
Introduction
In today’s data-driven world, effective data management is crucial for businesses to remain competitive. A modern approach to data management is the use of data fabric architecture. A data fabric is a data management solution that connects and manages data in a federated way, employing a logical data architecture that captures connections relevant to the business. Data fabrics help businesses make sense of their data by organizing it in a domain-centric way without physically moving data from source systems. What makes this possible is a shift in focus on metadata as opposed to data itself. At a high level, a semantic data fabric leverages a knowledge graph as an abstraction architecture layer to provide connectivity between diverse metadata. The knowledge graph enriches metadata by aggregating, connecting, and storing relationships between unstructured and structured data in a standardized, domain-centric format. Using a graph-based data structure helps the business embed their business data with context, drive information discovery and inference, and lay a foundation for scale.
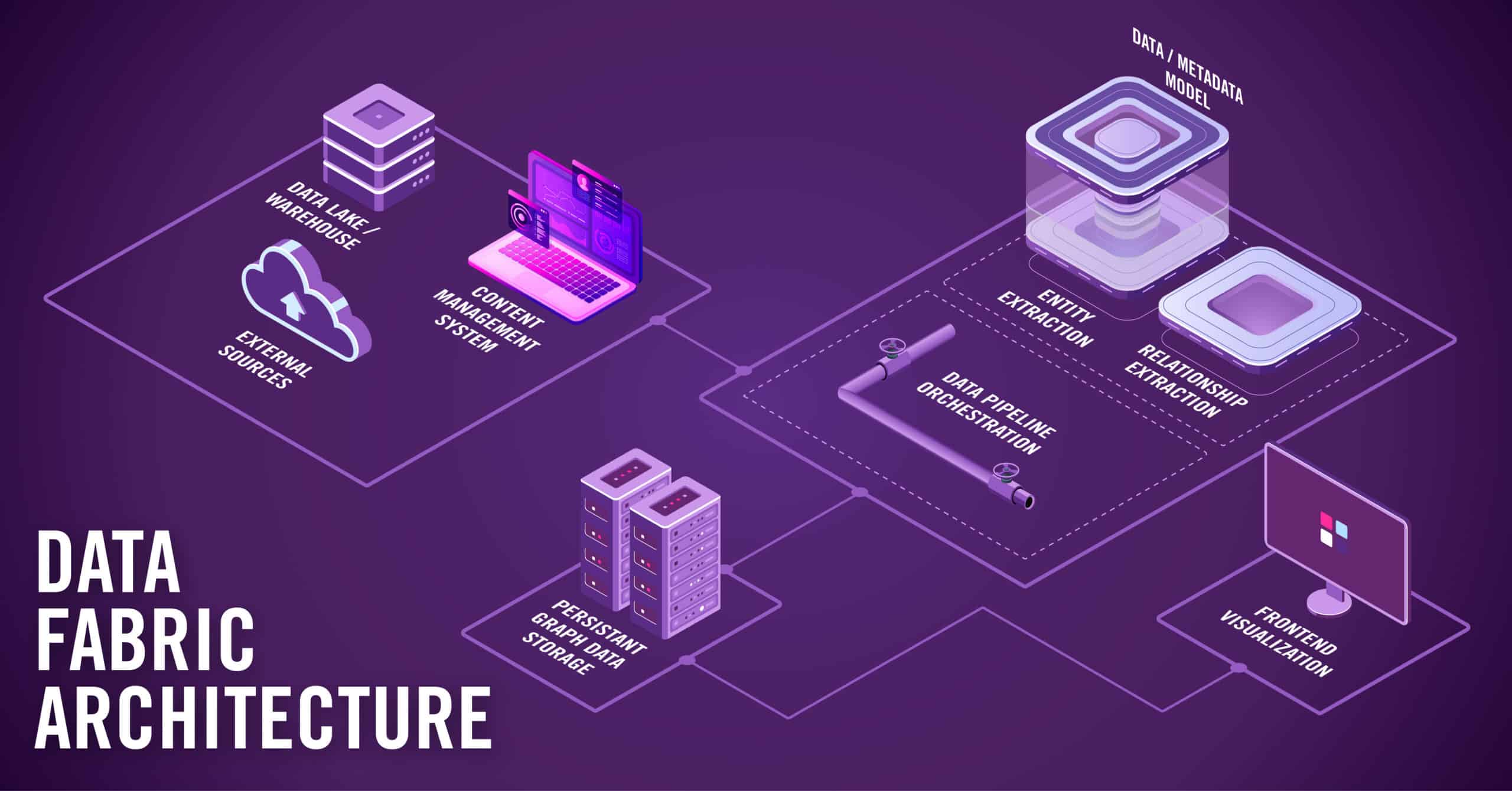
Unlike a monolithic solution, a data fabric facilitates the alignment of different toolsets to enable domain-centric, integrated data as a service to multiple downstream applications. A data fabric architecture consists of five main components:
- A data/metadata model
- Entity extraction
- Relationship extraction
- Data pipeline orchestration
- Persistent graph data storage.
