
Our KM Consultants help organizations improve the way they capture, share, and reuse information. Many KM projects focus on managing unstructured information like documents, emails, and web pages. While this type of unstructured information is critical, it is not the full enterprise of an organization’s knowledge. What about databases, reports, and dashboards? To fully encompass an organization’s knowledge and information, both structured and unstructured information must be addressed. The most impactful Knowledge and Information Management approaches are those that not only cover both structured and unstructured information, but manage them together in an integrated manner. A well-defined ontology is a critical path to link structured (databases and reports) and unstructured information.
An organization that successfully links their structured and unstructured information through ontologies can see meaningful improvements in the findability and discoverability of their information. An ontology will create connection between all information, meaning that information becomes a web that may be traversed by your end users to better find and use the information they seek. This leads to greater productivity, collaboration, and overall satisfaction.
The easiest way to understand how ontologies can help link structured and unstructured information is through examples. This blog shares two different examples showing how an ontology can associate these two different types of content.
- Merging customer information with customer metrics
- Mining product information
Merging Customer Information with Customer Metrics
The Problem
A large financial services firm that worked primarily with corporate clients needed to integrate customer metrics into their customer intelligence portal. The portal was a central location for news and information about their customers to improve sales and account management. The content included formal customer documents (contracts, invoices and license agreements), news, and call notes. A separate data warehouse team had a database of key customer metrics. The firm wanted a way to show key metrics about a customer while people were reading news, documents, or call notes about that customer.
The Ontology Solution
The firm used their customer database to seed an ontology that included a customer entity type. Each customer entity was assigned attributes like industry, status, and customer number using information from the customer database. This list of customers and their attributes was loaded into an ontology management and entity extraction tool, like PoolParty. The entity extraction tool was run against the content repository to identify references to customers in the content. Once the entities were identified and tagged, the structured and unstructured information could be linked.
The portal content was organized by customer, industry, and topic. The customer and industry information comes from the ontology. When users look a document that mentions one of their customers, they also see metrics about the customer and their industry.
Mining Product Information
The Problem
A manufacturing company was looking to find patterns about product defects in order to improve the reliability of the products they manufacture. They had information in a variety of formats:
- A database of information about product defects and returns;
- Defect reports with problem descriptions; and
- User comments from their website.
The manufacturer needed a way to mine all of this information to identify patterns that would allow them to improve the way they manufactured their products.
The Ontology Solution
An ontology was the best way to link this content together for analysis. The manufacturer created an ontology that included the following entities:
- Products
- Parts
- Defects
Products store the name of the product, its SKU, and the unique identifier that can be used to link it back to the product database that contains the structured information. Parts include the name of the part, any similar names, and manufacturing information. The defects are a list of common problems that will grow as more information is captured.
The products were loaded into the ontology management tool with the SKU and product identifier so that they could be linked back to the database. We entered part information and common defects in the parts and class entities. Entity extraction was run against the unstructured content (defect reports, surveys, and social media). This allowed us to identify new defects and parts and associate them with the products aligned with the content.
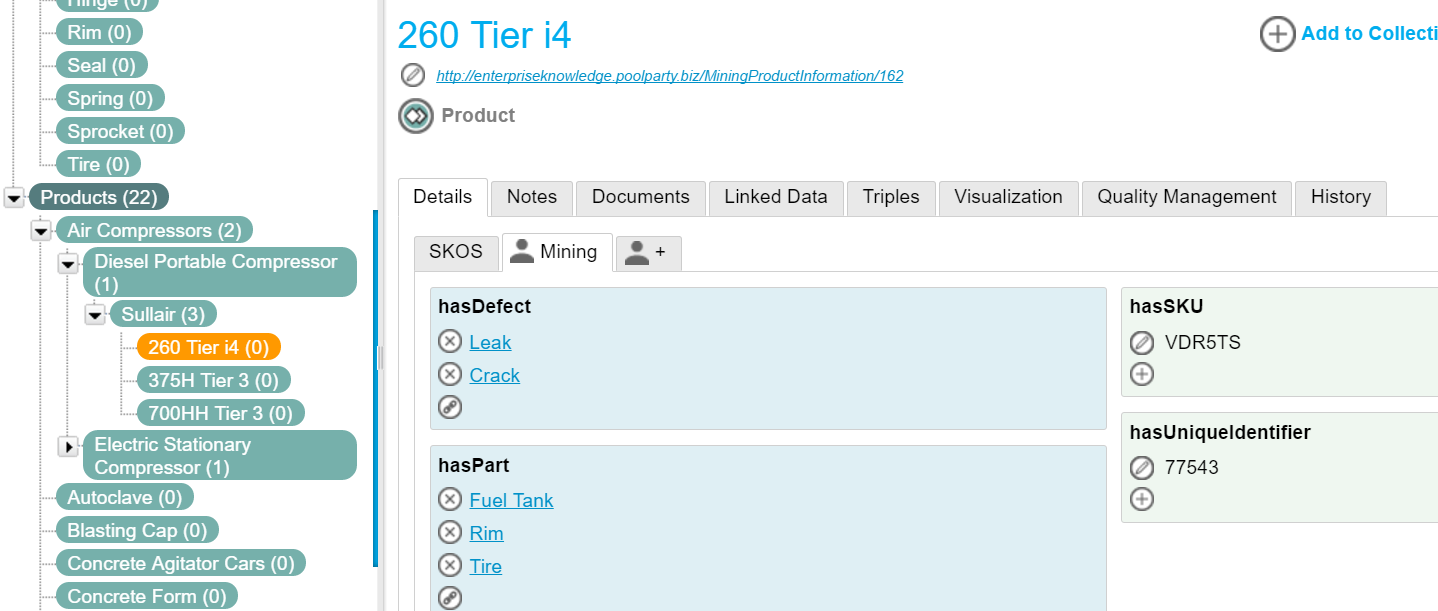
The manufacturer was able to use SPARQL (an ontology query language similar to SQL) to see relationships between defects, parts, and products that were not easily visible before. Using SPARQL queries, the manufacturer was able to see that 2-3 parts that were used across the product line accounted for most of the defect descriptions. This information would not have been available without associating problem descriptions with defect and return information from their product database.
Conclusion
As you can see from these two examples, an ontology is a great way to link structured and unstructured information. Ontology products like PoolParty automate much of the process and make it an affordable and scalable solution. The next time you revisit your organization’s Knowledge Management capabilities do not limit yourself to documents and web pages. Use ontologies to integrate databases and reports so that you have a true Knowledge and Information Management (KIM) solution.
EK can help make the integration of your structured and unstructured information seamless. For more information contact us at info@enterprise-knowledge.com.