
In today’s rapidly growing and evolving data environment, it is increasingly difficult for organizations to get maximal value from the full breadth of their data. As more data is produced faster by more sources, it is difficult for analysts, data scientists, and other consumers to be aware of and effectively use data being produced across organizational divisions and domain areas. Impaired discovery and use of data can lead to the direct costs of duplicated effort and wasted time, as well as the opportunity costs of unrealized data-driven insights.
The concept of data fabric is increasingly recognized as a key solution to the growing challenges of the modern data ecosystem, utilizing an enterprise-wide data architecture to facilitate discovery and use across the organization. Supporting your data fabric with an ontology–a graph-based semantic model that describes your organization’s data using standardized classes and concepts–amplifies the benefits of the data fabric, allowing your organization to:
- Discover and operationalize connections among distributed data;
- Facilitate the integration of data across sources and use cases; and
- Implement more robust data management and governance.
At EK we have had repeated success drawing on our experience developing ontologies and implementing semantic architectures to provide data fabric solutions to our clients. These successes have demonstrated tangible ways in which an enterprise ontology empowers a data fabric and magnifies its benefits, and have allowed us to identify concrete steps an organization can take toward designing, piloting, and scaling its own ontology-powered data fabric architecture.
What is a Data Fabric?
Data fabric is a logical data architecture that connects data assets across an organization and enriches them with standardized semantic metadata. The core of the data fabric is an abstraction layer that uses data virtualization to bring together information about data sources in disparate formats, systems, and locations while applying standardized processes for data governance, privacy, and security. By connecting data as if it were housed together, the data fabric makes it findable and usable without the overhead cost of actually moving the data into a single repository, which could require substantial intermediary processing and the maintenance of redundant infrastructure.
A data fabric can also include components that use knowledge inference, machine learning, or other AI systems to automate integration, orchestration, and metadata management across the systems touched by the data fabric.
What is an ontology?
An ontology is a semantic model that defines the concepts in a particular domain area, their attributes, and the relationships between them, encoding them in a graph format that is both machine- and human-readable. Most of the time, an ontology is a generalized model, describing the kinds of entities and relationships that exist in a domain rather than describing specific entities in the domain. For example, an e-commerce business might model the domain area surrounding its fulfillment operations as an ontology with entities such as Customer, Item, and Order; attributes such as Name, Phone Number, Quantity, and Product ID; and relationships such as Places and Contains:
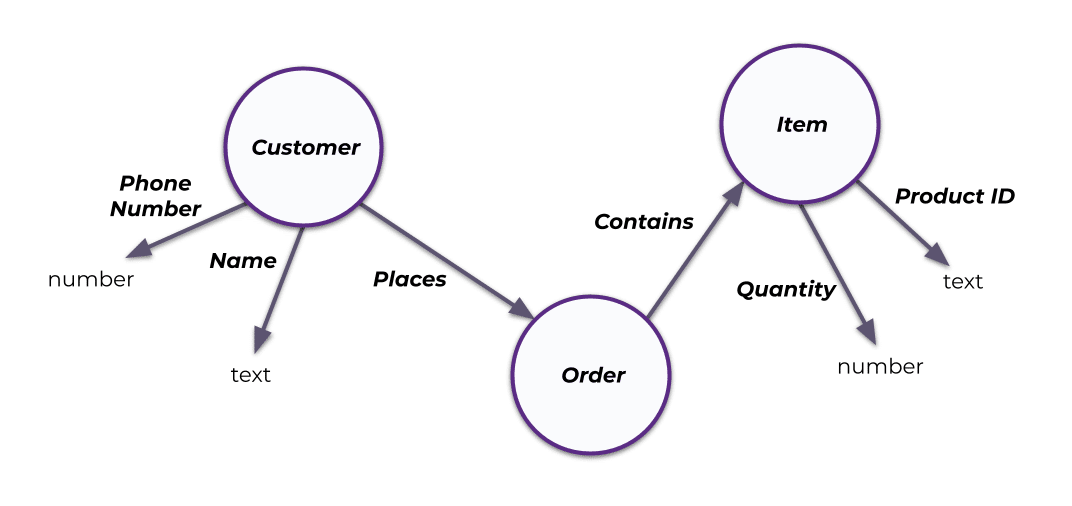
This simple ontology describes the entities involved in a business’s fulfillment operations processes (customers, orders, and items), their attributes (phone numbers, names, quantities, and product IDs), and the relationships between them (a customer places an order, an order contains an item).
In addition to providing a model that bakes in the meaning of data elements, ontologies can also be used to support many advanced AI technologies, including knowledge graphs and recommendation engines.
How Does an Enterprise Ontology Support a Data Fabric?
Developing an enterprise ontology to power semantic metadata is central to implementing an effective data fabric. The ontology provides the data fabric with an interoperable schema to standardize, enrich, and reconcile source data, giving users and applications a unified and reliable view of data across disparate data sources.
