
Our CEO, Zach Wahl, recently noted in his annual KM trends blog for 2025 that Knowledge Management (KM) and Artificial Intelligence (AI) are really two sides of the same coin, detailing this idea further in his seminal blog introducing the term Knowledge Intelligence (KI). In particular, KM can play a big role in structuring unstructured content and make it more suitable for use by enterprise AI. Injecting knowledge into unstructured data using taxonomies, ontologies, and knowledge graphs will be the focus of this blog, which is Part 2 in the Knowledge Intelligence Architecture Series. I will also describe our typical approaches and experience with mining knowledge out of unstructured content to develop taxonomies and knowledge graphs. As a refresher, you can review Part 1 of this series where I introduced the high-level technical components needed for implementing any KI architecture.
Role of NLP in Structuring Unstructured Content
Natural language processing (NLP) is a machine learning technique that gives computers the ability to interpret and understand human language. According to most industry estimates, 80-90% of an organization’s data is considered to be unstructured, most of which originates from emails, chat messages, documents, presentations, videos, and social media posts. Extracting meaningful insights from such unstructured content can be difficult due to its lack of predefined structure. This is where NLP techniques can be immensely useful. NLP works through the differences in dialects, metaphors, variations in sentence structure, grammatical irregularities, and usage exceptions that are common in such data and structures it effectively. A common NLP task for analyzing unstructured content and making it machine readable is content classification. This process categorizes text into predefined classes by identifying keywords that indicate the topic of the text.
Over the past decade, we have employed numerous NLP techniques across our typical knowledge and data management engagements, focusing on unstructured content classification. With the emergence of Large Language Models (LLMs), traditional NLP tasks can now be executed with higher precision and recall while requiring significantly less development effort. The section below presents a comprehensive, though not exhaustive, range of NLP strategies incorporating both traditional ML and cutting-edge LLMs along with inherent pattern recognition capabilities in vendor platforms for content understanding and classification. Specifically, it describes for each approach the underlying architecture, illustrating the steps involved in adding context to unstructured content using semantic data assets and some relevant case studies.
1. Transfer Learning for Content Classification
Transfer learning is a method in which a deep learning model trained on a large dataset is applied to a similar task using a different dataset. Starting with a pre-trained model that has already learned linguistic patterns and structures from a significant volume of data eliminates the need for extensive labeled datasets and reduces training time. Since the release of the BERT (Bidirectional Encoder Representations from Transformers) language model in 2018, we have extensively utilized transfer learning to analyze and categorize unstructured content using a predefined classification scheme for our clients. In fact, it is often our preferred approach for entity extraction when instantiating a knowledge graph as it supports a scalable and maintainable solution for the enterprise.
