
Organizations continue to invest heavily in efforts to unify institutional knowledge and data from multiple sources. This typically involves copying data between systems or consolidating it into a new physical location such as data lakes, warehouses, and data marts. With few exceptions, these efforts have yet to deliver the connections and context required to address complex organizational questions and deliver usable insights. Moreover, the rise of Generative AI and Large Language Models (LLMs) continue to increase the need to ground AI models in factual, enterprise context. The result has been a renewed interest in standard knowledge management (KM) and information management (IM) principles.
Over the last decade, enterprise knowledge graphs have been rising to the challenge, playing a transformational role in providing enterprise 360 views, content and product personalizations, improving data quality and governance, and providing organizational knowledge in a machine readable format. Graphs offer a more intuitive, connected view of organizational data entities as they shift the focus from the physical data itself to the context, meaning, and relationships between data – providing a connected representation of an organization’s knowledge and data domains without the need to make copies or incur expensive migrations – and most importantly today, delivering Knowledge Intelligence to enterprise AI.
While this growing interest in graph solutions has been long anticipated and is certainly welcome, it is also yielding some stalled implementations, unmet expectations, and, in some cases, complete initiative abandonment. Understanding that every organization has its own unique priorities and challenges, there can be various reasons why an investment in graph solutions did not yield the desired results. As part of this article, I will draw upon my observation and experience from industry lessons learned to pinpoint the most common culprits that are topping the list. The signs are often subtle but can be identified if you know where to look. These indicators typically emerge as misalignments between technology, processes, and the organization’s understanding of data relationships. Below are the top tell-tale signs that suggest a trajectory of failure:
1. Treated as Traditional, Application-Focused Efforts (As Technology/Software-Centric Programs)
If I take one datapoint out of observation from the organizations that we work with, the biggest hurdle to adopting graph solutions isn’t about whether the approach itself works – many top companies have already shown it does. The real challenge lies in the mindset and historical approach that organizations have developed over many years when it comes to managing information and technology programs. The complex questions we are asking from our content and data today are no longer fulfilled by the mental models and legacy solutions organizations have been working with for the last four or five decades.
