
A couple of weeks ago, Semantic Web Company (SWC) released a new version, 6.0, of their already extensive PoolParty Semantic Suite with some exciting new additions. Why does this matter? The PoolParty Semantic Suite is further solidifying its spot at the forefront of semantic technologies, taxonomy and ontology management tools, auto-classification, KM machine learning, and semantic data integration platforms. In short, it is a tool that helps organizations integrate, connect, and analyze their structured and unstructured information, as well as leverage machine learning capabilities to auto-classify content and gain efficiency in the content capturing and discovery phases of knowledge management.
Below I briefly highlight some of the new features and how they impact the knowledge management business.
1. Implicit Content Relationships (a.k.a. Shadow Concept Extraction)
One of the main goals that PoolParty strives for is to help organizations relate their content objects, thus building the organizational knowledge. In past versions, PoolParty achieved this by relating content where concepts were mentioned explicitly within the content items. In other words, through its complex algorithms and Natural Language Processing capabilities, PoolParty extracted the main concepts that it found in the content.
With 6.0, however, PoolParty takes this capability to the next level. In addition to being able to learn the organization’s knowledge domain and suggest the most relevant tags for content items in an auto-classification style, PoolParty now automatically identifies topics and concepts that are closely related to a piece of content, even if the topic or concept is not explicitly mentioned in the content. In other words, the system can now recommend semantically related content based on indirect, implicit relationships that it identifies based on its own content analysis.
Below is a screenshot of the view a Knowledge Manager would see during the fine-tuning process to identify concepts and shadow concepts. This is not the front end user interface, but it does provide a quick and easy way to test content excerpts against the analysis engine:
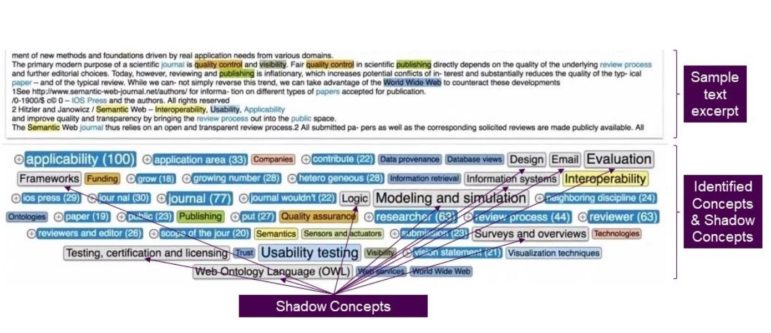
In the screenshot above, the items in grey denote the identified shadow concepts.
In more technical terms, the shadow concept functionality allows you to see how a document relates to a concept in your knowledge graph even if the document does not mention that concept explicitly. Additionally, PoolParty allows you to see why that relationship was suggested by providing the found terms and their relationship to the shadow concept.
Why It Matters
The clearest benefit of this technology is its ability to help your users discover relationships between knowledge objects they didn’t know existed. In the background and based on your organization’s content, PoolParty now builds its own network of related terms in addition to your organization’s explicit ontology or thesaurus. This allows PoolParty to recommend related items based on its comprehensive organizational knowledge even if the user did not specifically know of the relationship (or that the recommended concept even existed). Think of the Amazon recommender system, but for your organization and based on your own content.
2. Centralized Interface for All Your PoolParty Data Integrations (a.k.a. Semantic Middleware Configurator)
PoolParty was already well-connected. Its latest version provides additional integration options with Linked Data Sources, search and graph search engines, graph databases (i.e. triple stores), and visualization engines. To aid in managing all these connections and integrations, PoolParty introduces the Semantic Middleware Configurator functionality which provides a quick view and easy management options for all integration channels to systems integrated with PoolParty. Knowledge managers and engineers will find this new functionality extremely helpful. The ability to quickly see all connections, their status, and settings at a glance is a significant improvement on clarity and efficiency.
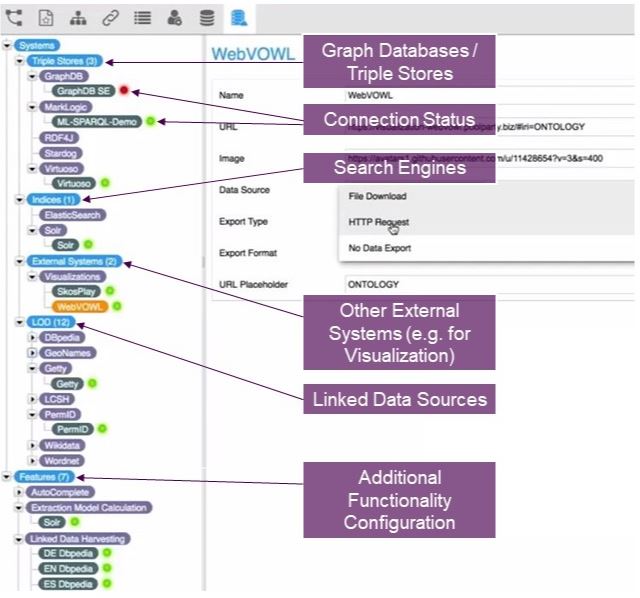
PoolParty’s new Semantic Middleware Configurator interface showing all connections and integrations in one location.
Why It Matters
With the growing number of data sources and tools that allow organizations to interconnect, visualize, and analyze their knowledge, the ability to manage all these connections in one place becomes critical. With this in mind, the new Semantic Middleware Integrator feature is a solid contender to become the enterprise semantic data integration center.
