

Every organization has content/information that needs to be treated as confidential. In some cases, it’s easy to know where this content is stored and to make sure that it is secure. In many other cases, this sensitive or confidential content is created and stored on shared drives or in insecure locations that employees could stumble upon or hackers could take advantage of. Especially in larger organizations that have been in operation for decades, sensitive content and data that has been left and forgotten in unsecured locations is a common, high-risk problem. We call hidden and risky content ‘Phantom Data’ to express that it is often unknown or unseen and also has the strong potential to hurt your organization’s operations. Most organizations have a Phantom Data problem and very few know how to solve it. We have helped a number of organizations address this problem and I am going to share our approach so that others can be protected from the exposure of confidential information that could lead to fines, a loss of reputation, and/or potential lawsuits.

We’ve consolidated our recommended approach to this problem into four steps. This approach offers better ways to defend against hackers, unwanted information loss, and unintended information disclosures.
- Identify a way to manage the unmanaged content.
- Implement software to identify Personally Identifiable Information (PII) and Personal Health Information (PHI).
- Implement an automated tagging solution to further identify secure information.
- Design ongoing content governance to ensure continued compliance.
Manage Unmanaged Content
 Shared drives and other unmanaged data sources are the most common cause of the Phantom Data problem. If possible, organizations should have well-defined content management systems (document management, digital asset management, and web content management solutions) to store their information. These systems should be configured with a security model that is auditable and aligns with the company’s security policies.
Shared drives and other unmanaged data sources are the most common cause of the Phantom Data problem. If possible, organizations should have well-defined content management systems (document management, digital asset management, and web content management solutions) to store their information. These systems should be configured with a security model that is auditable and aligns with the company’s security policies.
Typically we work with our clients to define a security model and an information architecture for their CMS tools, and then migrate content to the properly secured infrastructure. The security model needs to align with the identity and access management tools already in place. The information architecture should be defined in a way that makes information findable for staff across business departments/units, but also makes it very clear as to where secure content should be stored. Done properly, the CMS will be easy to use and your knowledge workers will find it easier to place secure content in the right place.
In some cases, our clients need to store content in multiple locations and are unable to consolidate it onto a single platform. In these cases, we recommend a federated content management approach using a metadata store or content hub. This is a solution we have built for many of our clients. The hub stores the metadata and security information about each piece of content and points to the content in its central location. The image below shows how this works.
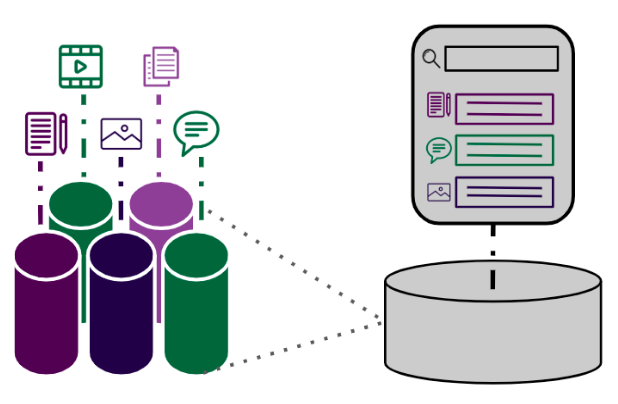
Once the hub is in place, the business can now see which content needs security and ensure that the security of the source systems matches the required security identified in the hub.
Implement PII and PHI Software
There are a number of security software solutions that are designed to scan content to identify PII and PHI information. These tools look at content to identify the following information:
- Credit card and bank account information
- Passport or driver’s license information
- Names, DOBs, phone numbers
- Email addresses
- Medical conditions
- Disabilities
- Relative information
These are powerful tools that are worth implementing as part of this solution set. They are focused on one important part of the Phantom Data issue, and can deliver a solution with out-of-the-box software. In addition, many of these tools already have pre-established connectors to common CMS tools.
Once integrated, these tools provide a powerful alert function to the existence of PII and PHI information that should be stored in more secure locations.
Implement an Automated Tagging Solution
 Many organizations assume that a PII and PHI scanning tool will completely resolve the problem of finding and managing Phantom Data. Unfortunately, PII and PHI are only part of the problem. There is a lot of content that needs to be secured or controlled that does not have personal or health information in it. As an example, at EK we have content from clients that describes internal processes, which should not be shared. There is no personal information in it, but it still needs to be stored in a secure environment to protect our clients’ confidentiality. Our clients may also have customer or product information that needs to be secured. Taxonomies and auto-tagging solutions can help identify these files.
Many organizations assume that a PII and PHI scanning tool will completely resolve the problem of finding and managing Phantom Data. Unfortunately, PII and PHI are only part of the problem. There is a lot of content that needs to be secured or controlled that does not have personal or health information in it. As an example, at EK we have content from clients that describes internal processes, which should not be shared. There is no personal information in it, but it still needs to be stored in a secure environment to protect our clients’ confidentiality. Our clients may also have customer or product information that needs to be secured. Taxonomies and auto-tagging solutions can help identify these files.
We work with our clients to develop taxonomies (controlled vocabularies) that can be used to identify content that needs to be secured. For example, we can create a taxonomy of client names to spot content about a specific client. We can also create a topical taxonomy that identifies the type of information in the document. Together, these two fields can help an administrator see content whose topic and text suggest that it should be secured.
The steps to implement this tagging are as follows:
- Identify and procure a taxonomy management tool that supports auto-tagging.
- Develop one or more taxonomies that can be used to identify content that should be secured.
- Implement and tune auto-tagging (through the taxonomy management tool) to tag content.
- Review the tagging combinations that most likely suggest a need for security, and develop rules to notify administrators when these situations arise.
- Implement notifications to content/security administrators based on the content tags.
Once the tagging solution is in place, your organization will have two complementary methods to automatically identify content and information that should be secured according to your data security policy.
Design and Implement Content Governance
The steps described above provide a great way to get started solving your Phantom Data problem. Each of these tools is designed to provide automated methods to alert users about this problem going forward. The solution will stagnate if a governance plan is not put in place to ensure that content is properly managed and the solution adapts over time.
We typically help our clients develop a governance plan and framework that:
- Identifies the roles and responsibilities of people managing content;
- Provides auditable reports and metrics for monitoring compliance with security requirements; and
- Provides processes for regularly testing, reviewing, and enhancing the tagging and alerting logic so that security is maintained even as content adapts.
The governance plan gives our clients step-by-step instructions, showing how to ensure ongoing compliance with data protection policies to continually enhance the process over time.
Beyond simply creating a governance plan, the key to success is to implement it in a way that is easy to follow and difficult to ignore. For instance, content governance roles and processes should be implemented as security privileges and workflows directly within your systems.
In Summary
If you work in a large organization with any sort of decentralized management of confidential information, you likely have a Phantom Data problem. Exposure of Phantom Data can cost organizations millions of dollars, not to mention the loss of reputation that organizations can suffer if the information security failure becomes public.
If you are worried about your Phantom Data risks and are looking for an answer, please do not hesitate to reach out to us.