Traditional applications and databases, like relational or flat file systems, are built to handle structured, tabular data, not the complex, interwoven relationships. The real power of graphs lies in their ability to define organizational entities and data objects (people, customers, products, places, etc. – independent of the technology they are stored in). Graphs are optimized to handle highly interconnected use cases (such as networks of related business entities, supply chains, and recommendation systems), which traditional systems cannot represent efficiently. Adopting such a framework requires a shift from legacy application/system-centric to a data-centric approach where data doesn’t lose its meaning and context when taken out of a spreadsheet, a document, or a SQL table.
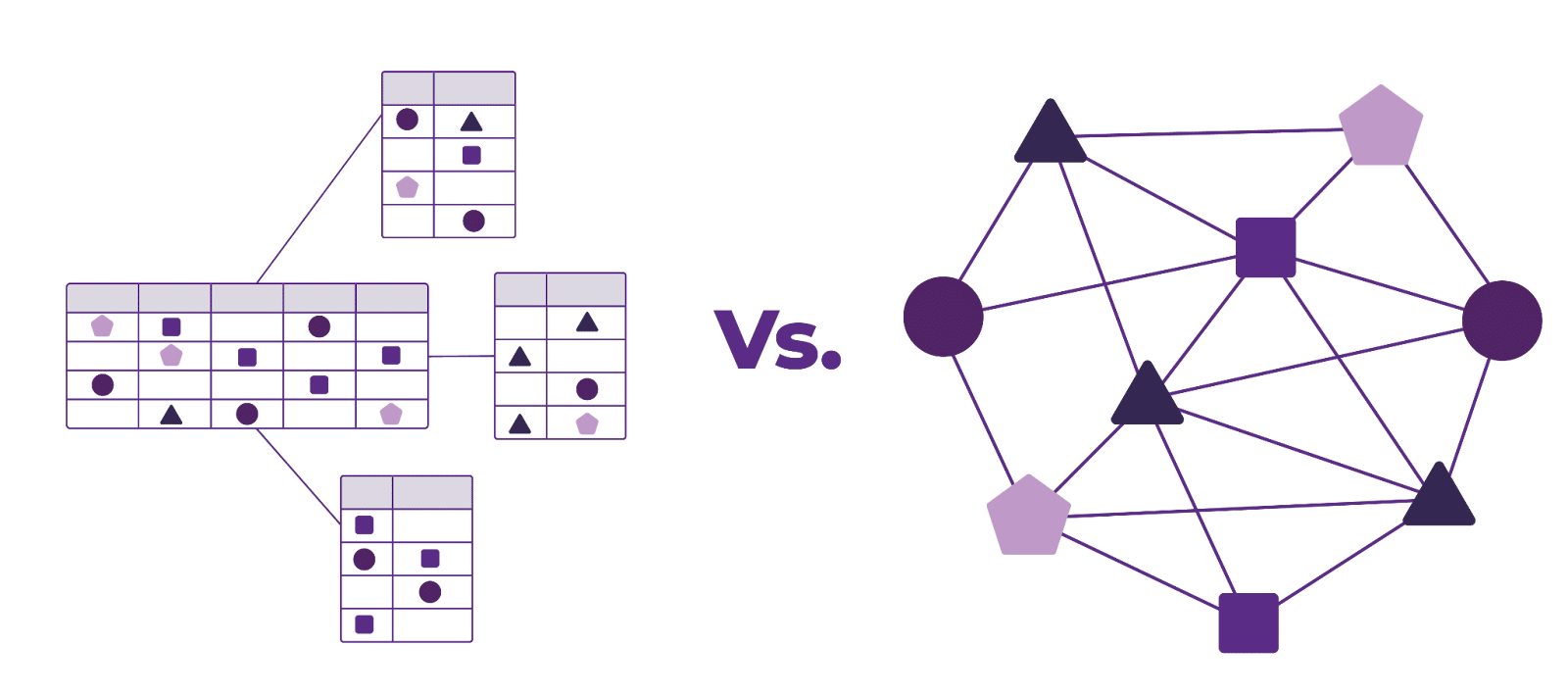
Sticking with such traditional models and relying on legacy systems and implementation approaches that don’t support relationship modeling to make graph models work results in an incomplete or superficial understanding of the data leading to isolated or incorrect decisions, performance bottlenecks, and ultimately lack of trust and to failed efforts. Organizations that do not recognize that graph solutions often represent a significant shift in how data is viewed and used within an organization are the ones that are first to abandon the solution or incur significant technical debt.
Early Signs of Failure:
- Implementation focuses excessively on selecting the best and latest graph database technologies without the required focus on data modeling standards. In such scenarios, the graph technology is deployed without a clear connection to key business goals or critical data outcomes. This ultimately results in misalignment between business objectives and graph implementation – often leading to vendor lock.
- Graph initiatives are treated as isolated IT projects where only highly technical users get a lot out of the solution. This results in little cross-functional involvement from departments outside of the data or IT teams (e.g., marketing, customer service, product development); where stakeholders and subject matter experts (SME) are not engaged or cannot easily access or contribute to the solution throughout modeling/validation and analysis – leading to the intended end users abandoning the solution altogether.
- Lack of organizational ownership of data model quality and standards. Engineering teams often rely on traditional relational models, creating custom and complex relationships. However, no one is specifically responsible for ensuring the consistency, quality, or structure of these data models. This leads to problems such as inconsistent data formats, missing information, or incomplete relationships within the graph, which ultimately hinders the scalability and performance needed to effectively support the organization.
