
When your users are looking for content, they rarely have time or patience with search. This often leads to frustration for both end users and those who control the search application. Users expect search to just “work” and then are highly disappointed when what they think is a simple search, provides them with irrelevant results – or worse, no results at all. A possible reason for some of these search challenges is that search engineers often think that users are searching whole documents. The truth is that users are actually just searching the fields that make up those documents. In order to deliver search that aligns your users’ intentions with what is stored in your search application, we have to fix the fields that make up your documents.
Fixing search involves tweaking the terms by properly tokenizing and analyzing text, as well as suggesting corrections to terms that may be misspelled. In this first part of my three-part blog series about optimizing search relevance, I’ll explain some technical steps on how to improve the precision of search. Specifically I’ll be discussing the importance of feature signaling in your enterprise search solution and using specific examples from Elasticsearch. If you would like to test the technical features on your own, follow the ‘Getting Started with Elasticsearch’ guide to set up an Elasticsearch instance and test out running commands against the Elasticsearch REST API.
In order to deliver search that aligns your users’ intentions with what’s stored in your search application, we have to fix the fields that make up documents.
Feature Signaling
How you put data into your system is important; as the saying goes, “garbage in, garbage out.” One way to improve the way you put data into your system is feature signaling. Feature signaling means crafting the data you index into ways your users will search for things, so that the fields that are searched provide strong relevancy signals. For example, when a user enters “bbq near 77489-3175”, a relevant search would match documents related to “bbq”,“barbeque”, or “barbecue”, as well as understand that the 9 digit number is the zip code for a neighborhood in Missouri City, TX. Crafting relevant signals could involve relating the term “bbq” with its synonyms “barbecue” and “barbeque,” or classifying a 9 digit number as a zip code and storing the 9 and 5 digit versions in particular fields. These examples of feature signaling take into account different words users leverage to search for the same thing, boosting relevancy and ensuring a seamless search experience.
Analyzers
|
|
The standard analyzer includes 2 filters that transform searched query terms by lowercasing them and removing stopwords. Stop words are terms that typically don’t hold significant meaning, like “the”, and “is”. |

Since data is stored and queried via fields, matching relevant documents based on signals in fields starts with aligning users’ search terms with the data indexed through analyzers. Analyzers play a crucial part in the matching terms to documents during both the indexing of text as well as the querying process. The search engine first indexes the documents by breaking them up – usually on whitespace characters – and transforming each segment into a token using a tokenizer. Tokens are sub-strings of text that relate back to the original terms indexed or queried. In order to match query terms with the terms stored in the search index, search engines compare the characters within the term, the position of the terms in the data and even the number of characters in a term. Finally, documents that contain the terms are returned based on each document’s relevancy.
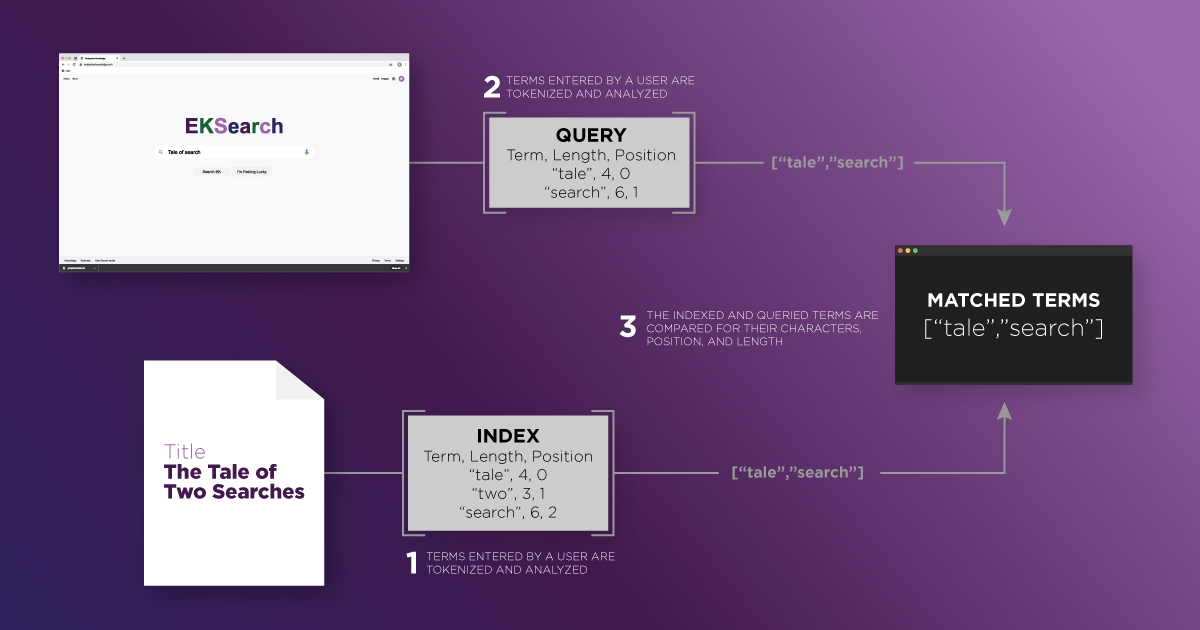
Analyzers transform text using filters. Filters either replace, drop, or pass text on as tokens through various transformations. Take for example the word “flowers.” There are filters called stemmers which will stem terms based on heuristics down to a root form. This means that the term “flowers” would become “flower.” Analyzers that use these filters allow various forms of a term to be queried and still match what is in the search index. Each field is defined by its own filter, which transforms the text indexed and queried in that field. This is why analyzers are the heart of crafting strong signals to fields.
Synonyms
|
|
This is an example of a synonym analyzer. It makes synonyms of terms found in “mysynonyms.txt” using the graph_synonyms filter when documents are indexed and queried. |

