
Today, many organizational leaders are focused on AI readiness, and as the AI transformation is accelerating, so are the trends that define how businesses look for, store, secure, and leverage data and content.
The future of enterprise data management and architecture is evolving rapidly in some areas and returning to core principles in others. Based on our experience through our engagements across industries, diverse projects and client use cases, and our vendor partnerships, we continue to have the opportunity to observe and address the dynamic challenges organizations are facing in managing and getting value out of their data. These interactions, coupled with inputs from our advisory board, are helping us gain a good picture of the evolving landscape.
Drawing from these sources, I have identified the key trends in the data management and architecture space that we expect to see in 2025. Overall, these trends highlight how organizations are adapting to technological advancements while shifting towards a more holistic approach – focusing on people, processes, and standards – to maximize returns on their data investments.
1. Wider Adoption of a Business or Domain-Focused Data Strategy
The conventional approach to data management architecture often involved a monolithic architecture, with centralized data repositories and standardized reporting systems that served the entire organization. While this worked for basic reporting and operational needs, the last decade has proven that such a solution couldn’t keep pace with the complexities of modern businesses. In recent years, a more agile and dynamic approach has gained momentum (and adoption) – one that is putting the business first. This shift is driven by the growing need not only to manage vast and diverse data but also to address the persistent challenge of minimizing data duplication while making data actionable, relevant, and directly aligned with the needs of specific business users.
A Business or Domain-Focused data strategy approach emphasizes decentralized data ownership and federated governance across various business domains (e.g., customer service, HR, sales, operations) – where each domain or department owns “fit-for-purpose” tools and the data within. As a result, data is organized and managed by the business function it supports, rather than by data type or format.
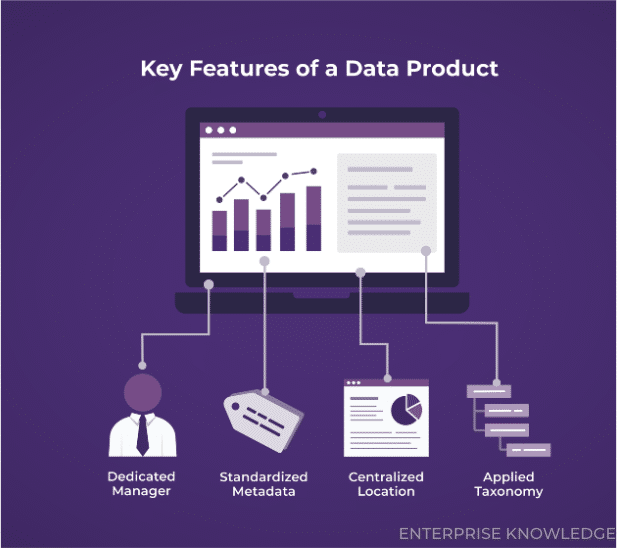
This has been an emerging trend for a couple of years and part of the data mesh architecture. It is now gaining traction through the wider adoption of business-aligned data products or data domains in support of business processes – where data products empower individual business units to standardize and contextualize their data and derive actionable insights without heavy reliance on central IT, data teams, or enterprise-wide platforms. Why is this happening now? We are seeing two key drivers fueling the growing adoption of this strategy:
- The shift in focus from the physical data to descriptive metadata, and the advancement in the corresponding solutions that enable this approach (such as a semantic layer or data fabric architectures that connect domain-specific data platforms without the need for data duplication or migration); and
- The rise of Artificial Intelligence (AI), specifically Named Entity Recognition (NER), Natural Language Processing (NLP), Large Language Models (LLMs), and Machine Learning (ML) – playing a pivotal role in augmenting organizational capabilities with automation.
As a result, we are starting to see the traditional method of relying on static reports and dashboards becoming obsolete. By integrating the federated capabilities and trends discussed below, we anticipate organizations moving beyond static reporting dashboards to the ability to “talk” to their data in a more dynamic and reliable way.
