
Many organizations begin their journey in semantic solutions with a taxonomy. Taxonomies are simple information models that help organizations describe and structure their information in a hierarchy. They are effective for organizing content and data, but do not capture all of the rich context and meaning that makes information easy to find and understand. More flexible models, such as ontologies or knowledge graphs, allow meaningful connections to be made between information sources, addressing many of the limitations of a taxonomy. In this article, we discuss these limitations and how building an Enterprise Knowledge Graph is the best next step for evolving information management solutions beyond the use of taxonomies.
What does a modern taxonomy do?
Taxonomies are a proven means of describing content using a controlled vocabulary. A modern taxonomy improves findability by being flexible and allowing faceting. Users can cross-cut information during search and browse facets to narrow down huge amounts of information to what they are specifically looking for. Giant e-commerce sites like Amazon have made taxonomies familiar to everyday online shoppers in their product search, even if not by name. However, the value and use of taxonomies is not limited to faceted searching or browsing. Taxonomies also serve as the foundations of autotagging, ontology design, and the implementation of knowledge graphs and AI capabilities. At its core, a taxonomy describes the domain of information through a standardized vocabulary, capturing synonyms and alternative ways of describing the same concept, as well as basic relationships between concepts (broader, narrower, and related terms). This initial structuring of an information domain can then be leveraged by knowledge graphs and AI, making taxonomies an essential building block for advanced semantic solutions. Organizations who understand the value of taxonomies and how they enable future technologies will be better poised to take advantage of AI and semantic tools.
Limitations of a taxonomy that are opportunities for a knowledge graph
Strict Hierarchies can be limiting
A taxonomy is a controlled vocabulary structured in a hierarchy where narrower or child terms are grouped under broader terms, or parent terms, making a tree structure. A common example of a taxonomy tree structure is a geographical hierarchy. On the first level of this model, we may have countries, then within each country, we can break down the geographical categories into smaller groups, such as states or provinces, and within each state, cities. However, consider if we also wanted to include continents in this model. Some countries, for example, Egypt, are transcontinental and span more than one continent (Africa & Asia). If we added continents as broader terms in o ur taxonomy, we would end up with polyhierarchy, or the same country appearing in more than one location in the taxonomy. Because the relationships in a taxonomy are limited to “broader than”, “narrower than”, and “related to”, it’s often difficult to understand what a polyhierarchy means. In our geographic taxonomy, we might guess that a narrower term is located within a broader term, but how do we interpret a term, like Egypt, that would have two broader terms in this design? Does the model mean that Egypt as a whole is located in both Africa and Asia, or, that Egypt is partially in one continent and partially in the other? The problem is we only have the “broader than” and “narrower than” relationships to handle this nuance in meaning. Instead, if we can take a different approach and design a more flexible ontology with specific relationships like “is partially in”, the ambiguity presented by taxonomy polyhierarchies can be avoided entirely.
ur taxonomy, we would end up with polyhierarchy, or the same country appearing in more than one location in the taxonomy. Because the relationships in a taxonomy are limited to “broader than”, “narrower than”, and “related to”, it’s often difficult to understand what a polyhierarchy means. In our geographic taxonomy, we might guess that a narrower term is located within a broader term, but how do we interpret a term, like Egypt, that would have two broader terms in this design? Does the model mean that Egypt as a whole is located in both Africa and Asia, or, that Egypt is partially in one continent and partially in the other? The problem is we only have the “broader than” and “narrower than” relationships to handle this nuance in meaning. Instead, if we can take a different approach and design a more flexible ontology with specific relationships like “is partially in”, the ambiguity presented by taxonomy polyhierarchies can be avoided entirely.
Taxonomies lack attributes that describe the taxonomy terms themselves
A taxonomy model includes only the terms and their synonyms, not additional attributes about the terms, or metadata about the metadata. It is important to capture additional details about the terms in a taxonomy such as how/where they can be used, what systems consume them, or when they were last reviewed/approved, etc. Many taxonomy management systems utilize SKOS, the Simple Knowledge Organization System, which is a simple ontology commonly used to model a taxonomy by adding a few additional attributes such as Scope Notes, Definition, and Hidden Labels, as well as a generic Related To relationship. However, even with SKOS, it is not possible to define explicit or custom attributes for the taxonomy terms. Just as in the previous example, we are limited by the constraints the structure of a taxonomy gives us.