While there are a number of approaches to designing all of these components, there are best practices to ensure the quality and scalability of a data fabric. This blog post will enumerate the approaches for each architectural component, discuss how to achieve a data fabric implementation from a technical approach and tooling perspective that suits a wide variety of business needs, and ultimately detail how data fabrics support the development of artificial intelligence (AI).
Data/Metadata Model
Data models – specifically, ontologies and taxonomies – play a vital role in building a data fabric architecture. An ontology is a central aspect of a data fabric that defines concepts, attributes, and relationships in a domain that is encoded in a machine and human-readable graph format. Similarly, a taxonomy is essential for metadata management in a data fabric, storing extracted entities and defining controlled vocabularies for core business domains like products, business lines, services, and skills. By creating relationships between domains and data, businesses can help users find insights and discover content more easily. Therefore, to effectively manage taxonomies and ontologies, business owners need a Taxonomy/Ontology Management System (TOMS) that provides a user-friendly platform and interface. A good TOMS should:
- Help users build data models that follow common standards like RDF (Resource Description Framework), OWL (Web Ontology Language), and SKOS (Simple Knowledge Organization System);
- Let users configure the main components of a data model such as classes, relationships, attributes, and labels that define the concepts, connections, and properties in the domain;
- Add metadata about the data model itself through annotations, such as its name, description, version, creator, etc.;
- Support automated governance, supporting quality checks for errors;
- Allow for easy portability of the data model in different ways, serving multiple enterprise use cases; and
- Allow users to link to external data models that already exist and can be reused.
Organizations that do not place their data modeling and management at the forefront of their data fabric introduce the risk of scalability issues, limited user-friendly schema views, and hampered utilization of linked open data. Furthermore, the absence of formal metadata management poses a risk of inadequate alignment with business needs and hinders flexible information discovery within the data fabric. There are different ways of creating and using data models with a TOMS to avoid these risks. One way is to use code or scripts to generate and validate the data model based on the rules and requirements of the domain. Using subject matter expertise input helps to further validate the data model and confirm that it aligns with business needs.
Entity Extraction
One of the functions of building your data fabric is to perform entity extraction. This is the process of identifying and categorizing named entities in both structured and unstructured data, such as person names, locations, organizations, dates, etc. Entity extraction enriches the data with additional information and enables semantic analysis. Identifying Named Entity Recognition (NER) tools and performing text preprocessing (e.g., tokenization, stop words elimination, coreference resolution) is recommended before determining an entity extraction approach, of which there are several: rule-based, machine learning-based, or a hybrid of both.
- Rule-based approaches rely on predefined rules that use syntactic and lexical cues to extract entities. They require domain expertise to develop and maintain, and may not adapt well to new or evolving data.
- Machine learning-based approaches use deep learning models that can learn complex patterns in the data and extrapolate to unseen cases. However, they may require large amounts of labeled data and computational resources to train and deploy.
- Hybrid approaches (Best Practice) combine rule-based and machine learning-based methods to leverage the strengths of both. Hybrid approaches are recommended for businesses that foresee expanding their data fabric solutions.
Relationship Extraction
Relationship extraction is the process of identifying and categorizing semantic relationships that occur between two entities in text, such as who works for whom, what business line sells which product, what is located in what place, and so on. Relationship extraction helps construct a knowledge graph that represents the connections and interactions among entities, which enables semantic analysis and reasoning. However, relationship extraction can be challenging due to the diversity and complexity of natural language.There are again multiple approaches, including rule-based, machine learning-based, or hybrid.
- Rule-based approaches rely on predefined rules that use word-sequence patterns and dependency paths in sentences to extract relationships. They require domain expertise to develop and maintain, and they may not capture all the possible variations and nuances of natural language.
- One machine learning approach is to use an n-ary classifier that assigns a probability score to each possible relationship between two entities and selects the highest one. This supports capturing the variations and nuances of natural language and handling complex and ambiguous cases. However, machine learning approaches may require large amounts of labeled data and computational resources to train and deploy.
