
As EK works with our clients to design data models, including taxonomies and knowledge graphs, we often implement corresponding auto-tagging solutions to augment the organization and enrichment of unstructured content. In this blog series, two of our senior technical consultants, James Midkiff and Sara Duane, answer questions to define auto-tagging and help your organization understand when and how to leverage automated tagging and classification capabilities successfully. This is part one of a two-part expert analysis series that focuses on when and how to implement auto-tagging in your organization.

What is Auto-tagging?
 James Midkiff
James Midkiff
Auto-tagging is the process of identifying key pieces of information inside of text and applying those key pieces as metadata to a document. This process usually includes a combination of named entity recognition (NER) and natural language processing (NLP) techniques that identify terms or phrases anywhere within the text. Auto-tagging leverages the following ideas to apply metadata to content:
- Synonyms – the ability to recognize alternative ways of referring to the same concept and their associated acronyms
- Disambiguation – the ability to discern between multiple concepts with the same label (i.e. does “ballast” refer to a ship’s ballast or those used when laying railroad tracks?)
- Custom Rules – using “if-then” scenarios to check for patterns within the text and apply concepts as a result of those scenarios.
These applied terms and phrases help content and data authors and consumers better understand the text context by providing additional context clues.
 Sara Duane
Sara Duane
Auto-tagging is an advanced application of taxonomy in which terms are automatically applied to content as tags through text recognition, inheritance, or other automated means. These tags describe the content and thus can be useful for search and browsing, as they improve the findability of the content items users are looking for.

For example, a company we recently worked with wanted to use auto-tagging to automatically apply tags to content based on topics to improve search and findability as well as identify or flag confidential information to be moved to a secure location.
When should my organization use auto-tagging?
James Midkiff
Organizations should consider auto-tagging when they have a lot of text-based content that needs to be described and found. For example, one of our clients had a repository of call center requests and they couldn’t find existing content due to insufficient metadata. They implemented an auto-tagging pipeline to fill in the gaps, enabling call center personnel to quickly find relevant content when serving requests. Whether considering auto-tagging for a new system or a backlog of content that has been accumulating for the past 50 years, auto-tagging helps ensure that text is well described. By improving content metadata, we improve the ability to find and discover properly tagged content in downstream navigation, recommendation, and search interfaces.
Manually tagging content can be costly, time-consuming, error-prone, and require the indexers to be familiar with an organization’s domain and taxonomy. An auto-tagging solution works around these issues by automating the application of metadata and taxonomy quickly while leveraging all the synonyms and acronyms that the organization uses to describe information, ultimately saving the organization money long-term.
Sara Duane
There are many reasons that organizations seek out the powers of auto-tagging. In general, many of these reasons revolve around the overall themes of improving search/findability and saving human effort and time.
An organization may be looking for ways to improve the findability of content. As having accurate content tags helps to meet this goal, an organization may want to use auto-tagging to automatically apply a taxonomy and/or ontology to content items as tags. Oftentimes, this auto-tagging will work best when the content is both highly text-heavy and subject-oriented and the taxonomy has been aligned with the terminology within the content, providing an organization a way to automatically recognize “aboutness.”
It is also possible that organizations may already tag their content for findability, but consider auto-tagging for time-saving and consistency reasons. By using auto-tagging, individuals do not need to manually tag content, thus giving them time back in their day for other tasks and also increasing the consistency with which tags are applied, as individuals tag with more subjectivity.
How do I get started? How do I implement this into existing workflows?
James Midkiff
There are a few iterative steps an organization can take to start auto-tagging content.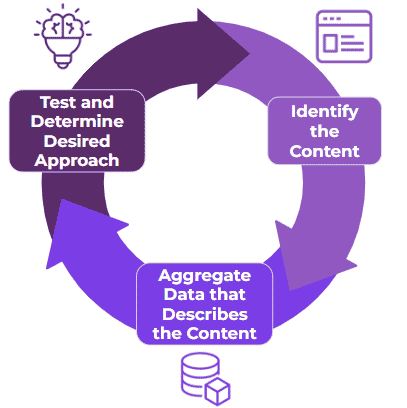
Identify the Content
Determine what systems and what content within those systems could benefit from auto-tagging. Benefits could be realized through improved content description and findability as well as time saved creating content.
Aggregate or build the data that describes your content
We want to ensure we tag all of the relevant and informative data about a piece of content. For larger pieces of content, the full text should be auto-tagged. However, it’s common to highlight critical concepts by tagging the title and abstract of the text separately. Make sure to workshop the fields and rules you want to apply when tagging content.
Test it and determine the desired approach
Workshop your approach. Don’t just slap an auto-tagging solution on your content and expect success. Iterate on what is tagged, how the tags are combined to describe the content, and what portions of the taxonomy can be auto-tagged and validated. Additionally, identify points in tagging workflows where individuals can review, update, and approve tags applied by the auto-tagger. Providing this supervised tagging approach, also referred to as a human-in-the-loop workflow, is key to a successful auto-tagging process as it allows you to confirm the auto-tagging approach and discover new tagging rules that could be applied. Integrate auto-tagging with existing systems and workflows or determine if a one-time migration covers your use case. Evaluate each decision as you work towards the best auto-tagging approach for your organization.
Sara Duane
To start the auto-tagging process, there are foundational steps an organization should take in the realms of content and taxonomy. As James mentioned, an organization should select the sampling of content that will be used for auto-tagging. Ideally, this content should be text-heavy and driven by specific use cases. Once the content is selected, taxonomies should be built or refined to represent the tags you’d like the content to receive. EK’s bottom-up analysis approach is key in this process, as it is important for the taxonomy to be designed around the content that will be tagged.
This taxonomy can then be implemented into a taxonomy management system with auto-tagging capabilities that then applies these tags to content via an API. Building the application of tags into an organization’s existing workflows is key for consistency and usability of the process, so the system can be configured to apply these tags upon the upload of the content. Typically, to start, EK recommends that a SME manually reviews the automatically applied tags to ensure alignment with the content and provide learning/feedback for the next iteration and fine-tuning of the auto-tagging algorithms.
Conclusion
In this Expert Analysis, we covered the value of auto-tagging and the initial steps for getting started at your organization. Part two of this blog will go a step further and address best practices for auto-tagging and measuring auto-tagging success.
In the meantime, check out some of our case studies to see how organizations are leveraging auto-tagging:
And, are you interested in learning more about auto-tagging for your organization? Contact us!