What Success Looks Like
Graph models rely on high-quality, well-structured business context and data to create meaningful relationships. As such, a data-centric approach requires a holistic view of organizational knowledge and data. If the initiative remains isolated, the organization will miss opportunities to fully leverage the relationships within its data across functions. To tackle this challenge, one of the largest global financial institutions is investing in a semantic layer and a connected graph model to enable comprehensive and complex risk management across the firm. As a heavily regulated financial services firm, their risk management processes necessitate accurate, timely, and detailed data and information to work. By shifting risk operations from application-centric to data-centric, they are investing in standardized terminology and relationship structures (taxonomies, ontologies, and graph analytics solutions) that foster consistency, accuracy and connected data usage across the organization’s 20+ legacy risk management systems. These consumer-grade semantic capabilities are in production environments aiding in business processes where the knowledge graph connects multiple applications providing a centralized, interconnected view of risk and related data such as policies, controls, regulations, etc. (without the need for data migration), facilitating better analysis and decision-making. These advancements are empowering the firm to proactively identify, assess, and mitigate risks, improve regulatory reporting, and foster a more data-driven culture across the firm.
2. Limited Understanding of the Cost-Benefit Equation
The initial cost of discovering and implementing graph solutions to support early use cases can appear high due to the upfront work required – such as to the preliminary setup, data wrangling, aggregation, and fine tuning required to contextualize and connect what is otherwise siloed and disparate data. On top of this, the traditional mindset of ‘deploy a cutting-edge application once and you’re done’ can make these initial challenges feel even more cumbersome. This is especially true for executives who may not fully understand the shift from focusing on applications to investing in data-driven approaches, which can provide long-term, compounding benefits. This misunderstanding often leads to the premature abandonment of graph projects, causing organizations to miss out on their full potential far too early. Here’s a common scenario we often encounter when walking into stalled graph efforts:
The leadership team or an executive champion leading the innovation arm of a large corporation makes a decision to experiment with building data-models and graph solutions to enhance product recommendations and improve data supply chain visibility. The data science team, excited by the possibilities, set up a pilot project, hoping to leverage graph’s ability to uncover non-obvious (inexplicit) relationships between products, customers, and inventory. Significant initial costs arise as they invest in graph databases, reallocate resources, and integrate data. Executives grow concerned over mounting costs and the lack of immediate, measurable results. The data science team struggles to show quick value as they uncover data quality issues, do not have access to stakeholders/domain experts or to the right type of knowledge needed to provide a holistic view, and likely lack the graph modeling expertise. Faced with escalating costs and no immediate payoff, some executives push to pull the plug on the initiative.
Early Signs of Failure:
- There are no business cases or KPIs tied to a graph initiative, or success measures are centered around short-term ROI expectations such as immediate performance improvements. Graph databases are typically more valuable over time as they uncover deep, complex relationships and generate insights that may not be immediately obvious.
- Graph development teams are not showing incremental value leading to misalignment between business goals – ultimately losing interest or becoming risk-averse toward the solution.
- Overemphasis on up-front technical investment where initial focus is only on costs related to software, talent, and infrastructure – overlooking data complexity and stakeholder engagement challenges, and without recognizing the economies of scale that graph technologies provide once they are up and running.
- The application of graphs for non-optimal use cases (e.g., for single application, not interconnected data) – leading to the project and executives not seeing the impact and overarching business outcomes that are pertinent (e.g., providing AI with organizational knowledge) and impact the organization’s bottomline.
What Success Looks Like
A sizable number of large-scale graph transformation efforts have proven that once the foundational model is in place, the marginal cost of adding new data and making graph-based queries drops significantly. For example, for a multinational pharmaceutical company, this is measured in a six-digit increase in revenue gains within the first quarter of a production release as a result of the data quality and insights gained within their drug development process. In doing so, internal end-users are able to uncover the answers to critical business questions and the graph data model is poised to become a shareable industry standard. Such organizations who have invested early and are realizing the transformational value of graph solutions today understand this compounding nature of graph-powered insights and have invested in showing the short-term, incremental value as part of the success factors for their initial pilots to maintain buy-in and momentum.
3. Skillset Misalignment and Resistance to Change
The success of any advanced solution heavily depends on the skills and training of the teams that will be asked to implement and operationalize it. The reality is that the majority of data and IT professionals today, including database administrators, data analysts, and data/software engineers, are often trained in relational databases, and many may have limited exposure to graph theory, graph databases, graph modeling techniques, and graph query languages.