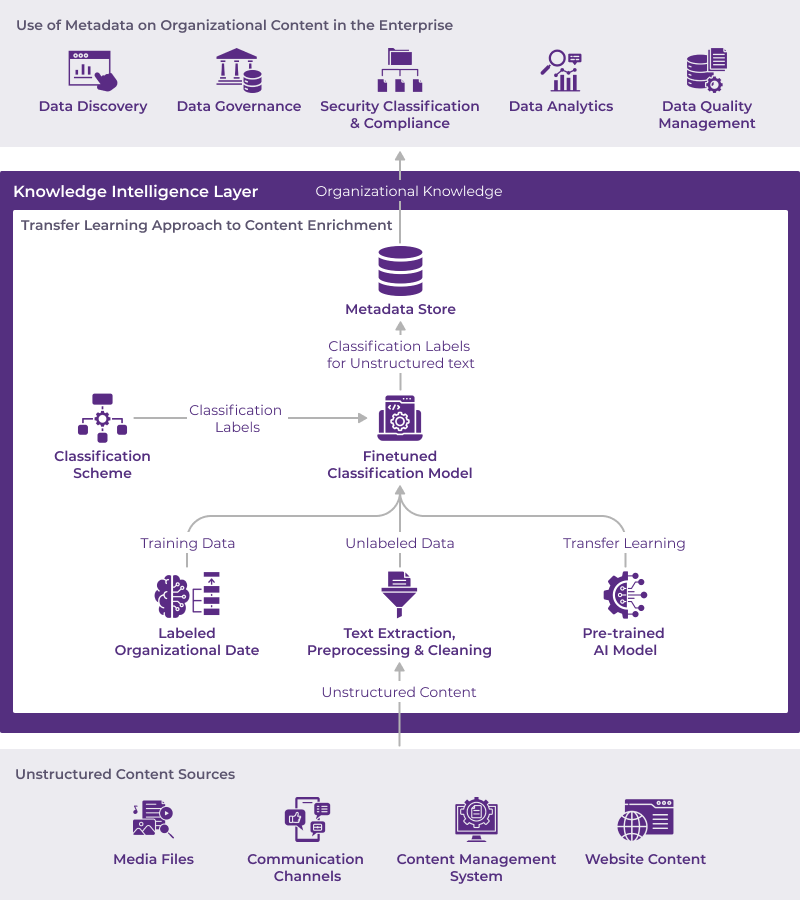
Enterprise AI Architecture: Transfer Learning for Content Classification
As illustrated in the figure above, unstructured data in the enterprise can originate from many different systems beyond the conventional ones such as content management systems and websites. Such sources can include communication channels such as emails, instant messaging systems, and social media platforms, as well as digital asset management platforms to centrally store, organize, manage, and distribute media files such as images, video, and audio files within the organization. As machine learning can only work with textual data, depending on the type of content, the first step in implementing transfer learning is to employ appropriate text extraction and transformation algorithms to make the data suitable for use. Next, domain SMEs label a small chunk of the clean data to fine-tune the selected pretrained AI model with a predefined classification scheme (also provided by the domain SMEs). Post-training, the fine-tuned model is deployed to production and is available for content classification. At this stage, organizations can run their content through the operationalized transfer learning based content classification pipeline and store it in a centralized metadata repository such as a data catalog or even a simple object store that, in turn, can be used to power multiple enterprise use cases from data discovery to data analytics.
Transfer learning is one of the popular techniques we employ for entity extraction from unstructured content in our typical knowledge graph accelerator engagements. It is one of our criteria when evaluating data fabric solution vendors – especially in the case of a multinational pharmaceutical company. This is because transfer learning can easily grow with inputs from domain SMEs (with respect to data labelling and classification scheme definition) to tailor the machine prediction to the organizational needs and sustain the classification effort without extensive machine learning training. However, this does not mean that machine learning (ML) expertise is not required. For organizations that lack the internal skills to build and maintain custom ML pipelines, the following content classification approaches may be useful.
2. Taxonomy Manager-Driven Content Classification
Most modern Taxonomy Ontology Management Systems (TOMS) include a classification engine that supports automatic text classification based on a defined taxonomy. In our experience, organizations with access to a TOMS but without dedicated AI teams to develop and maintain custom ML models prefer using built-in classification capabilities of TOMS to categorize and structure their unstructured content.
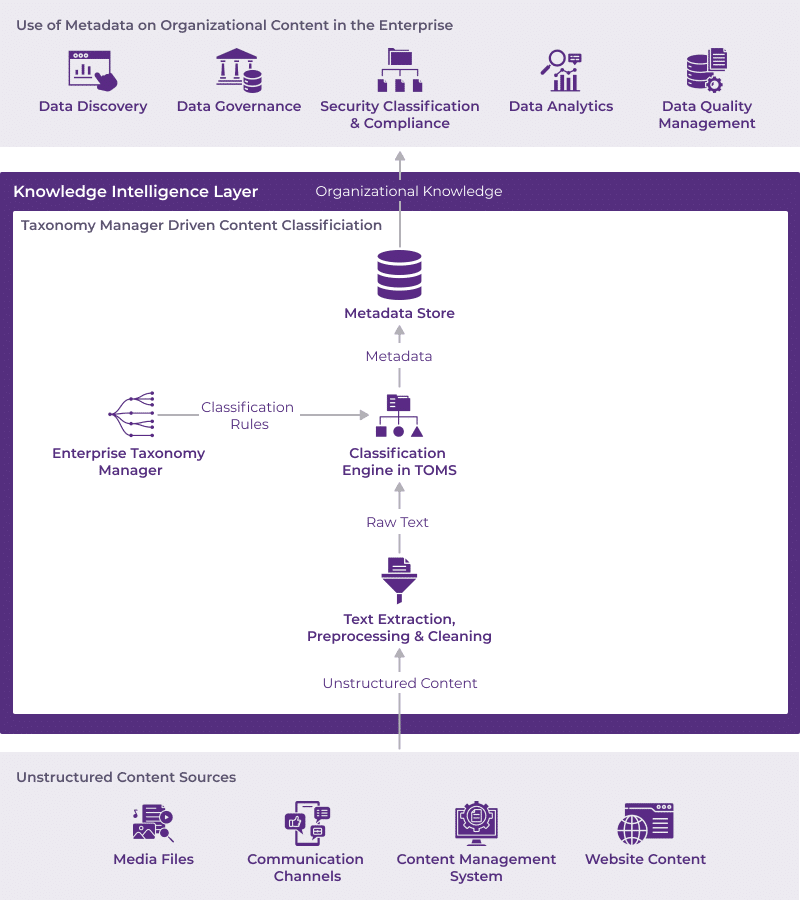
