
How to take an AI Project Beyond a Prototype
Before going “all in,” we often advise our clients to first understand and quickly validate the value proposition for adopting advanced Artificial Intelligence (AI) and Machine learning (ML) solutions within their organization by engaging in a beyond AI project prototype or pilot. Conducting such targeted experimentations not only provides the enterprise with a safe way to validate that AI and ML solutions will solve real problems, but also provides a design foundation for key AI elements required for their roadmap and supports long-term change management by showing immediate incremental benefits and developing interest.
Without the appropriate guidance and strategy, AI efforts may still get stalled right after a prototype or proof of concept, regardless of how successful these initial efforts may have been.
Although 84% of executives see the value and agree that they need to integrate and scale AI within their business processes, only 16% of them say that they have actually moved beyond the experimentation phase.
Mainly informed by the diverse set of organizational realities and AI projects we have delivered, below I will explore the common themes I see when it comes to potential roadblocks in moving from prototype to enterprise, and provide a selection of approaches that I have found helpful in scaling enterprise AI efforts.
1. Understand that AI projects have unique life cycles
In software delivery, Agile and DevOps continue to serve as successful frameworks for allowing iterative delivery, getting the product closer to the end user or customer and ultimately delivering immediate value. However, Enterprise AI efforts have surfaced the need to revisit Agile delivery within the context of AI and ML processes. What this means for the sponsoring organization and the teams involved is that any project management or delivery approach that is employed will need to balance the predictable nature of software programming with facilitation and ongoing education about expected machine outcomes for the end-user and subject matter expert (SME), while balancing the random number of experimental data ingestion and model refinement required for AI deliverables.
Enterprise AI projects typically have a number of workstreams or task areas that need to be at play, in parallel. These include use case definition, information architecture, data mapping and modeling, integration and pipeline development, the data science side of things where there are multiple Machine Learning (ML) processes running, and, of course, the software engineering aspect that is required to connect with downstream or upstream applications that will render the solution to end users. With all these variables at play, the following approaches help to build a more AI-centric delivery framework:
- Sprints for data teams are different: While software programming or development is focused on predefined applications or features, the primary focuses for data science and machine learning tasks are analysis, modeling, cleaning, and exploration. Meaning, the data is the center of the universe and the exploration process is what determines the outcome or the features being delivered. The results from the machine and data exploration phase could result in the project having to loop back to the planning phase. As such, the data workstream doesn’t necessarily need to be within or work through the same sprint as the development team.