Taxonomies cannot infer or recommend
Taxonomies mainly describe information and do not have the structures required to provide meaningful inferences to further find relationships between different pieces of information. The only way you might infer information with a taxonomy is by following hierarchical relationships — for example, if two concepts share the same parent concept, you might infer that they are similar or related in nature, but without domain expertise, you can’t understand exactly how they are related. Using a more complex ontology, you can create and specify many non-hierarchical relationships that you could use to infer, increasing the flexibility of your data and removing the ambiguity and limitations created by the strictly hierarchical relationships possible in a taxonomy. Advanced semantic applications like natural language processing and recommendation engines based on explicit or inferred relations between terms are not possible without enhancing your taxonomy with an ontology that describes an organization’s information domain, otherwise known as a knowledge graph.
How taxonomies can be used with a knowledge graph
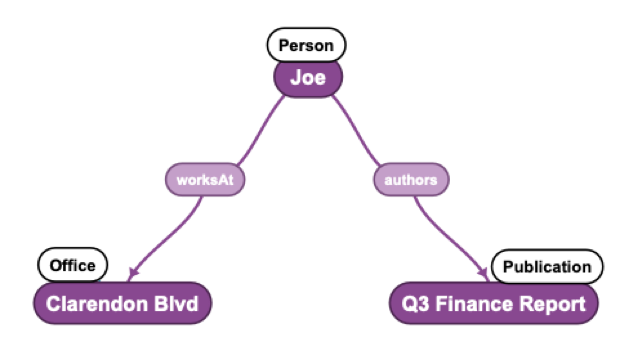
Knowledge graphs are semantically meaningful ontologies that describe and relate sets of information entities relevant to an organization’s information domain. For example, a very simple knowledge graph could include people, publications, and offices as entities. Some relationships between the entities could be: people “author” publications and “work at” offices. The main challenge of designing an effective knowledge graph is developing its model, which identifies the different types, or classes, of entities, what relationships they have, and how they should be described. Taxonomies are especially helpful as input to the development of a knowledge graph. Here are a couple of ways taxonomies are used to develop and improve knowledge graphs:
Sources of Controlled Lists
The greatest advantage of having a taxonomy or set of taxonomies is the establishment and curation of controlled lists of business terms. The effectiveness and relevance of a knowledge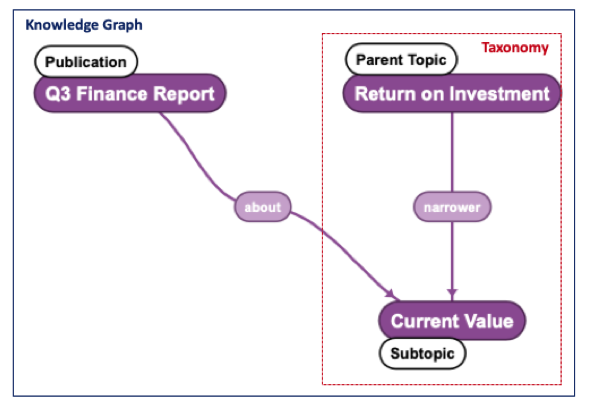 graph will depend on what metadata is available to arrange in the graph. By having taxonomies ready for use in other applications, the knowledge graph can tap into these lists to add rich context to an organization’s data. In addition, because the taxonomies are already structured and developed for business use, knowledge graph development will not have to begin from scratch. For example, popular taxonomies include topics, organization structure, and skills. Topic taxonomies are excellent sources of terms to describe almost any type of content including both unstructured or written content as well as data sets. One can imagine a knowledge graph that has entities like publications that can be associated with the topics they are about from a topic taxonomy. Also, org. structure and skills terms can be applied to people entities in the knowledge graph by allowing the knowledge graph to capture where they work and what they can do. The knowledge graphs in these cases are using the information contained in the taxonomy and relating it to the actual people, places, and things that taxonomy terms can describe. These relationships in the graph become a rich fabric of meaning surrounding data, content, and information that can capture complex business concepts.