2. Semantic Layer Data Architecture
One of the key concepts that is significantly fueling the adoption of modern data stacks today is the “zero-copy” principle – building a data architecture that greatly reduces or eliminates the need to copy data from one system to another, thus allowing organizations to access and analyze data from multiple sources in real-time without duplicating it. This principle is changing how organizations manage and interact with their data.
In 2020, I first discussed Semantic Layer Architecture through a white paper I published called, What is a Semantic Architecture and How do I Build One?. In 2021, Gartner dubbed it “a data fabric/data mesh architecture and key to modernizing enterprise data management.” As the field continues to evolve, technical capabilities are advancing semantic solutions. A semantic layer in data architecture takes a metadata-first approach and is becoming an essential component of modern data architectures, enabling organizations to simplify data access, improve consistency, and enhance data governance.
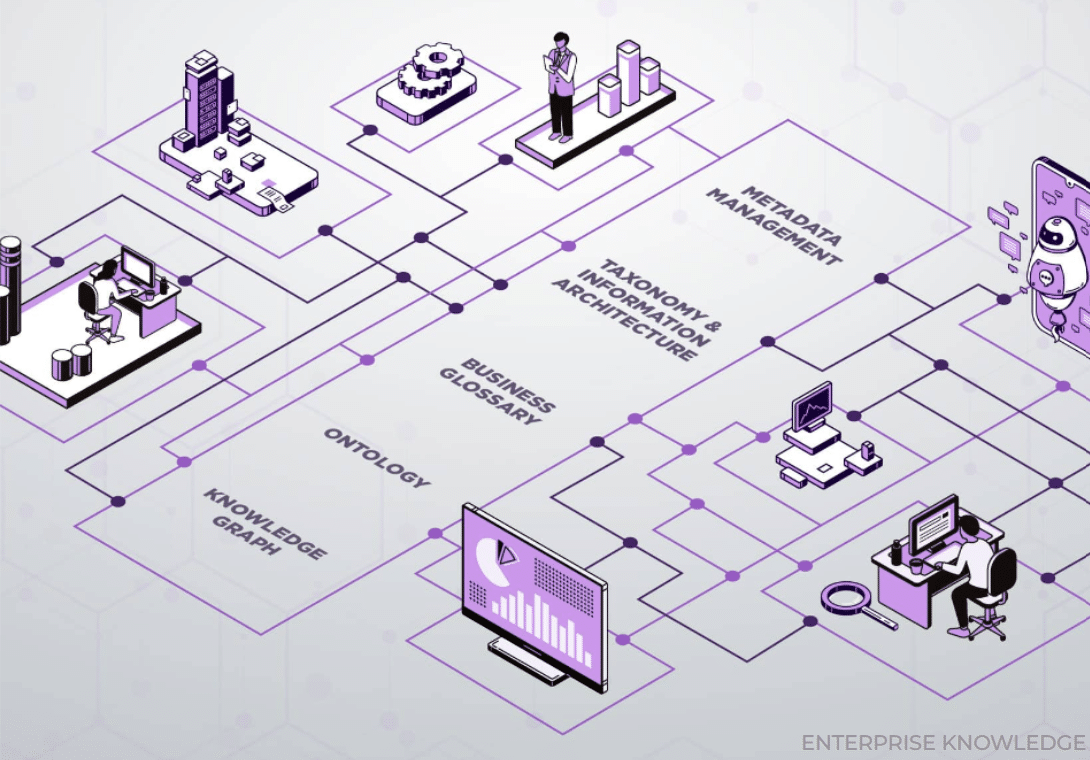
From an architect’s point of view, a semantic layer architecture adds significant value to modern data architecture and it is becoming a trend organizations are embracing – primarily because it provides the framework for addressing these traditional challenges for the data organization:
- Business alignment through standardized metadata by translating business context and relationships between raw data through metadata and ontology, making it ‘machine reliable’;
- Simplified data access for business users through shared vocabulary (taxonomy);
- Enhanced data connection and interoperability through a virtualized access and central source of “view” that connects data (through metadata) from various sources without requiring the physical movement of data;
- Improved data governance and security by enforcing the application of consistent business definitions, metrics, and data access rules to data; and
- The flexibility to future-proof data architecture by decoupling the complexities of data storage and presentation facilitates a zero-copy principle and ensures data remains where it is stored, without unnecessary duplication or replication. This helps organizations create a virtualized layer to address the challenges of working with diverse data from multiple sources while maintaining consistency and usability.