3. Visualization
With larger thesauri, and especially ontologies, it quickly becomes difficult to manage relationships and knowledge models and even more so to communicate them to stakeholders. The 6.0 release of PoolParty tackles this challenge in two ways: improved native visualization; and integration with visualization engines like webVOWL.
The enhancements to PoolParty’s native visualization capability help knowledge managers view relationships between types of concepts (i.e. classes), as well as the custom properties, or attributes associated to a knowledge object.
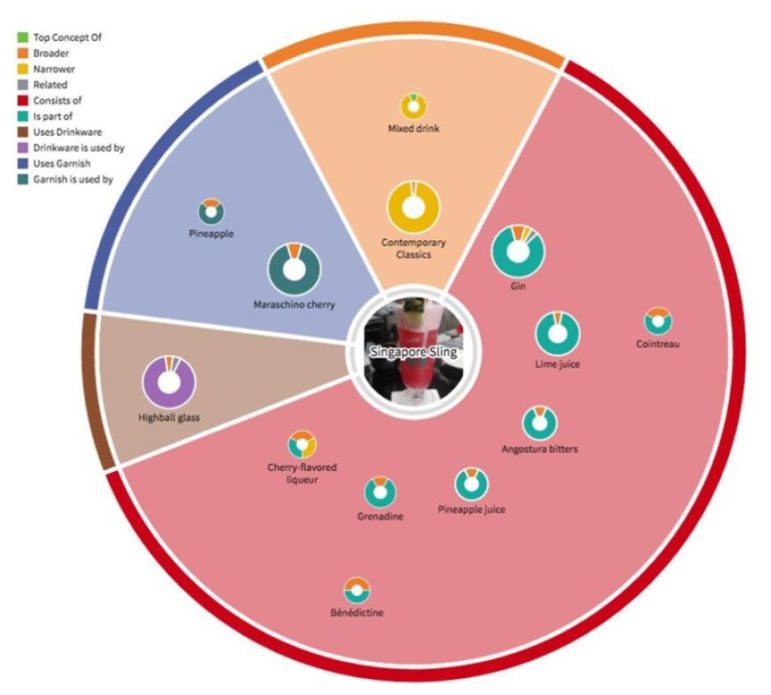
PoolParty native visualization of concepts and relationships.
With the introduction of integration capabilities to visualization tools like webVOWL, knowledge managers can now produce a visual model of the full ontology to help them in their ontology design efforts as well as communicate the model with other stakeholders.
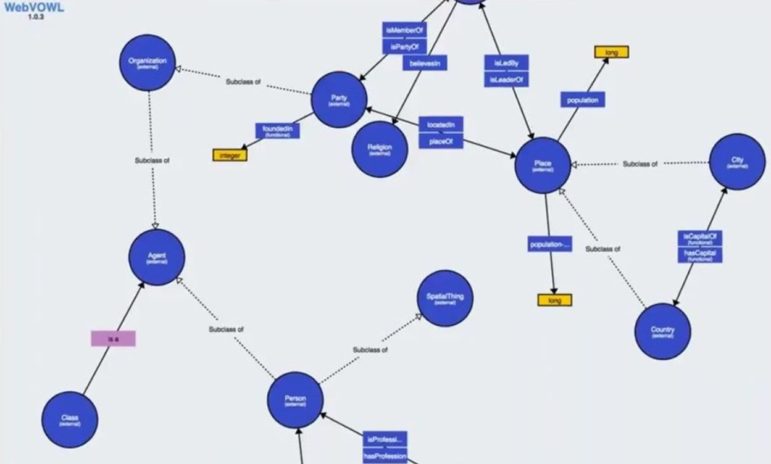
PoolParty ontology visualized through webVOWL integration.
Why It Matters
One of the issues inhibiting the proliferation of business ontologies is their perceived complexity. With scale, the challenge of designing, collaborating, and communicating the knowledge model, i.e. the ontology, grows. However, the ability to visually represent concepts, their attributes, and how they are connected significantly simplifies these tasks. As a result, we are looking at shorter design and onboarding time, thus reduced costs.
4. Additional Linked Data Sources
We all try to avoid reinventing the wheel where possible. Or in KM terms, why recreate knowledge if it already exists? With that in mind, even in past versions, PoolParty has provided automatic integration with public sources of information like definitions and alternative names of terms, topics, etc. PoolParty 6.0 includes additional sources of shared data that organizations can utilize to quickly and easily enrich their internal content as well as bring in externally managed and updated content – without additional content management load.
With PoolParty 6.0, these sources of Linked Open Data now include additions like:
- PermID – A Thomson Reuters Permanent Identifiers source that provides company information, mainly in the finance industry;
- Getty Vocabularies – A linked open data source of “structured terminology for art and other material culture, archival materials, visual surrogates, and bibliographic materials”;
- DBPedia in Dutch and Russian – PoolParty continues to add support for new language versions of one of the most popular and active linked data sources.
Why It Matters
Linked Open Data sources are gaining popularity and can be utilized to enhance your content with minimal additional effort. Leveraging public shared data allows you you expand your thesauri by adding new terms, definitions, and synonyms, thus increasing the quality and richness of your knowledge. This in turn helps make your enterprise search results and relationships more accurate and relevant.
Closing Thoughts
As a supervised learning system, PoolParty 6.0 takes the next step to integrating siloed structured and unstructured content, identifying relationships, and augmenting organizational knowledge. The result is more relevant and findable content for your users.