
In part one of this series, James Midkiff and Sara Duane, senior technical consultants at EK, discussed what auto-tagging is and when an organization should use it. This blog will discuss auto-tagging best practices to answer the foundational question, “How does my organization use auto-tagging effectively?”
How do I improve my data (content or taxonomy) for auto-tagging? What are some auto-tagging best practices?
 James Midkiff
James Midkiff

There are two main ways that I would recommend improving your data for auto-tagging, content componentization and enriching your taxonomy for auto-tagging.
Componentize the Content
Break up larger content items into smaller consumable segments. There’s an art to segmenting content and, for larger content items, this could be as simple as breaking up the content for each entry in the table of contents. In most cases, each segment should describe a specific task or concept of information. A segment should answer a user’s question completely and avoid covering multiple topics. Once the content is broken down into components, auto-tag each component separately. This ensures that when producing search results or recommendations for users, specific sections of documents can be provided rather than requiring users to dig through the larger document for the section relevant to them. Auto-tagging the content components increases our understanding of the content because we can see the similarities and unique tags between the components.
Enriching your Taxonomy for Auto-tagging
Taxonomies should be evaluated for their use with auto-tagging as they need to be expressive in ways that an auto-tagger can leverage (unlike high-level/more intuitive taxonomies used for search and navigation). Below are a number of questions and expected outcomes that can lead you to revise the taxonomy.
Question 1: Does the taxonomy have a lot of single-word labels, should we auto-tag all of them, and do we expect them to get tagged incorrectly?
Expected Outcome: We want to ensure that single-word labels, e.g., “Investment”, are tagged in the correct context since a single-word label is easier to match in text than a multi-word label.
Question 2: How does the taxonomy leverage acronyms and do they make it easier or harder for terms to be auto-tagged?
Expected Outcome: When acronyms are included in the preferred label of a term, i.e. “National Park Service (NPS)”, we want to make sure that synonyms are provided to match “National Park Service” and “NPS” separately.
Question 3: Do the labels match how each taxonomy concept appears in the content?
Expected Outcome: Similar to question 2, we want to review the taxonomy concepts to make sure they contain the same labels or synonyms as expected in the tagged text. If two departments of an organization refer to a topic by different names, then both names should be captured in the taxonomy. This can be an issue when the taxonomy serves multiple purposes, i.e. the organization of content for users and auto-tagging.
The taxonomy should reflect the way that concepts are represented in the content and an evaluation helps align the taxonomy for auto-tagging purposes.
 Sara Duane
Sara Duane

When considering auto-tagging best practices, there are two main “buckets” of auto-tagging to consider. The first is topical-based auto-tagging which, as I described above, is best suited to content that is rich in the subject matter. To improve your taxonomy for this type of auto-tagging, you should dedicate time to analyzing the content and ensuring that your taxonomy meets the level of term granularity within it. You must ensure that these terms are included as preferred labels or synonyms. For example, if your taxonomy contains a list of motor vehicles, such as automobiles and motorcycles, but the content is much more granular and refers only to specific brands, tags will not be effectively applied to the content. These brands may need to be integrated into the taxonomy to match the level of granularity of the content.
The second “bucket” is rules-based auto-tagging. This refers to automatically applying tags to content based on rules that you establish ahead of time. These rules can be inheriting existing metadata on a piece of content or applying metadata to the content based upon where it is stored or who authored it. For example, it might be the case that all final reports are stored in a few folders. It can be established that any content item coming from those folders is given that content type tag. You will need to work with content SMEs to establish these rules and ensure the accuracy of the tags.
In some cases, rules-based auto-tagging will need to be extended with an algorithmic approach. You can develop a machine learning classification model that analyzes existing content and tags in order to predict the tags that should be applied to new content. This approach helps scale the rules-based auto-tagging approach as the amount of content grows.

In either case, the most significant best practice for conducting auto-tagging is dedicating time to fine-tuning the process. You will need to conduct multiple rounds, tweaking the taxonomy and rules to best fit the content you are working with.
How do I measure auto-tagging success?
James Midkiff
There are some mathematical ways to measure auto-tagging success such as precision, recall, and, a value that combines the two, an F-score. Given two sets of tags for a document, one from a human indexer and one from an auto-tagger,
- Precision is the number of matches divided by the total number of auto-tagger tags,
- Recall is the number of matches divided by the total number of human indexer tags, and
- F-score is the harmonic mean of precision and recall.
Simply put, precision measures how often the auto-tagger was correct when it assigned a concept. For example, if the concept “dogs” was assigned by the auto-tagger to 100 documents, but a human indexer only assigned “dogs” to 75 of those documents, then the precision of the auto-tagger for “dogs” is 75%. However, this is an incomplete measure as it doesn’t consider how many documents were tagged by the auto-tagger. If the auto-tagger assigned “dogs” to one document that matched the human indexer, then it would have a precision of 100%, even if a human indexer still assigned that concept to 75 other documents – the auto-tagger never incorrectly added “dogs” when it shouldn’t have.
Recall, on the other hand, measures how often the auto-tagger assigned a concept that the human indexer assigned. For example, if a human indexer assigns “dogs” to 100 documents and the auto-tagger only assigns it to 20 of those, “dogs” would have a recall of 20%. Again, this number alone isn’t that helpful – if the auto-tagger assigned “dogs” to every document it saw, it would have perfect recall (although the precision would likely be terrible).
 As you can see, neither precision nor recall tell the full story on their own. That’s where the F-score comes in. The F-score balances precision and recall to give a single number that provides an overall idea of how similar the auto-tagger is to a human indexer.
As you can see, neither precision nor recall tell the full story on their own. That’s where the F-score comes in. The F-score balances precision and recall to give a single number that provides an overall idea of how similar the auto-tagger is to a human indexer.
The F-score is a number between 0 and 1, where 0 is terrible and 1 is a perfect match to the human indexer. The number takes into account where tags match, where tags are missed by either party, and the total number of tags. If you have perfect precision but terrible recall (or vice versa), the F-score won’t be very good. This makes sure you don’t over-rely on precision or recall alone.