This trend reflects a broader shift from legacy application/system-centric architecture to a more data-centric approach where data doesn’t lose its meaning and context when taken out of a spreadsheet, a document, SQL table, or a data platform – helping organizations unlock the true potential of their knowledge and data.
3. Consolidation & Rebundling of Data Platforms
The enterprise data technology landscape has been going after the “modern data stack” strategy, characterized by a best-of-breed approach, where organizations adopt specialized tools from various vendors to fulfill different needs – be it data storage, analytics, data cataloging and discovery, or AI. However, with the growing complexity of managing multiple platforms and tighter budgets, organizations are facing mounting pressures to optimize.
Much akin to the retro experience that we’re seeing within the TV streaming industry, the landscape of data technologies is undergoing a significant shift – one of rebundling. This change is primarily driven by the need to simplify data management solutions in order to handle increasing organizational data complexity, optimize the costs associated with data storage and IT infrastructure across multiple vendors, and enhance the ability to experiment with and extract value from AI.
As a result, we are seeing the pace of technology bundling and mergers and acquisitions accelerating as large, well-established data platforms are acquiring smaller, specialized vendors and offering integrated, end-to-end solutions that aim to simplify data management. One good, well-publicized example of this is Salesforce’s recent bundling with and acquisition of various vendors to unveil the Unlimited Edition+ bundle, which provides access across Slack, Tableau, Sales Cloud, Service Cloud, Einstein AI, Data Cloud, and more, all in a single offering. In a recent article, my colleague further discussed the ongoing consolidation in the semantic data software industry, highlighting how the sector is increasingly recognizing the importance of semantics and how well-funded software companies are acquiring many independent vendors in this space to provide more comprehensive semantic layer solutions to their customers.
In 2025, we expect more acquisitions to be on the horizon. For CIOs and CDAOs looking to take advantage of this trend, there are important factors to consider.
Limitations and Known Challenges:
- Complexity in data migration: Migrating data from multiple platforms into a unified one is a resource-intensive process. Such transitions typically introduce disruptions to business operations, leading to downtime or performance issues during the shift.
- Data interoperability: The ability of different data systems, platforms, applications, and organizations to exchange, interpret, and use data seamlessly across various environments is paramount in today’s data landscape. This interoperability ensures data flows without losing its meaning, whether within an organization (e.g., between departments and various systems) or externally (e.g., regulatory reporting). Single-vendor technology bundles are often optimized for internal use, and they can limit data exchange with external systems or other vendors’ tools. This creates challenges and costs when trying to integrate non-vendor systems or migrate to new platforms. To mitigate these risks, it’s important for organizations to adopt solutions based on standardized data formats and protocols, invest in middleware and APIs for integration, and leverage cloud-based systems that support open standards and external system compatibility.
- Potential vendor lock: By committing to a single platform, organizations often become overly dependent on a specific vendor’s technology for all their data needs. This limits the data organization’s flexibility, especially when new tools or platforms are required, forcing the use of a proprietary solution that may no longer meet your evolving business needs. Relying on one platform also restricts data access and complicates integration with other systems, hindering the ability to gain holistic insights across your organizational data assets.