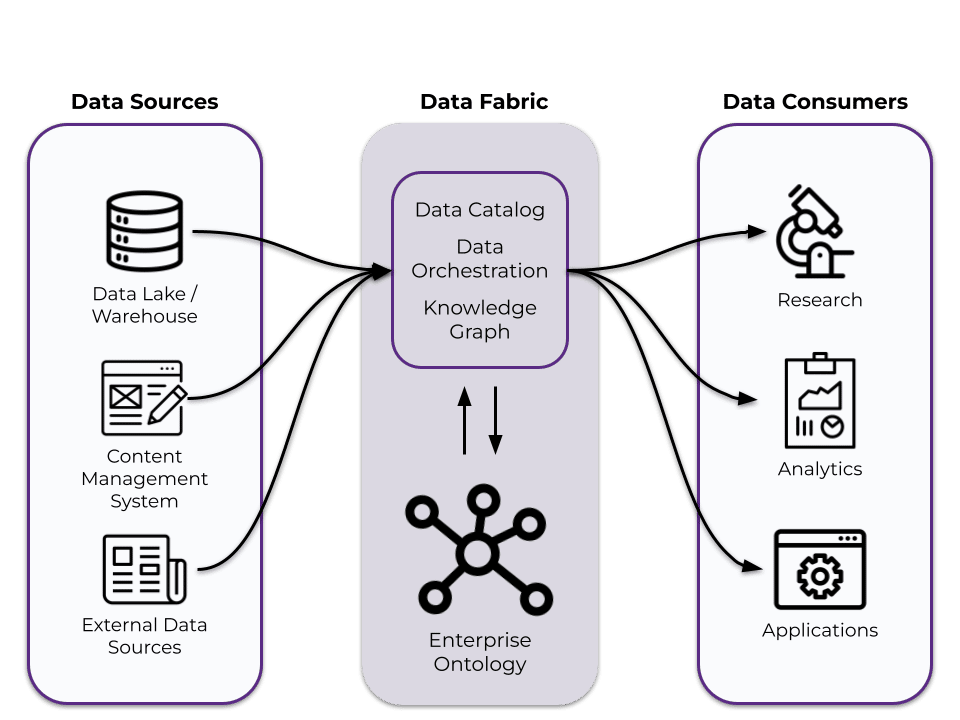
The enterprise ontology serves machine-readable meaning and business logic to the other systems of the data fabric, allowing the fabric to integrate data sources and make them available to data consumers.
Discover and Operationalize Connections
By providing an interoperable, system-agnostic semantic foundation, an enterprise ontology enables you to discover and operationalize connections among data assets. Unlike traditional relational and NoSQL data schemas, an ontology explicitly embeds the meaning of data concepts and the relationships that connect them within the data model itself. This means that data producers and consumers can reliably identify data assets across the organization that are using the same data elements as well as identify trustable connections to other data assets, even if all of the data involved uses divergent terminology.
For example, a data fabric using the sample customer ontology above would be able to automatically connect two datasets with differently named columns mapping to Phone Number, allowing analysts to confidently join tables on those columns and helping to surface these related datasets to data scientists. These machine-readable connections can also power recommendation engines and other advanced AI integrations that help you make the most of your organization’s data.
Facilitate Data Integration
An ontology’s data model is also highly flexible and extensible, which allows it to act as a system-agnostic conceptual model for the organization’s data ecosystem, facilitating the integration of data from diverse sources and use cases. As new data is created, ingested, and unearthed, new classes and relationships can be added to the ontology as necessary to describe the new data without requiring revision to previously modeled concepts. Because the ontology model is decoupled from the physical implementations of the data assets, all data in the organization can be equally represented by the ontology. This means any new data introduced into the organization’s ecosystem can be integrated with the data fabric, regardless of its schema or source systems.
If our hypothetical e-commerce merchant began building or acquiring datasets with new fields such as customer email addresses, or even introduced entirely new domains such as supply chain management, the ontology could be readily extended so the data fabric could continue to support all data usage in the business without an expensive architectural overhaul.
Enable Granular Data Management
Just as an ontology embeds human- and machine-readable meaning into the data model itself, it can also embed additional information about the data, including granular data management metadata about individual concepts. For example, the ontology might indicate that a phone number field is personally identifiable information (PII) so the data fabric would know to subject any dataset containing a phone number to stricter controls on access and use. Being able to operationalize security, privacy, and governance information at the data field level allows for extremely robust governance and can be used to enable enterprise-wide federation and data democratization while minimizing data privacy and security risks.
How Do You Get There?
A data fabric is a powerful architectural tool for managing and utilizing the sprawl of data that occurs at modern organizations, but to realize its full potential it must be built on the semantic foundation of an enterprise ontology. Using an ontology will enable the data fabric to discover and operationalize connections among data, to integrate disparate and distributed data, and to enact robust and granular data governance.
At EK, we take a use case-driven, iterative approach to design and implementation, starting with a well-defined proof of concept that can rapidly demonstrate value and then scaling across the organization. These are some sample steps to achieve your first data fabric powered by an enterprise ontology:
- Select a specific use case or domain to prioritize as a proof of concept;
- Design and evaluate an enterprise architecture;
- Inventory source data in the prioritized use case or domain;
- Model entities, attributes, and relationships found in the source data to establish the ontology model;
- Map the source data to the ontology to support the prototype data fabric; and
- Create a plan to scale the proof of concept to the entire organization.
While data fabric is one of the most exciting new terms for enterprise data to emerge over the past few years and adoption of this architecture is on the rise, Enterprise Knowledge has a deep history of successfully empowering organizations with semantic data architectures. We have drawn on this experience and expertise to successfully implement data fabrics for organizations in diverse industries and sectors, including semantic layers to support scientific research, content recommenders for disparate digital learning materials, and customer-360 and enterprise-360 views of integrated data.
Are you ready to fully unlock the power of your organization’s data? Want to know more about data fabrics, ontologies, and knowledge graphs? Contact us here to take your first step toward a next-generation enterprise data ecosystem.