
In January, the federal government passed a new law to improve data management at federal agencies, H.R. 4174, the “Foundations for Evidence-based Policymaking Act of 2018”. The law includes the Open, Public, Electronic, and Necessary Government Data Act, or the OPEN Government Data Act. As its name implies, this law requires, to the fullest extent possible, that federal agencies ensure that their data assets are machine-readable and available to the public.
This law marks a big step forward for knowledge and information management in the federal government because it clearly prioritizes making data easier to work with and more accessible to both internal and external data users. While many organizations are working to organize and capitalize upon their mountains of data, federal government agencies, in particular, possess may obstacles that hinder their ability to transition and modernize their current data management processes so that their data and information is open and machine-readable.
As experts in data and information management, Enterprise Knowledge assists organizations, both public and private, in achieving the goal of having more open, accessible, machine-readable data. In this whitepaper, we will show how achieving this goal is not only beneficial for the federal government, but why every organization should be striving for increased integration and enhanced structuring of their data resources to enable powerful and exciting use cases that make an organization more data-driven.
Understanding your Current State
The first step in structuring an organization’s data resources is to inventory what data is currently under the management of the organization. Data inventories are challenging due to the large volume of data that organizations generate and maintain across different functions. Some data, especially tabular data and other records, will already be stored in a structured format, such as through the use of relational databases. Other data will exist in an unstructured format, such as in PDFs, intranet web pages, or Microsoft Office files that are not stored in specific databases or distributed file systems. The key with this inventory step is noting where the data is stored, what format it is in, and how it can be accessed across various functions.
However, no data inventory is complete without carefully noting the purpose or value of each data resource. In order to put all these data resources into their proper context within the key functions or value streams of the business, it is important to map the business processes that different functions within the organization are using to acquire, manipulate, and, ultimately, share this data. Understanding what data exists, and to what end, will provide the foundation for developing a management strategy that effectively integrates the different data sources in a way that has the greatest impact on how the business uses and reuses data.
Modeling and Integrating Data Resources using an Ontology
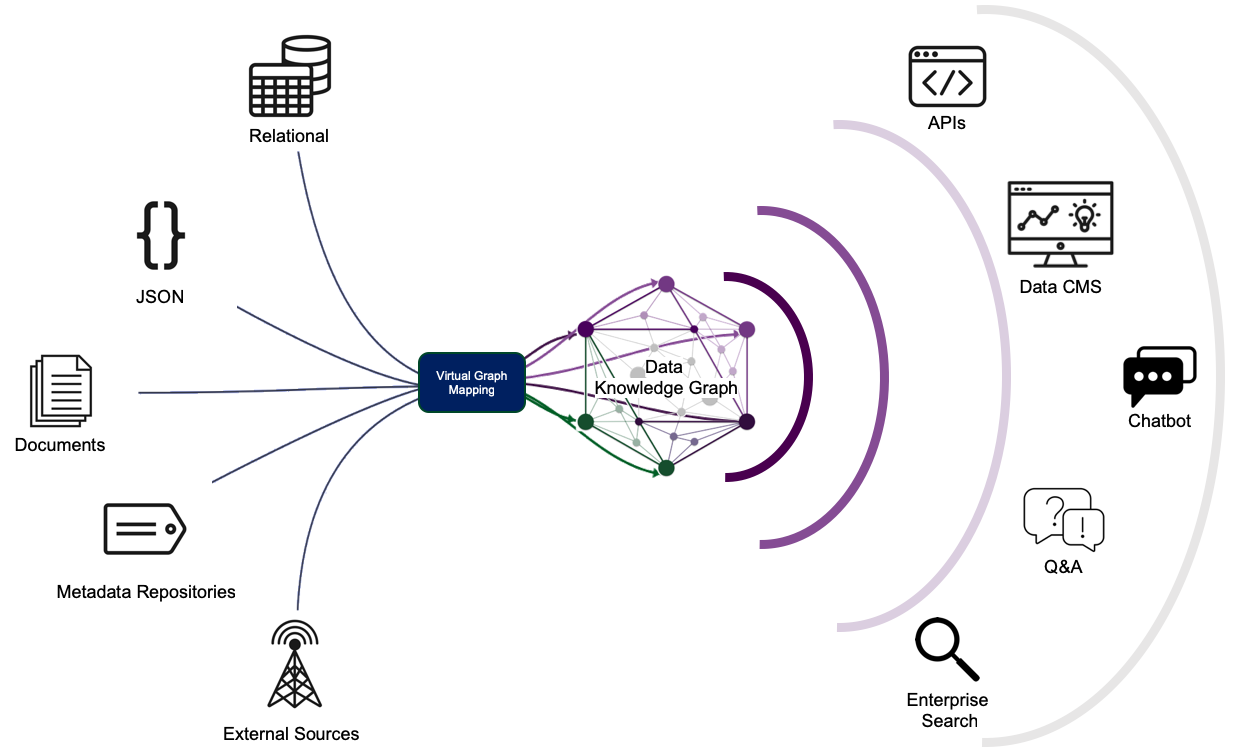
The initial mapping of data resources that occurs in the inventory phase serves as the foundation for a metadata model, or ontology, that will work to unify the data silos across the organization. We find that constructing a data knowledge graph through the use of semantic modeling with the most effective way to represent contextual, relational, and descriptive information. This information then helps users understand what data is available and what data is relevant to their needs.