graph will depend on what metadata is available to arrange in the graph. By having taxonomies ready for use in other applications, the knowledge graph can tap into these lists to add rich context to an organization’s data. In addition, because the taxonomies are already structured and developed for business use, knowledge graph development will not have to begin from scratch. For example, popular taxonomies include topics, organization structure, and skills. Topic taxonomies are excellent sources of terms to describe almost any type of content including both unstructured or written content as well as data sets. One can imagine a knowledge graph that has entities like publications that can be associated with the topics they are about from a topic taxonomy. Also, org. structure and skills terms can be applied to people entities in the knowledge graph by allowing the knowledge graph to capture where they work and what they can do. The knowledge graphs in these cases are using the information contained in the taxonomy and relating it to the actual people, places, and things that taxonomy terms can describe. These relationships in the graph become a rich fabric of meaning surrounding data, content, and information that can capture complex business concepts.
Taxonomies often have their own governance processes to ensure the lists are correct and standardized for the organization. This means the knowledge graph will not need its own governance process for the same sets of terms. Since the taxonomies will already be properly arranged and verified during the taxonomy governance process, the knowledge graph will simply “read in” the information defined by the taxonomy, as this information will already be correct and ready for use.
Initial Domain Design
Taxonomies can also provide input to the overall design of the ontology for a knowledge graph.  Knowledge graphs are structured to capture the knowledge domain of an organization. Therefore, to design the best knowledge graph, a data modeler, or ontologist, will need to understand what types of information are available at the organization and how they are related. Taxonomies often provide clues as to what the key types of information are that a knowledge graph needs to cover. This idea is similar to how taxonomies can be used to supply metadata for the graph. Instead of focusing on the exact values from the taxonomy to use in the knowledge graph, the ontologist analyzes the taxonomy to understand what entities the lists describe. From the earlier example, a skills taxonomy might describe a person that has the skill or an org. department that specializes in the skills. The entities “person” and “org. department” could be key entities in the knowledge graph design that should be related together and to other entities such as skills and given descriptive properties by the ontologist. Using the topic taxonomy example, topics typically describes different types of things that are topical in nature. For instance, the topics could describe books, the subject of an instructional course, or other types of content. In this case, the books, publications, or instructional courses could be additional entities the ontologists adds to the knowledge graph.
Knowledge graphs are structured to capture the knowledge domain of an organization. Therefore, to design the best knowledge graph, a data modeler, or ontologist, will need to understand what types of information are available at the organization and how they are related. Taxonomies often provide clues as to what the key types of information are that a knowledge graph needs to cover. This idea is similar to how taxonomies can be used to supply metadata for the graph. Instead of focusing on the exact values from the taxonomy to use in the knowledge graph, the ontologist analyzes the taxonomy to understand what entities the lists describe. From the earlier example, a skills taxonomy might describe a person that has the skill or an org. department that specializes in the skills. The entities “person” and “org. department” could be key entities in the knowledge graph design that should be related together and to other entities such as skills and given descriptive properties by the ontologist. Using the topic taxonomy example, topics typically describes different types of things that are topical in nature. For instance, the topics could describe books, the subject of an instructional course, or other types of content. In this case, the books, publications, or instructional courses could be additional entities the ontologists adds to the knowledge graph.
Relating Content for Recommendations
Another way that taxonomies can impact knowledge graphs is as tags that relate to other entities. A common example of this use case is in the development of content recommendation systems. Taxonomy terms can be used to autotag content such as articles or other documents. Then, these pieces of content can be represented in the knowledge graph with relationships to their tags. The knowledge graph can be used to identify content that shares these tags. This is precisely the set up you need for a content-filtering use case for generating recommendations for content. Content can be grouped according to similar tags and recommendations are generated from these groupings. If people and their interactions with content are also features of the knowledge graph then collaborative filtering can be used to generate recommendations. In this case, the relationships between people and content are key to determining relevant content. For instance, a coworker can share an interest in geography that is demonstrated by multiple interactions with content that are about geography. Your coworker also may like astronomy in addition to geography, but you currently have not interacted with content on astronomy yet. Astronomy can be suggested as a recommended topic for you to explore based on the shared interest in geography with your coworker. Again, using the knowledge graph, once astronomy is recommended, it is easy to identify all the content tagged with astronomy and to then recommend those to the user.
