
At GOTO Chicago 2016, a senior architect for Uber presented how, at the time, Uber had over 1,000 microservices. The brilliant minds at the ride-sharing company took this design pattern to the extreme. It did not take long to see that this approach was beginning to have not only diminishing returns but adverse effects.
Maintenance, even in a mature cloud application, can be taxing. Learning all those services is impossible. And integrating and keeping versions compatible was requiring entire teams to ensure something didn’t break. Uber had created a hydra of an application in its very well-intended efforts not to create Godzilla.

How did we get here?
A long time ago, before I was programming, there were monolithic applications. COBOL was the language of choice, and these applications tried to be everything and anything to the companies that used them. Not many of these dinosaurs remain, and for a good reason. They are difficult to maintain, usually require downtime and huge testing efforts, but also run on CPU expensive hardware that often requires layers of emulation to run on modern operating systems and chipsets.
From there, we progressed through pattern programming to Service Oriented Architecture (“SOA”) within an application to the scalability of the cloud.
Fast, lightweight, and semantic, REST was the game-changer to make microservices the tool for any and every job. Right?
All things in moderation
The first reaction to SOA from a microservice perspective is to microservice EVERYTHING! You get a microservice; you get a microservice; you get a microservice! Orders, products, taxonomies, users, permissions, everything!
Developers working at breakneck speeds release daily or more self-documenting code, and the modular design is a strong reason to use this type of architecture.
A couple of rules come into play, such as a microservice front end for the database it owns. No direct querying of the database is allowed; all data access must go through the API. And no API can have more than one database behind it.
A year goes by. Two. Three? Onboarding new engineering team members takes longer and longer. The user service has over 30 versions still active. The category service isn’t even used but is still running on three instances in production. Documentation takes months to read, but it is all ok because we are using microservices and we are awesome.
What is the solution?
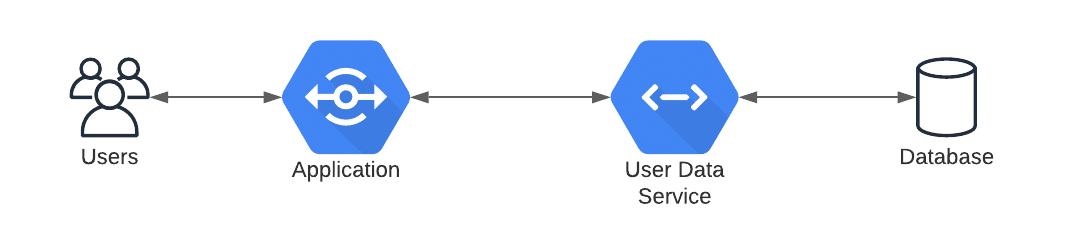
Understanding the ins and outs of how the application is to be used, how the data is accessed, and the interaction between those pieces is key to knowing where the lines can or should be drawn.
There are always the obvious ones, like users, products, orders. What about metadata? Each of those will have a treasure trove of metadata accompanying it. Does the metadata exist in a meta service, or should it live with the parent data object? Three design patterns emerge reasonably quickly.
1. Metadata lives with the parent. In this example, the metadata would exist directly in the same database and accessed via the same API as the parent object.
A simple example can be a user:
/user/123
{
"id" : 123,
"username" : "someuser",
"email" : "somebody@gmail.com",
"first_name" : "John",
"last_name" : "Wilson"
}
Or, if we want to use a different call against the same API to get the metadata:
/user/123/details
{
"id" : 123,
"username" : "someuser",
"email" : "somebody@gmail.com",
"first_name" : "John",
"last_name" : "Wilson",
"meta": {
"last_login" : "2020-02-14T16:22:48.00-6:00",
"created" : "2018-07-22T05:11:29.00-5:00",
"external" : false
}
}
This solution’s simplicity is that metadata is stored in the same datastore as the parent object, allowing a single API to return all the data. Downsides mean the database may have a table that stores all the metadata, and if there are a lot more writes to it because of how the application behaves, it could become bogged down.
2. Metadata is its own service. Here we keep all metadata about many different types of objects in the same data store, but separate from the parent object. In this example, the user object is stored in one database, but the user meta is stored in another.
