
Sometimes, clients who come to EK confident in their ontology development capabilities find themselves wrongfooted when it comes to creating an ontology management plan. This is partly a result of documentation – there are a wide variety of resources on development methodologies, and considerably less on the nitty gritty of making sure that an ontology remains use case-aligned and usable for years to come. Lack of guidance can result in vague ontology management plans that don’t fully account for the actions that will need to be taken. This article will go over the five key components to an effective ontology versioning and management plan. After reading, you will be able to pursue ontology management confident that you have the details down.
Accommodating Change
Ontologies are not static artifacts. They grow as new use cases are identified and brought on, and develop as the content and understanding that underpins them changes. Sometimes, the process of deploying an ontology leads to these changes, as the business understanding of how the ontology will be applied is refined. For example, one of our clients began their modeling project with the goal of creating a standardized set of canonical data schemas. As the project approached implementation and met roadblocks, the team realized that what data consumers really needed were trusted data products made available through an internal data catalog, rather than additional schemas. Modeling and governance practices shifted to support the new use case, and the project was successful thanks to a greater alignment with data consumer needs.
Whatever the source of change, the ontology will need to have a plan in place to ensure that updates are transparent, maintain interoperability, and can scale. To ensure that the goals of transparency and interoperability are met requires a robust approach to versioning, as part of a comprehensive governance plan. Periodic change is common to ontologies, especially in the first year of development. We have seen clients completely change their approach to modeling relationships, or who decide to move away from reusing open ontology models that weren’t well suited to their use case. In both those instances, the client needed a way to communicate the magnitude of the change, and ensure that users aligned to the newest version of the ontology.
Versioning is the ability to track and communicate what changes have been made to a file as it is updated. Generally, new versions are identified through the use of a version number, and come with information on what changes were made. Like updates to a piece of software, versioning lets users know when there is a more up-to-date version of the ontology they should move onto, and what changes were made. Versioning is critical to making sure that integrations with the ontology stay aligned Versioning can also communicate the level of changes made via an update, and whether those changes are backwards compatible or not. Tracking changes via a versioning plan is the key to ensuring usability of an ontology over time, as well as its longevity in the face of change. This leads into the first tip:

1. Track Version Information within the Ontology
There are a number of places where a version number can be tracked and delivered to consumers. One of the best places to track this information is within the ontology itself, using a datatype property. This has the benefits of making sure that the ontology cannot be separated from its version information, and that this information is easy for the ontologist to access and update.
OWL ontologies can use the preexisting OWL attribute owl:versionInfo to store version information. If the OWL standard is not in use, then version information can be tracked using rdfs:comment or an annotation property assigned by the editor. Semantic Web Company’s PoolParty Thesaurus Manager (PPT), for instance, uses rdfs:comment to track description information and can be used to record a version number for ontologies. TopQuadrant’s TopBraid EDG Ontology editor defines a custom attribute, http://topbraid.org/metadata#version or metadata:version, to store ontology version information.

Example of how rdfs:comment can be used to store a version number in PPT. In this example, the version number is 1.2.0
Regardless of which standard you use, the key is to ensure the version info can always be found alongside the ontology, and that the version info can be updated easily when changes are committed.
Be Aware: Some ontologies track the version number in the namespace of the ontology. Tracking the version number like this means that the namespace changes with every new update, which can cause difficulties with software integrations. As a result, this method of version tracking is generally not recommended.
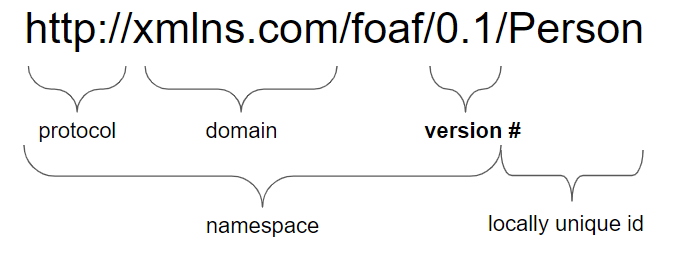
One example of a namespace with a version number is the FOAF ontology namespace, pictured above. For more information on namespace and URIs, check out Resolving Uniform Resource Identifiers.