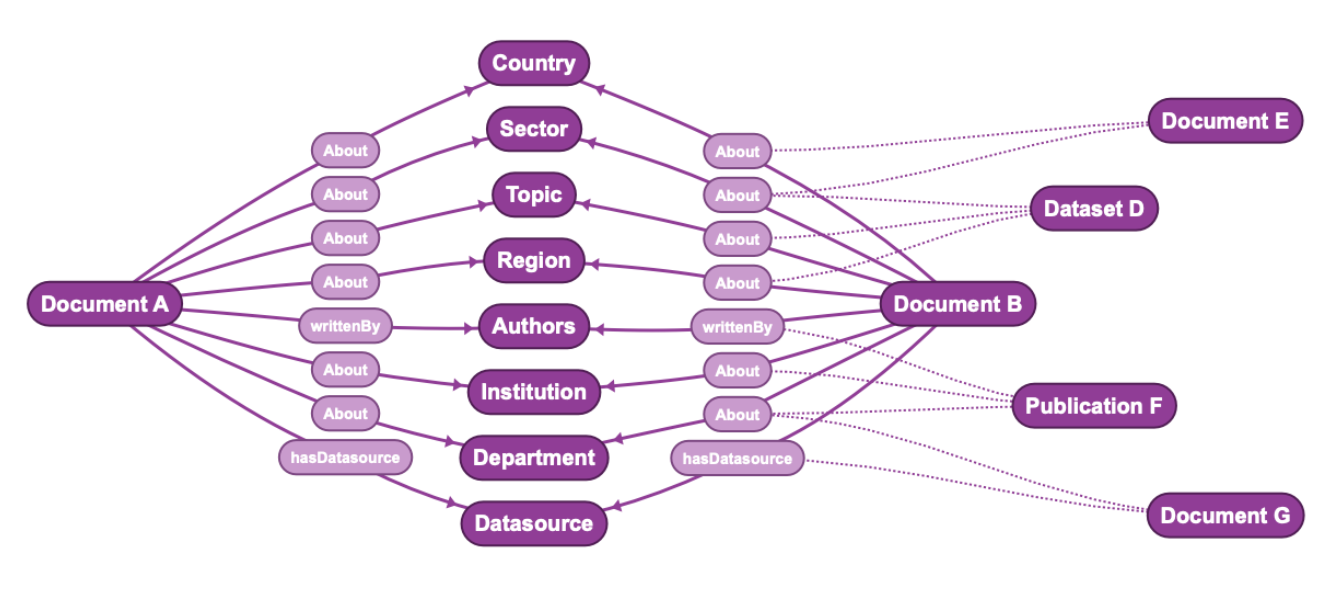
How do a taxonomy and a knowledge graph fit together from an enterprise data architecture perspective?
Taxonomies and knowledge graphs are complementary components of an enterprise data ecosystem. While a knowledge graph provides an overall structure to an enterprise data domain, the taxonomy supplies a hierarchical structure to key lists and terms that are relevant to the business. Taxonomy Management Systems (TMS) are used to manage taxonomies and give organizations the structure and governance features needed to focus on taxonomy development. On the other hand, knowledge graphs are managed using a graph database and integrate additional types of information. The compatibility of taxonomies with knowledge graphs are often reflected in their similar data models. Many of the leading TMS products utilize graph databases as their backend. If a taxonomy is stored in RDF format in a graph database and the knowledge graph is also represented using RDF, the ETL process to integrate the two models is very simple. Some TMS products will even allow storing taxonomy data in a separate graph database, meaning a taxonomy and knowledge graph data could be stored alongside each other in the same storage solution. Even when taxonomies are not modeled using graph data models, the flexibility of the knowledge graph allows the taxonomy to be quickly integrated into its data model with some basic transformations.
The bottom line
Building a knowledge graph is the best next step for developing the structure and meaningfulness of your organization’s information management model. If there are opportunities to capture more complex ideas and business logic, as well as more intuitive ways to structure information than what a taxonomy provides, it is time to consider a knowledge graph that builds on the taxonomy and can power new use cases such as semantic search, recommendation engines, and AI. Once you’ve identified the need for a knowledge graph, look for any existing taxonomies or vocabularies to leverage in the design and implementation of the enterprise knowledge graph. Reach out to EK for help. With both strategic expertise and the in-house technical skills needed to design a taxonomy/ontology or implement a knowledge graph, we’d love to partner with you to tackle your unique use cases.