Enterprise AI Architecture: Taxonomy Manager Driven Content Classification
While there are variations across TOMS vendors in how they classify unstructured content using a taxonomy (such as leveraging just textual metadata or using structural relationships between taxonomy concepts to categorize content), as shown in the figure above, the high-level architecture integrating a TOMS with enterprise systems managing unstructured content and leveraging TOMS-generated metadata is generally independent on specific TOMS platforms. In this architecture, when an information architect deems a taxonomy is ready for use, they publish the corresponding classification rules to the TOMS-specific classification engine. Typically, organizations configure custom change listeners for taxonomy publication. This helps them decide when to tag their unstructured content with the published rules and store these tags in a central metadata repository to power many use cases in the enterprise. Sometimes, however, TOMS platforms offer native connectors for specific CMS such as SharePoint or WordPress to manage automatic tagging of its delta content upon the publication of a new taxonomy version.
We work with many leading TOMS vendors in our typical taxonomy accelerator engagements, and you can learn more about specific use cases and success stories in our knowledge base regarding the application of this approach when it comes to powering content discovery – from a knowledge portal in a global investment firm to creating more personalized customer experiences using effective content assembly at a financial solutions provider organization.
3. LLM-Powered Content Classification
With the rise of LLMs in recent years, we have been working with various prompting techniques to effectively classify text using LLMs in our engagements. Based on our experimentation, we have found that a few-shot prompting approach, in which the language model is provided with a small set of labelled examples along with a prompt to guide the classification of unstructured content, achieves high accuracy in text classification tasks even with limited labeled data. This does not, however, deemphasize the need for designing effective prompts to improve accuracy of the in-context learning approach that is central to any prompt engineering technique.
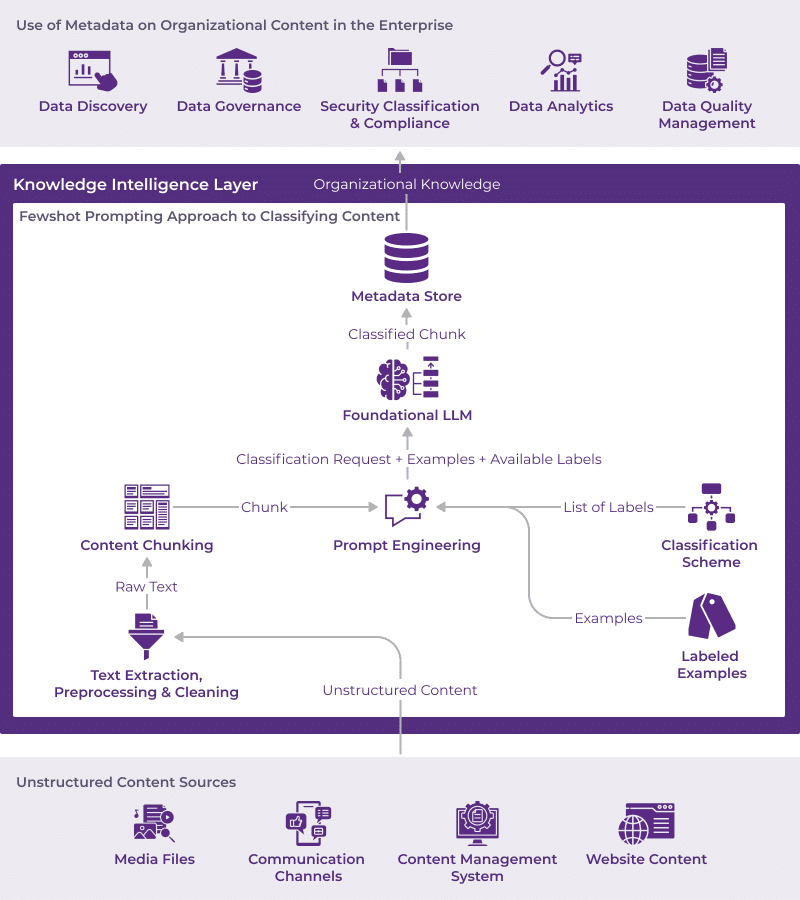
Enterprise AI Architecture: LLM-Powered Content Classification
As illustrated in the figure above, a prompt in a few-shot learning approach to content classification includes the classification scheme and labelled examples from domain SMEs besides the raw text we need the LLM to classify. But because of the limitations of the context window for most state-of-the-art (SOTA) LLMs, the input text often needs to be chunked post-preprocessing and cleaning to abide by the length limitations of the prompt (also shown in the figure above). What is not included in the image, however, are the LLM optimization techniques we often employ to improve the classification task performance at scale. It is widely accepted that any natural language processing (NLP) task that requires interaction with a LLM, which is often hosted on a remote server, will not be performant by default. Therefore, in our typical engagements, we employ optimization techniques such as caching prior responses, batching multiple requests into one prompt, and classifying multiple chunks in parallel beyond basic prompt engineering to implement a scalable content classification solution for the enterprise.
