
The way we consume, create, and engineer information has changed dramatically, with the last several years demonstrating a marked transformation due to Artificial Intelligence (AI). According to a recent report, Generative AI adoption has reached a tipping point, with nearly 40% of adults adopting GenAI within just two years. That’s faster than the rise of smartphones and other major technological shifts, sending a clear message that AI integration can no longer be considered “experimental” and is instead becoming core infrastructure for mature knowledge-and-data-driven enterprises.
At the same time, while leaders see it as the next major organizational disruptor, that excitement is tempered by very real organizational challenges. Poor data quality, unclear governance models, and the sheer volume of overlapping tools flooding the market have left many organizations overwhelmed rather than empowered, increasing pressure to demonstrate return on investment (ROI) and move beyond pilots and proofs of concept.
By 2025, many organizations experienced record levels of churn driven by decision paralysis, stalled pilots, and slow realization of tangible value. Early adopters moved fast (but not always cohesively), resulting in disconnected platforms, siloed data estates, and AI initiatives that failed to scale. We are now seeing a shift where leaders are recognizing that, in this environment, standing still is not a safe choice but a step back; it widens the gap between leaders who operationalize AI and those who remain stuck in perpetual experimentation.
At Enterprise Knowledge, the question we’re now helping organizations navigate is no longer whether AI should be adopted or how to select the “best” AI tool, but how to architect it cohesively and at scale. It’s about intentionally designing a connected knowledge, data, and AI ecosystem. It’s through this shift in thinking that we explore the core components and key considerations of the technology ecosystem we’re seeing emerge and scale across organizations. This shift focuses on foundational data and governance for modern knowledge platforms and AI-enabled experiences. In this blog, we’ll outline what it takes to move beyond experimentation and build an ecosystem that supports the evolution of technology and is readily adopted by the organization.
Mixed User Ecosystem: Designing for Humans and Machines
For a long time, the standard assumption was simple: there would always be a human at the end of the content and data pipeline and curation. A content manager would create and approve workflows, a full-stack developer would expose data through an API and a web app, and a data analyst would write SQL and turn datasets into dashboards inside a BI tool. Content and data curation, governance, and delivery were all designed with those human intermediaries in mind.
This assumption no longer holds true. Today, a growing share of an organization’s “knowledge and data consumers” aren’t people alone; they’re increasingly becoming AI models, algorithms, and autonomous agents. These systems need to discover, understand, and use data on their own, clean it up, or fill in the gaps. This shift is what is changing the bar for how data and knowledge must be managed. It’s no longer enough for data to be intuitive for human comprehension – it also needs to be recognizable and understandable to machines.
While the requirements between these human and AI consumers overlap, they are not identical. Whereas people can infer meaning from fragmented content or tribal knowledge, AI solutions need something stricter. They need content and data that is granular, self-describing, consistent, and structurally complete. Ambiguity, missing context, or informal conventions that humans can work around quickly become blockers for machines. In short, we’re moving from a world where data was explained to one where it must explain itself. That shift has profound implications for how we design knowledge, data, and AI platforms and the capabilities that sit on top of them.
Ubiquitous AI (within Enterprise Applications)
AI is rapidly becoming a foundational layer in enterprise software, embedded directly into everyday applications rather than added as a standalone capability.
We see this integration everywhere, driving personalization and automation of repetitive tasks directly within enterprise applications, such as Adobe Photoshop suggesting edits, GitHub Copilot assisting with code, and enterprise platforms like ServiceNow and Salesforce putting AI directly into their workflows.
As AI embeds into the background, making applications smarter and more autonomous, user adoption is naturally rising as well. This trend is supported by findings from a 2025 Gallup Workforce study, which indicated that 45% of U.S. employees use AI for work-related tasks at least a few times annually, with much higher usage in knowledge-based roles. Technology-focused employees, in particular, are using AI to summarize information, generate ideas, and learn new skills (mostly through chatbots, virtual assistants, and writing tools). More advanced capabilities, like coding assistants and analytics platforms, tend to be adopted by employees who are already using AI frequently.