Sara Duane
EK has an established process for measuring auto-tagging success, although specific measures of success may change based on the client or use case. For a determination of success, oftentimes, a gold standard is key. This gold standard is a pre-determination of the best set of tags for a specific input, such as a content item, given the relevant taxonomies. This gold standard needs to be built or confirmed by SMEs who have expert knowledge of the content for the use case. This gold standard can also be used to train the auto-tagging ML algorithm.
Organizations may also want to consider comparing the results of earlier rounds of auto-tagging to rounds that occur after fine-tuning to demonstrate the improvement in results that this process can bring. For example, EK completed auto-tagging with a US-based investment and insurance company, and following a couple of rounds of finetuning and auto-tagging, the taxonomy was applied to content with an accuracy of 86-99% depending on the metadata field. One of the metrics used to define the success of this result was an accuracy comparison to the earlier round of auto-tagging that occurred pre-fine-tuning.
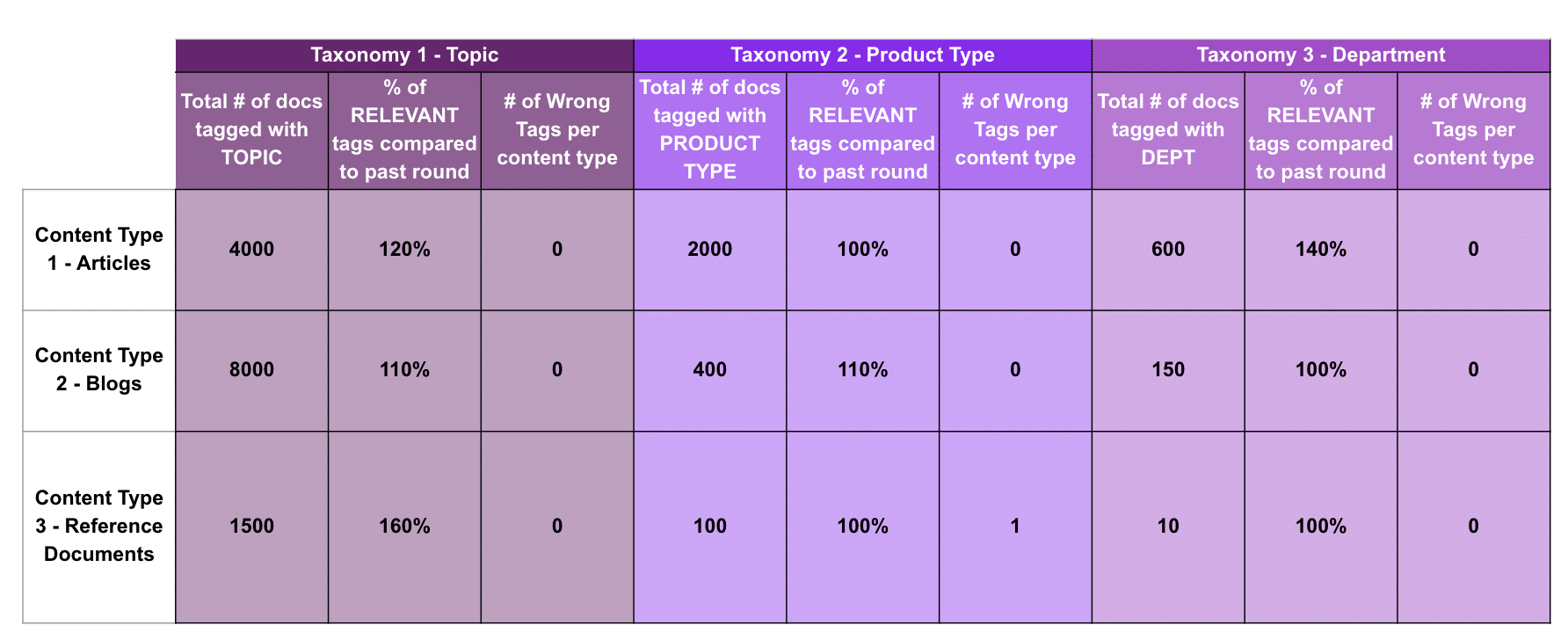
(above) A sample comparison of auto-tagging accuracy per content type from an initial round to a second round.
Additionally, the success of auto-tagging can also be measured by the coverage of tags across the taxonomy. When analyzing the tags that were applied to content, you should determine what categories of your taxonomy these tags originated from. Were all categories of the taxonomy auto-tagged? Were some categories auto-tagged more than others? Were there any categories that didn’t tag well at all? If there were areas of the taxonomy that did not receive as much coverage, you may need to do additional, more granular taxonomy design for the purposes of auto-tagging, focusing on terms that are prominent and important from the content. For example, in the image above, the vehicle type and department taxonomies were tagged less than the topic taxonomy. If I was expecting more pieces of content to be auto-tagged with a vehicle type, I would need to add additional, more granular terms to this taxonomy that are prevalent in the content.
Conclusion
There is no single way to conduct auto-tagging or measure its success. However, adhering to best practices, such as preparing your content and taxonomy for auto-tagging, will increase your organization’s level of success. When choosing a method to measure this success, ensure that the metrics meet your organization’s business and technical requirements.
Are you considering auto-tagging at your organization? Do you want to learn more about the process and how auto-tagging will perform for your use case? We can help! Contact us for more.