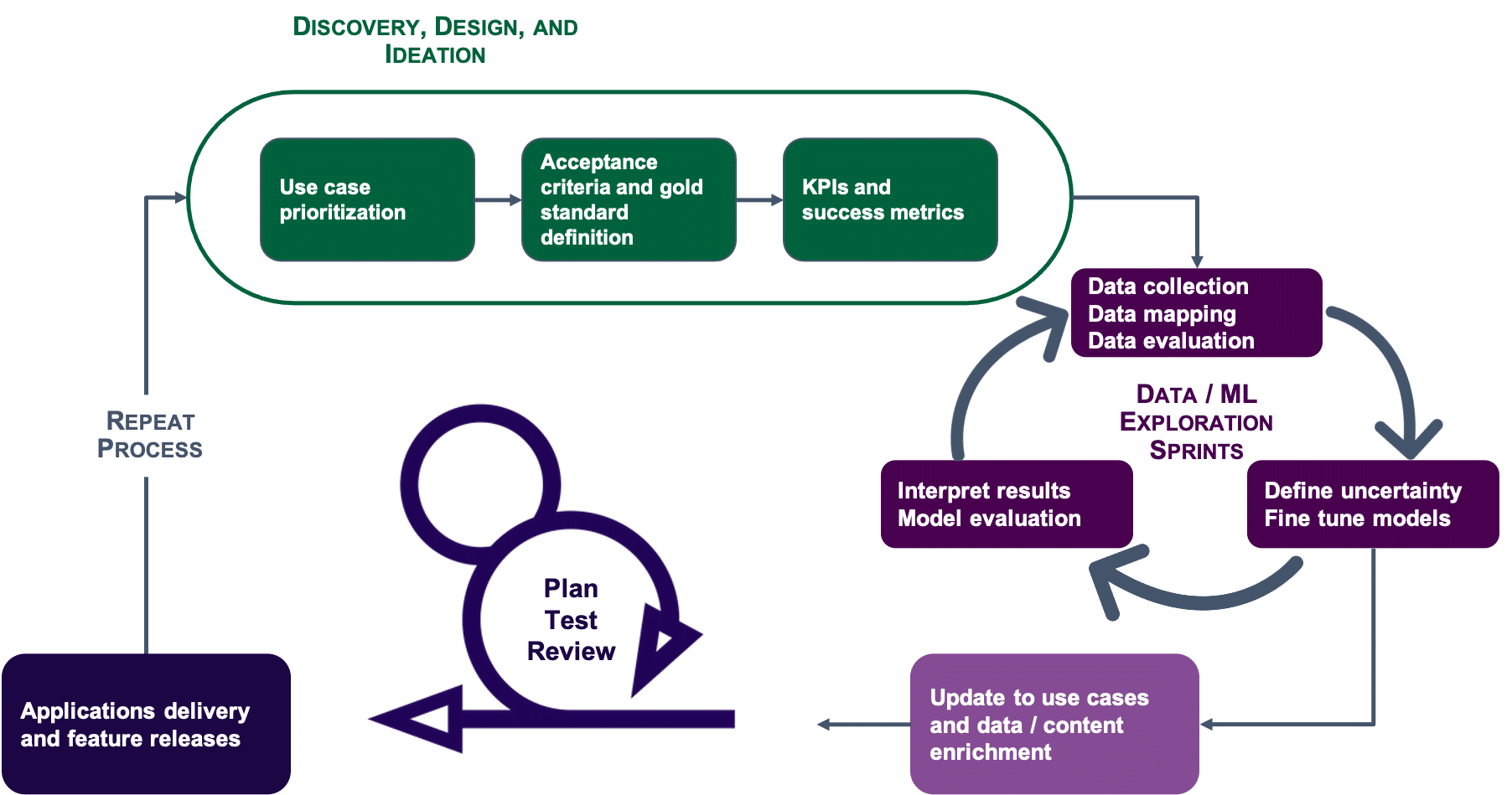 AI Project Delivery Iterations
AI Project Delivery Iterations
- Embed research or “spike” sprints to create room for understanding and data exploration: Unlike humans, machines need to go through diverse sets of data to understand the context within which it is being applied at your organization (a knowledge graph significantly helps in this process) and align it to your expected results. This process requires stages of understanding, analysis, and research to identify relevant data. Do your AI projects plan for this research?
- Embrace testing and quality assurance (QA) from the start: Testing in AI/ML is not limited to the model itself. Ensuring the data quality stays sufficient to serve use cases and having the right entry point checks in place to detect potential data collection errors is a foundational step before starting the model. Additionally the QA process in AI and ML projects should take into account the ability to test integration points as well as any peripheral systems and processes that serve as inputs or outputs to the model itself. As time goes by, having a proven integration and automation process to continue updating and training the model is another area that will require automation itself.
- Prepare for organizational impact: When it comes down to implementation, some projects are inherently too big. Imagine replacing legacy applications with AI technology and models, for instance. There needs to be supporting organization-wide processes in place to ensure your model and delivery is supported all the way throughout strategy, implementation, and adoption. There are more players that need to be involved in addition to the project team itself.
2. Know what is really being delivered
For machine learning and AI, the product is the algorithm, or the model, not necessarily the accuracy of the results. Meaning, if the model is right, with the right data, it will deliver the intended results. Otherwise, garbage in, garbage out. Understanding this dynamic is key when defining acceptance criteria and your minimum viable product. Additionally, leveraging UI/UX resources and wireframing sessions facilitates the explanation of what the AI tool really is and sets expectations around what it can help stakeholders achieve before they test the tool.
-
- AI scope is mostly driven by two factors, use cases and available data: Combining top-down discovery and ideation sessions with end-users and subject matter experts (SMEs) with bottom-up mapping and review of content, data, and systems is a technique we use to narrow down AI/ML opportunities to define the initial delivery requirements. As the project progresses, there will almost always be new developments, findings, and challenges that arise. The key to successful definition of what is really being delivered is building the required flexibility into iteration cycles and update loops for end-users and SMEs to review exploratory results from the data and ML workstream regularly and provide context and domain knowledge to refine the model based on available datasets.