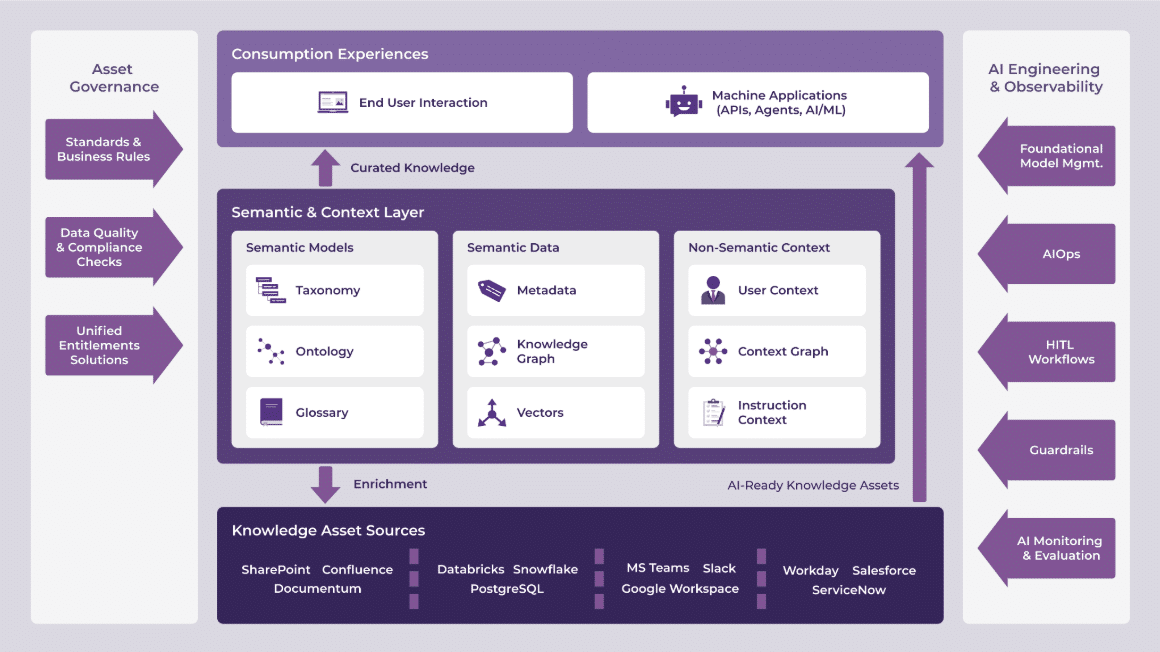
The Semantic & Context Layer
Organizations are realizing that basic or “naive” AI is falling short of delivering on its promise (especially in complex enterprise use cases). The problem usually isn’t the models themselves; it’s that organizations lack structured, shared, and repeatable ways to provide meaning and context to their fragmented knowledge and data.
This convergence of the semantic layer and operational context is setting the new foundation for reliable AI performance and becoming the focal point within modern enterprise architectures. It is creating a modular, “glass box” foundation that favors transparency and factual accuracy over black-box models that rely on pattern matching.
A key, vendor-agnostic approach on the rise to help organizations take practical steps (no matter their technical maturity) is the semantic layer framework. Built on proven foundations such as metadata, taxonomies, ontologies, business glossaries, and graph solutions, this layer continues to provide the standards and methods for organizing knowledge and data while enabling companies to separate their core knowledge assets from specific applications. This framework isn’t new, but it is becoming essential as AI moves from experimentation to production.
A metadata-first semantic layer provides a unified, standards-based framework for context, governance, and discovery across enterprise data. It makes data accessible through a shared logical layer (often a knowledge graph) exposed via APIs in machine-readable formats that work equally well for people and AI agents. Organizations that have a shared semantic contract in place are able to connect secure, metadata-rich knowledge assets regardless of where they’re created or consumed, and serve both human and machine needs from the same source of meaning.
Finally, the different types of graphs we continue to employ are evolving beyond standard knowledge graphs toward context graphs. While knowledge graphs define and map facts and entities, context graphs add the ‘when, where, and why’ through decision traces (why judgment), temporal awareness (signals like time and location), working memory (user intent and in-progress interactions), and user profile information (role, preferences, and interaction history).