Last year we used the LLM-powered content classification approach when we completed a knowledge graph accelerator project with a public safety agency in Europe, where we could not use a TOMS-driven content classification approach to instantiate a knowledge graph. This is because of the risks associated with sensitive data transfer out of Azure’s Northern European region where the solution was hosted and into the infrastructure of the hosted TOMS platform (which was outside the allowed region). In this case, a LLM-powered content classification such as a few-shot prompting approach allowed us to develop the solution by extracting entities from their unstructured content and instantiating a knowledge graph that facilitated context-based, data-driven decision making for construction site planners at the agency.
More recently, we used the LLM-powered content classification approach when we engaged with a non-profit charitable organization to analyze their healthcare product survey data to understand its adoption in a given market and demographic and ultimately inform future product development. We developed a comprehensive list of product adoption factors that are not easily identified and included in product research. We then leveraged this controlled vocabulary of product adoption factors and Azure OpenAI models to classify the free form survey responses and understand the distinct ways in which these factors influence each other, thus contributing to a more nuanced understanding of how users make decisions related to the product. This enhanced pattern detection approach enabled a holistic view of influencing factors, addressing knowledge gaps in future product development efforts at the organization.
4. AI-Augmented Topic Taxonomy Generation
Up until this point in the article, we have focused on using taxonomies to structure unstructured content. We will now shift to using machine learning to analyze unstructured content and propose taxonomies and create knowledge graphs using AI. We will discuss how in recent years, LLMs have simplified entity and relationship extraction, enabling more organizations to incorporate knowledge graphs into their data management.
While we generally do not advise our clients to use LLMs without a human-in-the-loop process to create production grade domain taxonomies, we have used LLMs in past engagements to augment and support our taxonomic experts in naming latent topics in semantically grouped unstructured content and therefore create a very rough draft version of a topic taxonomy.
Elaborating on the figure below, our approach centers on three key tasks:
- Unsupervised clustering of the dataset,
- Discovering latent themes within each cluster,
- Creating a topic taxonomy based on these themes, and
- Engaging taxonomists and domain experts to validate and enhance taxonomy.