2. Use the Semantic Versioning (SEMVER) Standard
The Semantic Versioning specification, or SEMVER, is a software development standard that guides how to create and apply version numbers in such a way that users can understand the level of changes made. Within SEMVER, version numbers are constructed following a pattern of X.Y.Z where X is the major version number, Y is the minor version number, and Z is the patch version number.
 A mock version number. In this example, 8 is the major version number, 1 is the minor version number, and 7 is the patch version number. Note that the “Version” is not a part of the number, and not required under SEMVER.
A mock version number. In this example, 8 is the major version number, 1 is the minor version number, and 7 is the patch version number. Note that the “Version” is not a part of the number, and not required under SEMVER.
The Major version number is incremented when updates are made that will cause a break in backwards compatibility. The Minor version number is incremented when updates are made that add functionality without causing a break in backwards compatibility. Finally, the Patch version number is reserved for bug fixes that do not cause a break in backwards compatibility. The Patch version number is less commonly used alongside ontologies, as an ontology editor will typically be able to catch any RDF issues as part of its quality assurance features. More information detailing how to use this standard can be found within the documentation.
By following the SEMVER rules for the construction of version numbers, the ontology will communicate an update’s level of impact to users. Changes to the major version number signal that there may be required updates to integrations with the ontology, while minor and patch number changes do not. It ensures that the ontology versioning follows the best practices of a widely adopted standard.
Note: Not every change that first appears to break backwards compatibility actually will, depending on implementation. Consider first if the entity being updated is in use within a source system. If the entity is not in use, then it can safely be altered or removed without affecting compatibility. Generally, anything not in use by another system can be safely changed or removed without requiring a major change process.
 3. Have a Plan for Deprecation
3. Have a Plan for Deprecation
Removing outdated modeling is a reality of ontology upkeep and development. Privacy and security in particular are two areas that we often see evolve as an organizational understanding of how to enforce privacy and security develops and language shifts. When this happens, the previous concepts and terms need to be sunsetted once their replacements become available.
Just deleting the entities everytime that modeling becomes outdated will quickly rack up potentially breaking changes however, and this can lead to wide disruption of downstream consuming systems. Instead of immediately deleting the outdated entities, it is better to deprecate them first.
Unlike deletion, deprecation does not immediately remove a piece of modeling. Instead, deprecation involves signaling that the modeling in question is no longer supported, and will be removed in the future. Deprecation should also indicate where possible what modeling should be used instead of the deprecated modeling.
Deprecating before deletion allows for ontology users to prepare for upcoming breaking changes. The deprecated entity should clearly state that it is deprecated, why it was deprecated, and point to possible replacements if any exist. Deprecated entities should be easily distinguished from non-deprecated entities in the editor. The open-source ontology editor Protégé will automatically strike through deprecated concepts, for example.
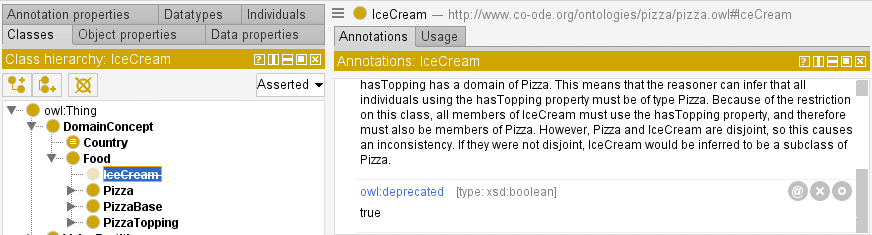 Example of a deprecated class in Protégé.
Example of a deprecated class in Protégé.
Deprecated concepts can also be distinguished by adding “(Deprecated)” to the end of the label. Following these rules for deprecation will help to preserve backwards compatibility in the short term, while ensuring that users move away from outdated modeling before it is removed.
Bonus Tip: Deprecated entities should stay in the ontology until the next major change, at which point they should be removed. This helps to group major changes together, while also giving ontology users time to move off of the deprecated entities.
 4. Keep a Changelog
4. Keep a Changelog
Data consumers will want to know what changes were made between versions. If you are using a version control system like git or GitHub, then the changes made between versions will automatically be reflected in the file comparison, also known as a diff. It is important to note here that these systems track every change in the RDF serialization. Normal RDF editors do not write entities in a specific order, so changes in that order will be incorrectly flagged by the diff as updates to the ontology. We typically avoid this by using an extension that sorts the RDF when it is written, such as the Ordered Turtle Serializer for rdflib, or TopBraid’s Sorted Turtle.
Alternatively, the record of these changes can be tracked and delivered by the ontologist, either through a note attached to new version publications or an excel sheet documenting the changes. One example of this is the Financial Industry Business Ontology, or FIBO, which maintains an extensive record of changes made within each revision as part of their release notes. Note that manual tracking can quickly become overwhelming, so look to automate where possible when producing a changelog.
 5. Deliver the Right Version
5. Deliver the Right Version
Once an ontology has been versioned, you need to make sure that the correct version of the ontology is being delivered to users. While it may be tempting to simply delete and replace the old version, there may be consumers who need to stay on a prior ontology version temporarily. Rather than deletion, look into providing both Ontology IRI and an Ontology Version IRI endpoints alongside exports. The Version IRI endpoint is a link or identifier that points to a specific version of the ontology, while the more general Ontology IRI is a link or identifier that points to the latest version of the ontology. Manchester University’s Protégé pizza tutorial ontology distinguishes between its IRIs by adding the version number to the end of the version IRI.
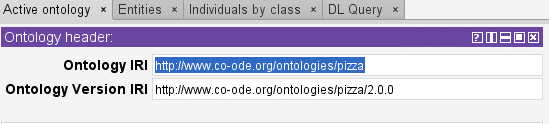
The Manchester University pizza tutorial ontology IRIs. Note that Protégé automatically supports the use of both IRI types, as do other editors like TopBraid EDG.
Another approach is to create a publicly available archive that hosts prior versions of the ontology. Consumers who are unable to move onto the latest version of the ontology can then have uninterrupted access to the modeling they need. Be sure to communicate that prior versions are no longer being updated, however. Trying to maintain and update different ontology versions can quickly get out of hand. Also make sure that the location of the latest version is stable and does not change.
While it may be easy to overlook, having a versioning plan in place is an important part of maintaining the long-term usability of an ontology. These are our top considerations and tips if you and your team are looking to understand what it takes to develop and maintain your model. Here at Enterprise Knowledge, we work with a wide variety of clients helping them to create and manage ontologies, and help our clients to create the customized versioning and governance plan that best suits their needs. If you would like to learn more about ontology versioning and governance, reach out to us to learn more about how we can create a customized plan together.