- Plan for diverging stakeholder opinions: Machine learning models are better than a human at browsing through thousands of content items and finding recommendations that organizational SMEs may not have thought of. However, your current data may not necessarily capture the topics or the “aboutness” of how your data is used. Encouraging non-technical stakeholders to provide context by participating in the ideation and the acceptance criteria development process is key. You need SMEs to help create a rich semantic layer that captures key business facts and context. However, your stakeholders or SMEs may have their own tacit knowledge and memory of your organization’s content to say what’s good or bad when it comes to your project results. What if the machine uncovers better content for search results that everyone may have forgotten about? And remember, missing results are not necessarily bad because they can help identify the content or data your organization is currently missing.
- Defining KPIs or ROI for AI projects is an iterative process: It is important to create the ability to ensure the right solution is being developed and is effective. The definition of the use case, acceptance criteria, and gold standard typically serve as introductory benchmarks to determine how to measure impact of the solution and overall success and return. However, as more training data is added, the model is continually updated and can change significantly over time. Thus, it is important to understand that the initial KPIs will usually have assumptions that are validated and updated as the solutions are incrementally developed and tested. It is also critical to have baseline data in order to successfully compare outcomes with ML/AI and without. Because setting KPIs is a journey, it really boils down to planning for and setting up the right governance and monitoring processes to support continuous re-training of the model and measure impact frequently.
3. Plan for ancillary (potentially hidden) costs
This is one of the primary areas where AI projects encounter a reality check. If not planned for, these hidden costs can take many forms and cause significant delays or completely stall projects. The following items are some of the most common items to consider when planning to scale AI efforts:
- Size and quality of the right data: AI and ML models learn from lots of training data. The larger the dataset, the better the AI model and results will perform. This required size of data introduces challenges including the need to aggregate and merge data from multiple sources with different security constraints, diverse formats (structured, unstructured, video files, text, images, etc.). This affects where and how your data and AI projects teams spend most of their time i.e., preparing data for analysis as opposed to building models and developing results. One of the most helpful ways to make such datasets easier to manage is to enhance them with rich, descriptive metadata (see next item) and a data knowledge graph.
- Data preparation and labeling (taxonomies / metadata): Most organizations do not have labeled data readily available for effective execution of ML and AI projects. If not planned for or staffed properly, the majority of your resources will be spent in annotating or labeling training data. Because this step requires domain knowledge and the use of standards and best practices in knowledge organization systems, organizations will have to invest in formal and standardized semantic experts and hybrid automation in order to maintain quality and consistency data across sources.
- Licenses and tools: The most common misconceptions for Enterprise AI implementations and why many AI projects fail starts with the assumption that AI is a “Single Technology” solution. Organizations looking to “plug-and-play AI” or who want to experiment with a variety of open source tools need to reset their expectations and plan for the requirements and actual cost using these tools as costs can add up quickly. AI solutions range from data management and orchestration capabilities to employing a solution for metadata storage, and depending on the use case, the ability to push ML model results to upstream or downstream applications.
- Project team expertise (or lack thereof): Experienced data scientists are required to effectively handle most of the machine learning and AI projects, especially when it comes to defining the success criteria, final delivery, scale, and continuous improvement of the model. Overlooking this foundational need could result in even more costly outcomes, or wasted efforts after producing misleading results or results that aren’t actionable or insightful.
Closing
The approach to enable rapid delivery of AI and its adoption continue to evolve. However, the challenges with scale still remain attributed to many factors including selecting the right project management and delivery framework, acquiring the right solutions, instituting the foundational data management and governance practices, and finding, hiring, and retaining people with the right skill sets. And ultimately, enterprise leaders need to understand how AI and Machine Learning work and what AI really delivers for the organization. The good news is that if built with the right foundations, a given AI solution can be reusable for multiple use cases, connect diverse data sources, cross organizational silos, and continue to deliver on the hype.
How’s your organization tracking? Find out if your organization has the right foundations to take AI to production or email us to learn more about our experience and how we can help.