Synonyms are a good example of the power and importance of analyzers in fields. For example, say you have a state field that users can search based on both abbreviations and the full state name. You would want references to “VA” to tie to references to “Virginia”. Using a synonym analyzer, search terms can map to multiple words that have a similar meaning, based on mappings you define.This way your search can have more roads that lead to relevant content returned back to you users.
Misspellings
Sometimes the flaws lie outside the data within the search index. Spelling errors are a major reason why users do not receive relevant search results. However, there is no reason to fret. Misspellings can be handled while also giving your users clarity on the syntax of terms. A helpful way to handle misspellings is to use correctly tokenized words to perform a mini-search and suggest to a user those query terms that are found in the index.
| The search suggester here takes a string and searches if the tokens are found in the index. The terms “checking” and “search” are returned as suggested terms found in the index. |
|

In the example above, the “suggest” keyword performs a search looking for terms that appear in the index that are similar to the terms queried. Those are then brought back, and can be surfaced to users as possible suggestions to search on.
Data in Various Formats
Crafting feature signals in fields normalizes what terms users enter to search with what terms lie in the search index. Normalization is important in transforming not just words, but data that may be represented in many formats.Take for example the many formats in which a single phone number may be represented: (123) 456- 7890, 456-7890, +11234567890. You can use analyzers to match these various forms when a user searches for a phone number. Acronyms are another format of data that should be transformed for more relevant search results. Users may enter acronyms with or without periods and you would still want relevant results to show. Modeling the intent of users queries through analyzers are foundational in getting data in various formats matched in fields.
|
|
The “phone_num_parts” filter captures the 7 digit, 10 digit as a pattern_capture filter and the original format of phone numbers through the preserve_original option. |

Conclusion
Hopefully this blog has given you some search best practices as well as items on which to take immediate action in your own environments. Understanding search can feel like an overwhelming sea. However, when you quiet the tide by focusing on what your users are looking for, you can offer a lighthouse of query terms to help surface the documents they are seeking with more precision.
Remember that how text is tokenized in a search index is fundamental to what can be found in document fields. Analyzers help map synonyms and capture data in various formats, and tools like the suggester API increase the precision of queries by trying to better align the terms of your users’ query with the data in your search engine when misspellings occur. If you would like to discuss how Enterprise Knowledge could help you steer through this ocean of search contact us.