Benefit Areas:
- Better control over security and compliance: As businesses integrate AI and other advanced technologies into their data stacks, having a consolidated security framework is particularly top of mind. Facilitating this simplification through a unified platform reduces the risks associated with managing security across multiple platforms and helps ensure better compliance with regulatory data security requirements.
- Streamlined access and entitlement management: Consolidating the management of organizational access to data, roles, and permissions allows administrators to unify user access to data and content across applications within a suite – typically from a central dashboard, making it easier to enforce consistent access policies across all connected applications. This streamlines better management to prevent unauthorized access to critical data. It helps ensure that only authorized users have the appropriate access to diverse types of data, including AI models, algorithms, and media, strengthening the organization’s overall security posture.
- Simplified vendor management: Using a single vendor for a bundled suite reduces the administrative complexity of managing multiple vendors, which sometimes involves different support processes, protocols, and system compatibility issues. A unified data platform provides a more streamlined approach to handling data across systems and a single point of contact for support or troubleshooting.
When properly managed, bundling has its benefits; the focus should be on finding the balance, ensuring that data interoperability concerns are addressed while still leveraging the advantages of bundled solutions. Depending on the priority for your organization, this trend will be beneficial to watch (and adopt) for your streamlined data landscape and architecture.
4. Refocused Investments in Complementary AI Technologies (Beyond LLMs)
While LLMs have garnered significant attention in conversational AI and content generation, organizations are now recognizing that their data management challenges require more specialized, nuanced, and somewhat ‘traditional’ AI tools that address the gaps in explainability, precision, and the ability to align LLMs with organizational context and business rules.
Despite the draw to AI’s potential, many organizations prioritize the reliability and trustworthiness of traditional knowledge assets. They also want to integrate human intelligence, ensuring that an organization’s collective knowledge – including people’s experience and expertise – is fully captured. We refer to this as Knowledge Intelligence (KI) rather than just AI, to indicate the integration of tacit knowledge and human intelligence with AI, thereby capturing the deepest and most valuable information within an organization.
As such, organizations have started reinvesting in Natural Language Processing (NLP), Named Entity Recognition (NER), and Machine Learning (ML) capabilities, realizing that these complementary AI tools are just as essential in tackling their complex enterprise data and knowledge management (KM) use cases. Specifically, we are seeing this trend reemerging to embrace the advancements in AI capabilities for enabling the following key priorities for the enterprise.
- Expert Knowledge Capture & Transfer: Programmatically encoding expert knowledge and business context in structured data & AI;
- Knowledge Extraction: Federated connection and aggregation of organizational knowledge assets (unstructured, structured, and semi-structured sources) for knowledge extraction; and
- Business Context Embedding: Providing standardized meaning and context to data and all knowledge assets in a machine-readable format.
We see this renewed focus in holistic AI technologies as more than just a passing shift; it is marking a pivotal trend in the world of enterprise data management as a strategic move toward more reliable, intelligent, and efficient information and data management.
For organizations looking to enhance their ability to extract value from experts and diverse data and content assets, the trend in comprehensive AI capabilities facilitates this integration and ensures that AI can operate not just as a tool, but as an intelligent organizational partner that understands the unique nuances of an organization – ultimately delivering knowledge and intelligence to the data organization.
5. A Unified Approach to Data and Content Management: Data & Analytics Teams Meet Unstructured Content & Knowledge Management
One of the most subtle yet significant changes we have been seeing over the last 2-3 years is the blending of traditionally siloed data management functions. In particular, the boundary between data and knowledge management teams is increasingly dissolving, with data and analytics professionals now addressing challenges that were once primarily the domain of KM. This shift is largely due to the growing recognition that organizations need a more cohesive approach to handling both structured and unstructured content.
Just a few years back, data management was largely a function of structured data, confined to databases and well-defined formats and handled by data engineers, data analysts, and data governance officers. Knowledge and content management, on the other hand, dealt primarily with unstructured content such as documents, emails, and multimedia, managed by different teams including knowledge officers and document management specialists.