- Hybrid approaches (Best Practice) employ a combination of ontology-driven relationship extraction and machine learning approaches. Ontology-driven relationship extraction uses a predefined set of relationships that are relevant to the domain and the task. This helps avoid generating a sparse relationship matrix that results in a non-traversable knowledge graph.
Data Pipeline Orchestration
Data pipeline orchestration is the driving force of data fabric creation that brings all the components together. This is the process of integrating data sources with two or more applications or services to populate the knowledge graph initially and update it regularly thereafter. It involves coordinating and scheduling various tasks, such as data extraction, transformation, loading, validation, and analysis, and helps ensure data quality, consistency, and availability across the knowledge graph. Data pipeline orchestration can be performed using different approaches, such as a manual implementation, an open source orchestration engine, or using a vendor-specific orchestration engine / cloud service provider.
- A manual approach involves executing each step of the workflow manually, which is time-consuming, error-prone, and costly.
- An open source orchestration engine approach involves managing ETL pipelines as directed acyclic graphs (DAGs) that define the dependencies and order of execution of each task. This helps automate and monitor the workflow and handle failures and retries. Open source orchestration engines may require installation and configuration, and businesses need to take into account the required features and integrations before opting to use one.
- Third-party vendors or cloud service providers can leverage the existing infrastructure and services and provide scalability and reliability. However, vendor specific orchestration engines / cloud service providers may have limitations in terms of customization and portability.
Persistent Graph Data Storage
One of the central ideas behind a data fabric is the ability to store metadata and core relationships centrally while connecting to source data in a federated way. This manage-in-place approach enables data discovery and integration without moving or copying data. Persistent graph data storage is the glue that brings all the components together, storing extracted entities and relationships according to the ontology, and persisting the connected data for use in any downstream applications. A graph database helps preserve the semantic relationships among the data and enable efficient querying and analysis. However, not all graph databases are created equal. When selecting a graph database, there are 4 key characteristics to consider. Graph databases should be: standards-based, ACID compliant, widely-used, editable, and explorable via a UI.
- Standards-based involves making sure the graph database follows a common standard, such as RDF (Resource Description Framework), to ensure interoperability so that it is easier to transition from one tool to another.
- ACID compliant means the graph database ensures Atomicity, Consistency, Isolation, and Durability of the data transactions, which protects the data from infrastructure failures.
- Strong user and community support ensures that developers will have access to good documentation and feedback.
- Explorable via a UI supports verification by experts to ensure data quality and alignment with domain and use case needs.
Some of the common approaches for graph databases are using RDF-based graph databases, labeled property graphs, or custom implementations.
- RDF-based graph databases use RDF which is the standard model for representing and querying data.
- Labeled property graph databases use nodes, edges, and properties as the basic elements for storing and querying data.
Data Fabric Architecture for AI
A mature data fabric architecture built upon the preceding standards plays a pivotal role in supporting the development of artificial intelligence (AI) for businesses by providing a solid foundation for harnessing the power of data. The data fabric’s support for data exploration, data preparation, and seamless integration empowers businesses to harness the transformative and generative power of AI.
By leveraging an existing data fabric architecture, businesses can seamlessly integrate structured and unstructured data, capturing the relationships between them within a standardized, domain-centric format. With the help of the knowledge graph at the core of the data fabric, businesses can empower AI algorithms to discover patterns, make informed decisions, and generate valuable insights by traversing and navigating the graph. This capability allows AI models to uncover valuable insights that are not immediately apparent in isolated data silos.
Furthermore, data fabrics facilitate the process of data preparation and feature engineering, which are crucial steps in AI development. The logical architecture of the data fabric allows for efficient data transformation, aggregation, and enrichment. By streamlining the data preparation pipeline, AI practitioners can focus more on modeling and algorithm development, accelerating the overall AI development process. AI models often need continuous refinement and adaptation, and data fabrics enable seamless integration of new data sources and updates to ensure that AI models have the most up-to-date information.
Conclusion
A data fabric is a modern approach to data management that is crucial for businesses to remain competitive in a data-driven world. However, a data fabric is not a monolithic solution and the supporting architecture and technical approach can vary based on the state of sources, supporting use cases, and existing tooling at an organization. It’s important to prove out the value of the solutions before investing in costly tool procurement. We recommend starting small and iterating, beginning with a targeted domain in mind and sample source systems to lay a foundation for an enterprise data fabric. Once a data fabric has been established, businesses can unlock the full potential of their data assets, enabling AI algorithms to make intelligent predictions, discover hidden insights, and drive valuable business outcomes. Looking for a kick-start to get your solutions off the ground? Contact us to get started.