Because of the token limits inherent in all SOTA embedding models, once raw text is extracted from unstructured content, preprocessed, and cleaned, it has to be chunked before numerical representations that encapsulate semantic information called embeddings can be created by the embedding generation service and stored in the vector database. The embedding generation service may optionally include quantization techniques to address the high memory requirements for managing embeddings of a large dataset. Post-embedding generation, the taxonomy generation pipeline focuses on semantic similarity calculation. While semantic similarity between the underlying content or corpora can be trivially computed as the inner product of embeddings, for scalability reasons, we typically project the embeddings from their original high-dimensional space to lower dimensions, while also preserving their local and global data structures. At this point, the content clustering service will be able to use the embeddings as input features of a clustering algorithm, enabling the identification of related categories based on embedding distances. The next step in the process of autogenerating taxonomy concepts is to infer the latent topic of each cluster using an LLM as part of the latent topic identification service. Finally, a draft taxonomy is available for validation and update by domain experts before it can be used to power enterprise use cases from data discovery to analytics.

Enterprise AI Architecture: AI-Augmented Topic Taxonomy Generation
We have enabled consumer-grade semantic capabilities using this very approach for taxonomy generation specifically for non-financial risk management in production at a multi-national bank by collapsing their original risk dataset from 20,000 free-text risk descriptions into a streamlined process with 1100 standardized taxonomy concepts for risk.
5. AI-Augmented Knowledge Graph Construction
AI-assistance for extracting entities and relationships from unstructured content can utilize methods ranging from transfer learning to LLM-prompting. In our experience, incorporating the schema as part of the latter technique greatly enhances the consistency of entity and relationship labeling. Before loading the extracted entities and relationships into a knowledge graph, LLMs, as well as heuristics as defined by domain SMEs, can be used to further disambiguate those entities.

Enterprise AI Architecture: AI-Augmented Knowledge Graph Construction
Our typical approach for leveraging AI to construct a knowledge graph is depicted in the figure above. It starts with unstructured content processing techniques to generate raw text from which entities can be extracted. Coreference resolution, where all mentions of the same real-world entity are replaced by the noun phrase, often forms the first step of the entity extraction process. In the next step, whether we can employ some of the techniques described in the taxonomy driven content classification section for entity extraction or not depends on the underlying ontology (knowledge model or data schema) and how many of the classes in this data model can be instantiated with a corresponding taxonomy. Even for non-taxonomy classes, we can use transfer learning and prompt engineering to accelerate the extraction of instances of ontological classes from the raw text. Next, we can optionally process the extracted entities through an entity resolution pipeline to identify and connect instances of the same real-world entity within and across content sources into a distilled representation. In the last step of the entity extraction process, if applicable, we can further disambiguate extracted entities by linking them to corresponding entries in a public or private knowledge base (such as Wikidata). Once entities are available, it is time to relate these entities following the ontology to complete the knowledge graph instantiation process. Similar to entity extraction, an array of machine learning techniques ranging from both traditional supervised and unsupervised learning techniques to more modern transfer learning and prompt engineering techniques can be used for relationship classification. For example, when developing a knowledge graph powered recommendation engine connecting learning content and product data, we compared the efficacy of an unsupervised learning approach (e.g., similarity index) to predicting relationships between entities with that of a supervised learning approach (e.g., link classifier) for doing the same.
Closing
While structuring unstructured content with semantic assets has been the focus of this blog, it is clear that it can only be effective by incorporating an organization’s most valuable knowledge asset: its human expertise and all types of data. While I will delve deeper into the technical details of how to encode this expert knowledge into enterprise AI systems in a later segment of this KI architecture blog series, it is evident from the discussion above that mining knowledge from an organization’s vast amount of unstructured content will not be possible without domain expertise. As our case studies illustrate, these complementary techniques for knowledge extraction, topic modeling, and text classification, when combined with domain expertise can help organizations achieve true KI. In the next segment of this blog series, I will explore the technical approaches for providing standardized meaning and context to structured data in the enterprise using a semantic layer. In the meantime, if our case studies describing how we brought structure to our clients’ unstructured content through metadata resonate with you, contact us to help get you started with KI.