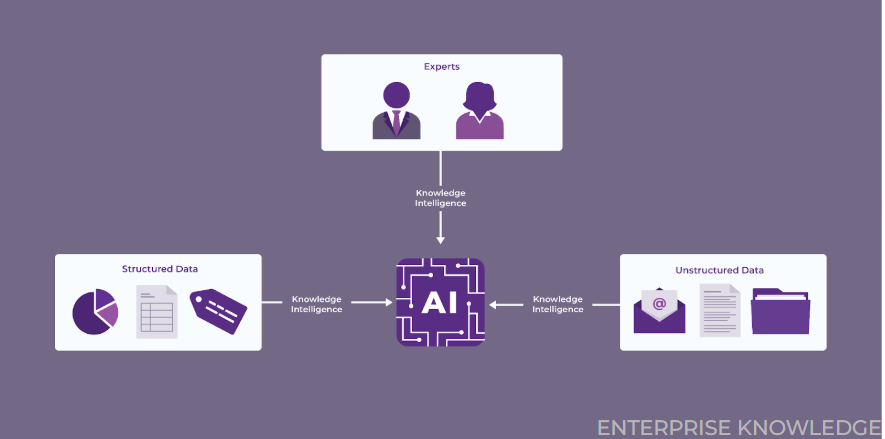
However, in 2025, as organizations continue to strive for a more flexible approach to benefit from their overall organizational knowledge assets, we are witnessing a convergence where data teams are now actively engaged in managing unstructured knowledge. With advancements in GenAI, machine learning, NER, and NLP technologies, data and analytics teams are now expected to not only manage and analyze structured data but also tackle the complexities of unstructured content – ranging from documents, emails, text, and social media posts to contracts and video files.
By bridging the gap between data teams and business-oriented KM teams, organizations are able to better connect technical initiatives to actual use cases for employees, customers, and their stakeholders. For example, we are seeing a successful adoption of this trend with the data & analytics teams at a large global retailer. We are supporting their content and information management teams’ ability to enable the data teams with a knowledge and semantic framework to aggregate and connect traditionally siloed data and unstructured content. The KM team is doing this by providing knowledge models and semantic standards such as metadata, business glossaries, and taxonomy/ontology (as part of a semantic layer architecture) – explicitly providing business context for data, categorizing and labeling unstructured content, and providing the business logic and context for data used in their AI algorithms.
In 2025, we expect to see this trend to become more common for many organizations looking to enable cross-functional collaboration, with traditional data and IM offices starting to converge and professionals from diverse backgrounds working together to manage both structured and unstructured data.
6. Shift in Organizational Roles: From Governance to Enablement
This trend reflects how the previously mentioned shifts are becoming a reality within enterprises. As organizations embrace a more integrated approach to connecting overall organizational knowledge assets, the roles within the organization are also shifting. Traditionally, data governance teams, officers, and compliance specialists have been the gatekeepers of data quality, privacy, and security. While these roles remain crucial, the focus is increasingly shifting toward enablement rather than control.