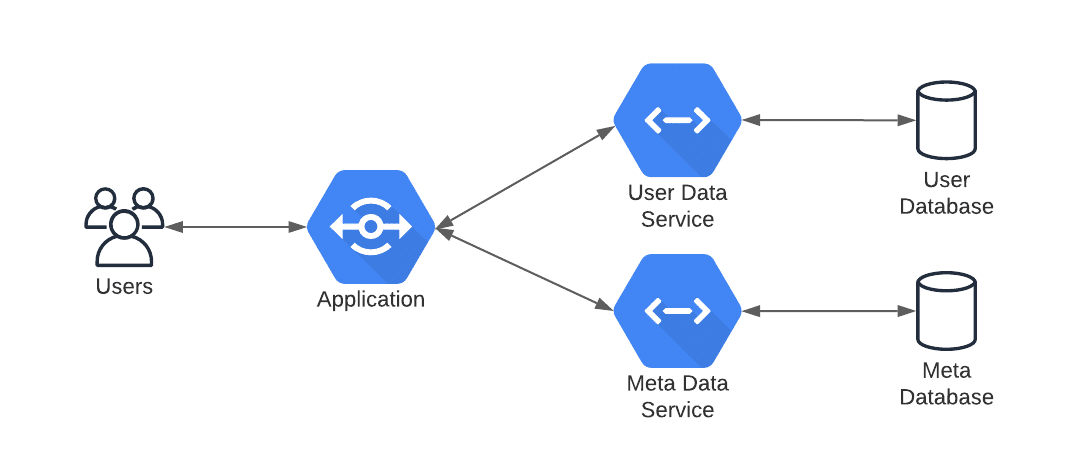
/meta/user/123
{
"last_login" : "2020-02-14T16:22:48.00-6:00",
"created" : "2018-07-22T05:11:29.00-5:00",
"external" : false
}
/meta/order/5422
{
"shipped" : "2019-03-15T11:34:51.00-6:00",
“created" : "2019-03-15T10:10:59.00-6:00",
"shipping_carrier" : "ups"
}
Same service, just different types. The advantage here is the data store can be straightforward and fast. The downside is that it is another call.
3. Layered Hybrid. The third one is a hybrid and hides the second call to retrieve the metadata behind just one call. Like the first example, the call and results are the same.
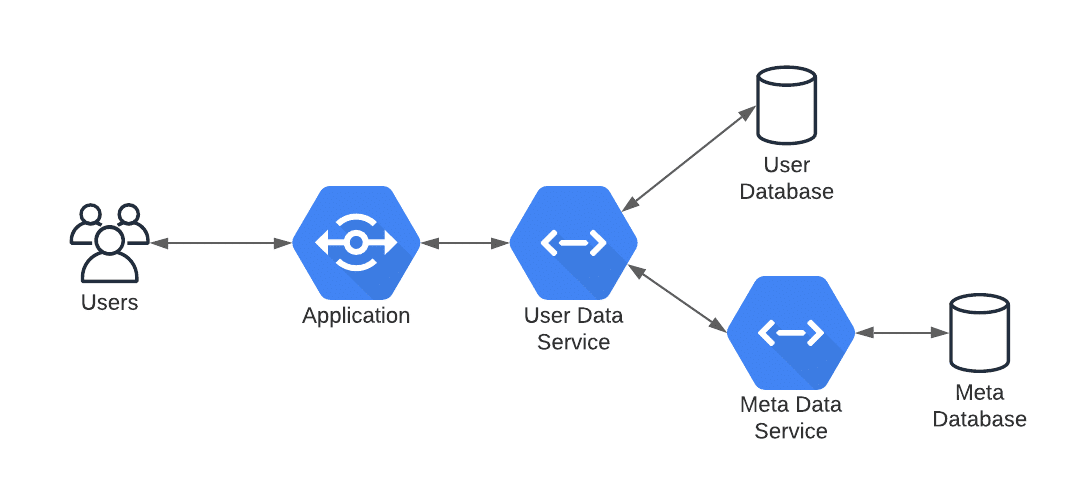
/user/123/details
{
"id" : 123,
"username" : "someuser",
"email" : "somebody@gmail.com",
"first_name" : "John",
"last_name" : "Wilson",
"meta": {
"last_login" : "2020-02-14T16:22:48.00-6:00",
"created" : "2018-07-22T05:11:29.00-5:00",
"external" : false
}
}
The difference is that the second call is still there, just hidden behind the first call, so the user doesn’t notice it. The advantage is that it offloads the smaller easy calls to another system and can cache very quickly, but only if the meta doesn’t have a lot of writes.