The model, when implemented in a graph database, serves as an integration layer for all data resources, as well as a technical bridge that allows for Data SMEs, business users, and organization software applications to access data from different silos in a single location. Using enterprise graph database features, such as virtualization, means that data does not have to be copied or modified from its original source. This reduces the maintenance requirements that are typically needed for immediate integration of a variety of different data resources, so that one only needs to update the mappings between the ontology and the data sources up to date.
As an example of how an ontology can be designed to make relevant data more accessible, see the following discussion of a data knowledge graph that makes enhancing and organizing data for data scientists and non-technical users much easier.
Unleashing the Power of Structured and Integrated Data
Having your organization’s data resources connected and structured in a data knowledge graph not only facilitates the management and inventory of resources, but it also allows the data to easily be used in a variety of downstream applications since the data is now structured in a machine-readable format. There are many possibilities to consider once all data resources have been integrated into a single unifying semantic model. Here are just some of the exciting use cases an organization can explore:
I. Structured Data Access by Organization Applications
The data in the knowledge graph can be queried and accessed via an Application Programming Interface (API) that uses the data to enhance search, provide descriptive information, and otherwise surface both an agency’s data resources and key contextual metadata in other tools and systems. Also, this data can easily be translated into common interchange formats like CSV and JSON. Want to share your data to the public? Such structured data can even be formatted to enhance Google search results for your organization.
II. Data Content Management Systems
The information in the knowledge graph is ready-made to be surfaced on content management user-interfaces where public and internal users alike can interact, explore, and access the data quickly and easily. By tapping into the contextual information stored in the knowledge graph, users can easily interpret what data is available and how it can be used. The data can feed commercial CMS platforms like SharePoint and Drupal, or be used to make custom interfaces that tailor the CMS design to data-specific use cases.
III. Natural Language Processing
Possibly the most exciting use case for a data knowledge graph is that it allows end users to find and query data using queries submitted as everyday English questions. Combining Natural Language Processing with the knowledge graph enables chatbots, enterprise search, and other question and answer systems to interpret what a user is asking for and then surface the answers and relevant data on demand.
Data and Organizational Alignment for the Future
No data integration and structuring effort is perfect from the start. It will require a thoughtful and effective organizational design that is supported by relevant roles and responsibilities in order to ensure that resources are maintained and governed so that the organization continues to transition towards open, accessible, and machine-readable data.
At EK, we partner with organizations to develop roadmaps that enable the divisions and job functions of a data management organization to be as effective as possible for managing the data itself. These roadmaps ensure that data is annotated and organized using a robust metadata model and that data resources are shared through websites, software, APIs, or other structured data services. Ultimately, a roadmap will make the biggest impact if it is centered around delivering the greatest value to end users. By integrating and organizing data resources in a methodical way, we can enable an organization’s data dependent processes to receive the largest benefits.
Enterprise Knowledge Is Ready for Open and Accessible Data
As a full-service knowledge and information management consultancy, Enterprise Knowledge and our data experts are uniquely suited to help both government agencies and private organizations become more data-driven by making their data resources better organized, structured, and more accessible to technical and non-technical users. If you are seeking to make your data more organized, open, and machine-processable in the spirit of H.R. 4174, or if these challenges are otherwise relevant to your business, learn more on how to get started or contact us directly. We are happy to partner with you throughout the entire process, from strategy and design to the implementation of the technology solution(s) to improve the management of your data.