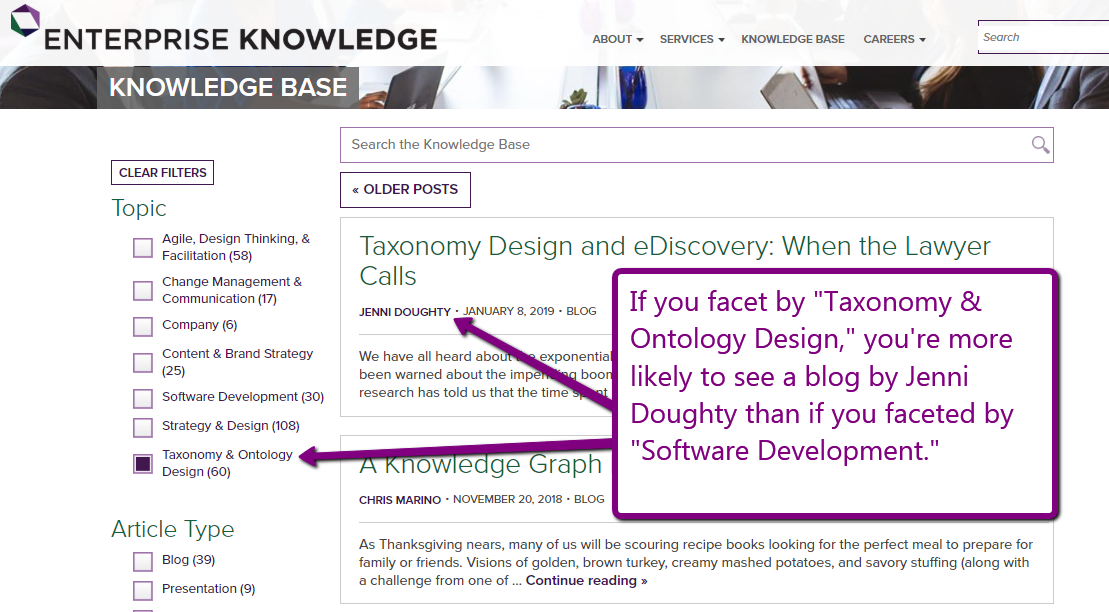
A classification model performs a similar analysis, but on a larger scale, allowing the system to automatically infer who is an expert based on metadata. Once the system identifies experts, it can quickly recommend who someone should talk to when they need help with a certain subject matter.
Summary
Knowledge Graphs are powerful tools that encourage search and discovery within an organization. Whether developing a search application or an organizational expert finder, contact Enterprise Knowledge and let’s discuss how we can build the right experience for you and your users.