What does that look like in reality?
Knowledge Management is often taking many different sources of information and merging them into a seamless experience for the user. While a challenge in and of itself, even more thought must go into how the users will search for the information, and ensure that relevant data is presented instead of endless pages of search results.
In this example, the Knowledge Portal can be played by various applications such as SharePoint, Confluence, or WordPress. These well known portal applications have many integration points and the ability to customize behavior and data flows to each unique scenario.
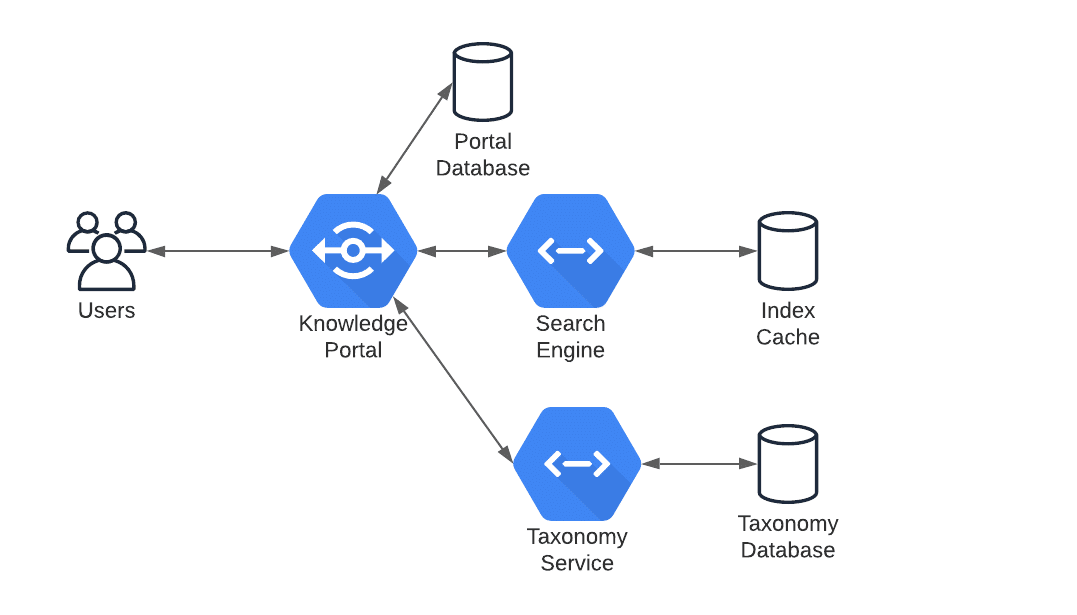
The taxonomy service is used to retrieve the business taxonomy from the taxonomy database for use in the knowledge portal. This taxonomy is leveraged to apply metadata to content in the knowledge portal database. Keeping these separate allows the data stores to be very specialized, and efficient. It is possible for the portal to use MySQL, the search engine to use Cassandra, and the taxonomy database to use GraphDB. Each one is different and can be tailored to their specific needs and use cases. The search engine acts as another service, retrieving search results from a cached search index. This keeps the Portal Database free from intensive search queries while still delivering rapid and relevant results to the user via a familiar interface.
If there is a very large number of documents to be indexed, or a huge number of users, there may be other solutions to insert into this model to further refine the data flow and abstract the queries away from the Knowledge Portal, keeping it responsive to the users.
How do I choose?
Each of these solutions, and they are not the only options by any stretch, come with advantages and drawbacks. Option 3 is the most expensive from a cost standpoint, but also the most scalable with the most places to insert dynamic caching like AWS ElasticCache.
Option 1 is the least expensive, but depending on how the database is being used, and the load, could cause latency or transaction conflicts in a high traffic environment.
In the end, the real question is, how are you planning on using your data, both near term and long term. The solutions provided here are not a one size fits all and not the only ones. These are very simple examples. There can be a lot of more complex examples like should products, orders, and invoices all reside in the same database and/or microservice. Every situation is unique.
EK is an expert in data and knowledge architecture. Contact us to connect with certified and experienced experts who can assist your company in making the decision that is right for your needs today, with an eye on tomorrow. We can be there with you every step of the way to ensure the solution is customized for your unique needs.