Knowledge Asset Layer & AI Readiness
Many enterprise architecture challenges stem from the absence of a clear framework to connect and interpret all forms of organizational knowledge: structured data, unstructured content, human expertise, and business rules, collectively known as organizational knowledge assets.
As a result, today’s data and technology leaders are being stretched in every direction. While data architects and engineers are still wrestling with very real, persistent issues like data silos, misalignment with business goals, and pressure to show immediate ROI, their mandates have significantly expanded. A big driver of this expansion and complexity is Generative AI, which has pulled unstructured data into the spotlight – emails, documents, chat logs, policies, and research reports (over 80% of organizational assets). This information usually lives in different systems, owned by different teams, and has historically sat outside the purview of data and analytics leaders. As a result, many of the challenges organizations face with AI today stem from the lack of a clear framework for organizing and interpreting their knowledge assets within the context of the business.
In this realm, the biggest architectural shift happening now is toward connection and interoperability. Organizations are realizing that AI readiness isn’t just about models. It’s about preparing operating models, systems, and teams so AI can do what it does best without having to navigate organizational silos or politics. As such, these emerging AI ecosystems are investing in solutions that support reliable, structured, and understandable knowledge management as a trusted foundation that can turn fragmented information into true knowledge intelligence for the organization.
Monitoring, Observability, and Unified Access & Entitlements
The quality of AI output is only as good as the data behind it. That’s why unifying knowledge management, data, and AI governance matters to enforce consistent data quality standards and ensure that AI systems leverage accurate and properly secured data to produce more reliable outcomes. Responsible enterprise AI architecture depends on a unified governance framework built around three essentials: strong monitoring, comprehensive observability, and strict access controls, all essential for managing the inherent risks of autonomous systems.
AI monitoring and transparency starts at design time, where AI solutions should have a clearly defined purpose, explicit constraints, and a known set of tools they’re allowed to use. For agentic solutions, it’s also important for agents to expose reasoning steps to users, while backend systems log context, tool calls, and memory usage for debugging. We have been working with observability platforms (e.g., MLFlow, Azure AI Foundry) to help teams trace decision paths, detect anomalies, and continuously refine behavior using feedback from both users and testers. When it is done well, we find that these governance frameworks and guardrails support innovation instead of slowing it down.
When it comes to security, AI models and agents need a very different approach than traditional, static access policies. Instead of rigid, application- or group-level permissions, AI requires dynamic, context-aware access, granted at the domain, concept, and data levels, based on the task at hand. Unified entitlements are especially powerful here, providing a consistent definition of access rights across all knowledge assets (for both humans and AI). In practice, this means restricting an agent’s access to specific attributes on specific nodes within a graph setting, rather than locking down or exposing entire systems or datasets.
Finally, organizations are investing in solutions that will give them reliable ways to consistently observe and evaluate AI efficacy. Alongside broader quality, risk, and safety checks, observability includes task-level metrics such as intent resolution, task adherence, tool selection accuracy, and response completeness. Advanced telemetry analytics also provide additional insight into performance, latency, cost, and efficiency trade-offs, even though they aren’t strictly measured.
The bottom line is that today’s AI systems, especially agentic and non-deterministic models, require going beyond traditional observability. By implementing end-to-end observability frameworks, organizations are starting to gain deep visibility into internal decision-making, execution lineage from input to output, performance, and detecting unauthorized tool or API use proactively.
Conclusion & Looking Ahead
The abundance of AI tools and the rise of AI agents are fundamentally changing how we engage with technology. Successfully leveraging AI within the enterprise starts with understanding the full knowledge, data, and AI ecosystem.
The primary effort and value is first in connecting structured and unstructured data, making human expertise machine-readable, and capturing business rules as a unified, context-rich foundation. As a result, the conventional architectures of knowledge portals, data lakehouses, and data science workbenches, as we have known them, are becoming obsolete. A new, unified KM, data, and AI architecture is now necessary, one that can support distributed intelligence, ensure secure access to knowledge assets regardless of their source, and maintain continuous monitoring for modular, reliable, and consistent performance.
If you are in the process of evaluating your ecosystem and architecture, learn more from our case studies on how other organizations are tackling this, or email us at info@enterprise-knowledge.com for more information or support.