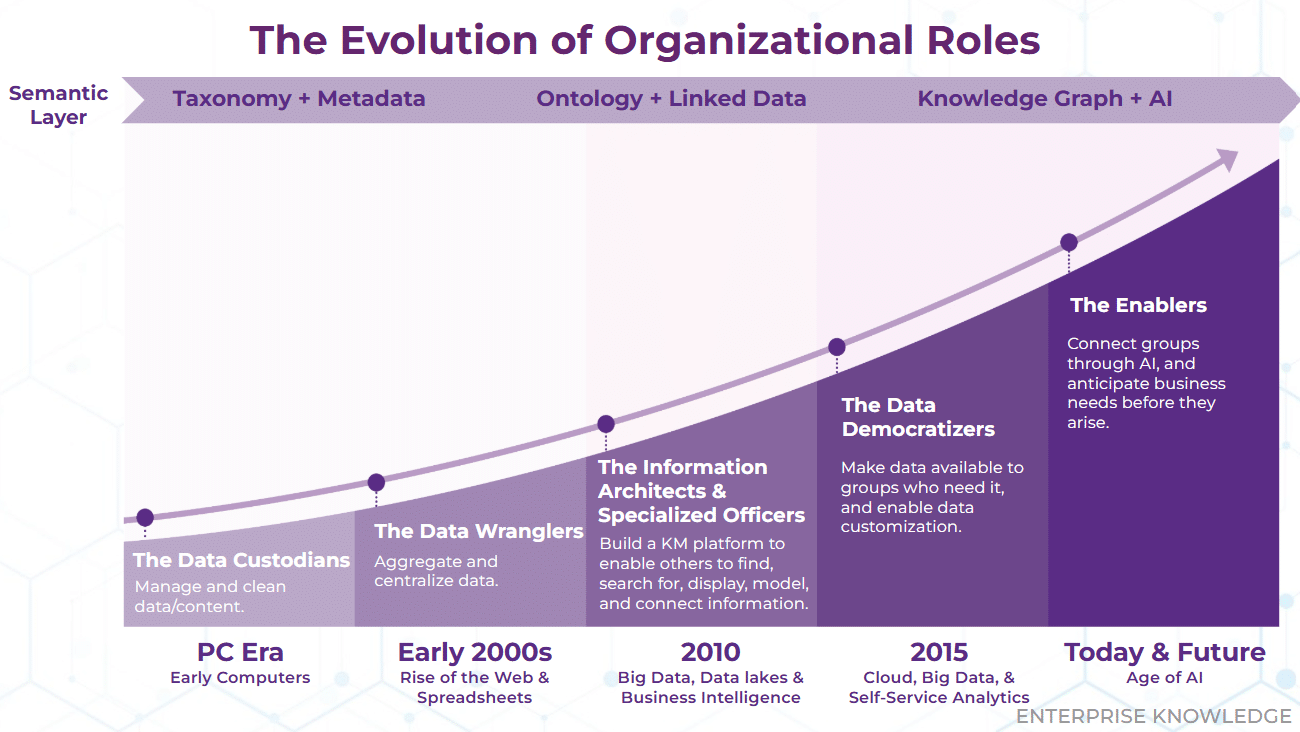
Additionally, knowledge managers are steadily growing beyond their traditional role of providing the framework for sharing, applying, and managing the knowledge and information of an organization. They are now also serving as the providers of business context to data teams and advancements in Artificial Intelligence (AI). This heightened visibility for KM has pushed the industry to identify more optimized ways to organize teams and measure and convey their value to organizational leaders. On top of that, AI has been fueling the democratization of knowledge and data, leading to a growing recognition of the interdependence between data, information, and knowledge management teams.
This is what is driving the evolution of roles within KM and data from governance and control to enablement. These roles are moving away from strict oversight and regulation and towards fostering collaboration, access, and self-sufficiency across the organization. Data officers and KM teams will continue to play a critical role in setting the standards for data quality, privacy, and security. However, as their roles shift from governance to enablement, these teams will increasingly focus on establishing frameworks that support transparency, collaboration, and compliance across a more data-centric enterprise – availing self-service analytics tools that allow even non-technical staff to analyze data and generate insights independently.
As we enter 2025, the landscape of enterprise data management is being reshaped by shifts in strategy, architecture, platform focus, and the convergence of data and knowledge management teams. These changes reflect how organizations are moving from siloed approaches to a more connected, enablement-driven model. By leveraging a combination of AI-powered tools, self-service capabilities, and evolving governance practices, organizations are unlocking the full value of their data and knowledge assets. This transformation will enable faster, more informed decision-making, helping companies stay ahead in an increasingly competitive and rapidly evolving business environment.
How do these trends translate to your specific data organization and landscape? Is your organization embracing these trends? Read more or contact us to learn more and grow your data organization.