This challenge is compounded by the limited availability of effective training resources that are specifically tailored to organizational needs, particularly considering the complexity of enterprise infrastructure (as opposed to research or academia). As a result, graph technologies have gained a reputation for having a steep learning curve, particularly within the developer community. This is because many programming languages do not natively support graphs or graph algorithms in a way that seamlessly integrates with traditional engineering workflows.
Moreover, organizations that adopt graph technologies and databases (such as RDF-based GraphDB, Stardog, Amazon Neptune, or property-graph technologies like Neo4j) often do so without ensuring their teams receive proper training on the specific tools and platforms needed for successful scaling. This lack of preparation frequently limits the team’s ability to design effective graph data models, engineer the necessary content or pipelines for graph consumption, and integrate graph solutions with existing systems. As a result, organizations face slow development cycles, inefficient or incorrect graph implementations, performance issues, and poor scalability – all of which can lead to resistance, pushback, and ultimately the abandonment of the solution.
Early Signs of Failure:
- Missing data schema or inappropriate data structures such as lack of ontology (especially a theme for property graphs), incorrect edge direction, missing connections where important relationships between nodes are not represented in the graph – leading to incomplete information, flawed analysis, and governance overhead.
- The project team doesn’t have the right interdisciplinary team representation. The team tasked with supporting graph initiatives lacks the diversity in expertise, such as domain experts, knowledge engineers, content/system owners, product owners, etc.
- Inability to integrate graph solutions with existing systems as a result of inefficient query design. Queries that are not optimized to leverage the structure of the graph result in slow execution times and inefficient data retrieval where data is copied into graph resulting in redundant data storage – exacerbating the complexity and inefficiency in managing overall data quality and integrity.
- Scalability limitations. As the size of the graph increases, the processing time and memory requirements become substantial, making it difficult to perform operations on large datasets efficiently.
What Success Looks Like
By addressing the skills gap early, planning for the right team composition, aligning teams around a shared understanding of the value of graph solutions, and investing in comprehensive training ecosystems, organizations can avoid common pitfalls that lead to missed opportunities, abandonment or failure of the graph initiative. A leading global retail chain for example, invested in graph solutions to aid their data and analytics teams in enhancing reporting. We worked with their data engineering teams to conduct a skills gap analysis and develop tailored training workshops and curriculum for their various workstreams. The approach took five-module intensive training that is taught by our ontology and graph experts and a learning ecosystem that supported various learning formats, persona/role based training, practice labs, use case based hands-on training, Ask Me Anything (AMA) Sessions, industry talks, and on demand job aids tutorials and train-the-trainer modules.
Employees were further provided programmatic approaches to tag their knowledge and data more effectively with the creation of a standard set of metadata and tags and data cataloging processes, and were able to leverage training on proper data tagging for an easier search experience. As a result, the chain acquired knowledge on the best practices for organizing and creating knowledge and data models for their data and analytics transformation efforts, so that less time and productivity was wasted by employees when searching for solutions in siloed locations. This approach significantly minimized the overlapping steps and the time it took for data teams to develop a report from 6 weeks to a number of days.
Closing
Graph implementations require both an upfront investment and a long-term vision. Leaders who recognize this are more likely to support the project through its early challenges, ensuring the organization eventually benefits fully. A key to success is having a champion who understands the entire value of the solution, can drive the shift to a data-centric mindset, and ensures that roles, systems, processes, and culture align with the power of connected data. With the right approach, graph technologies unlock the power of organizational knowledge and intelligence in the age of AI.
If your project has any of the early signs of failure listed in this article, it behooves you to pause the project and revisit your approach. Organizations embarking on a graph initiative, not understanding or planning for the foundations discussed here frequently end up with stalled or failed projects that never provide the true value a graph project can deliver. Are you looking to get started and learn more about how other organizations are approaching graphs at scale or are you seeking to unstick a stalled initiative? Read more from our case studies or contact us if you have specific questions.