
In 2023, ChatGPT’s explosive popularity made Artificial Intelligence (AI) language models a household name. In essence, these models are a key component of natural language processing (NLP), a field of AI, focused on enabling computers to understand and generate human language. As we have seen with the rise of large language models (LLM) — AI technology powering sophisticated chatbots such as ChatGPT — the application of these models is diverse and includes text completion, language translation, chatbots, virtual assistants and speech recognition. One major problem with LLM, however, is that its knowledge is limited to publicly available information, making it hardly relevant for domain specific use cases relying on private or confidential organizational information. Therefore, expanding and updating the knowledge of such a LLM with domain specific information is highly relevant for any enterprise today. Luckily, a knowledge graph is an effective tool for just that. Today, knowledge graphs have established themselves as a well-understood technology for knowledge representation and reasoning. In this blog, we will discuss the primary technical considerations for building and maintaining a production-scale knowledge graph.
Technical Considerations When Implementing a Knowledge Graph
The figure below illustrates the key technical factors and the related best practices at a high level that any enterprise should consider, whether they are taking their very first graph implementation to production or their twentieth:
- Use Case and Business Value
- Data Information and Preparation
- Graph Instantiation
- Path to Production
- Operations and Maintenance
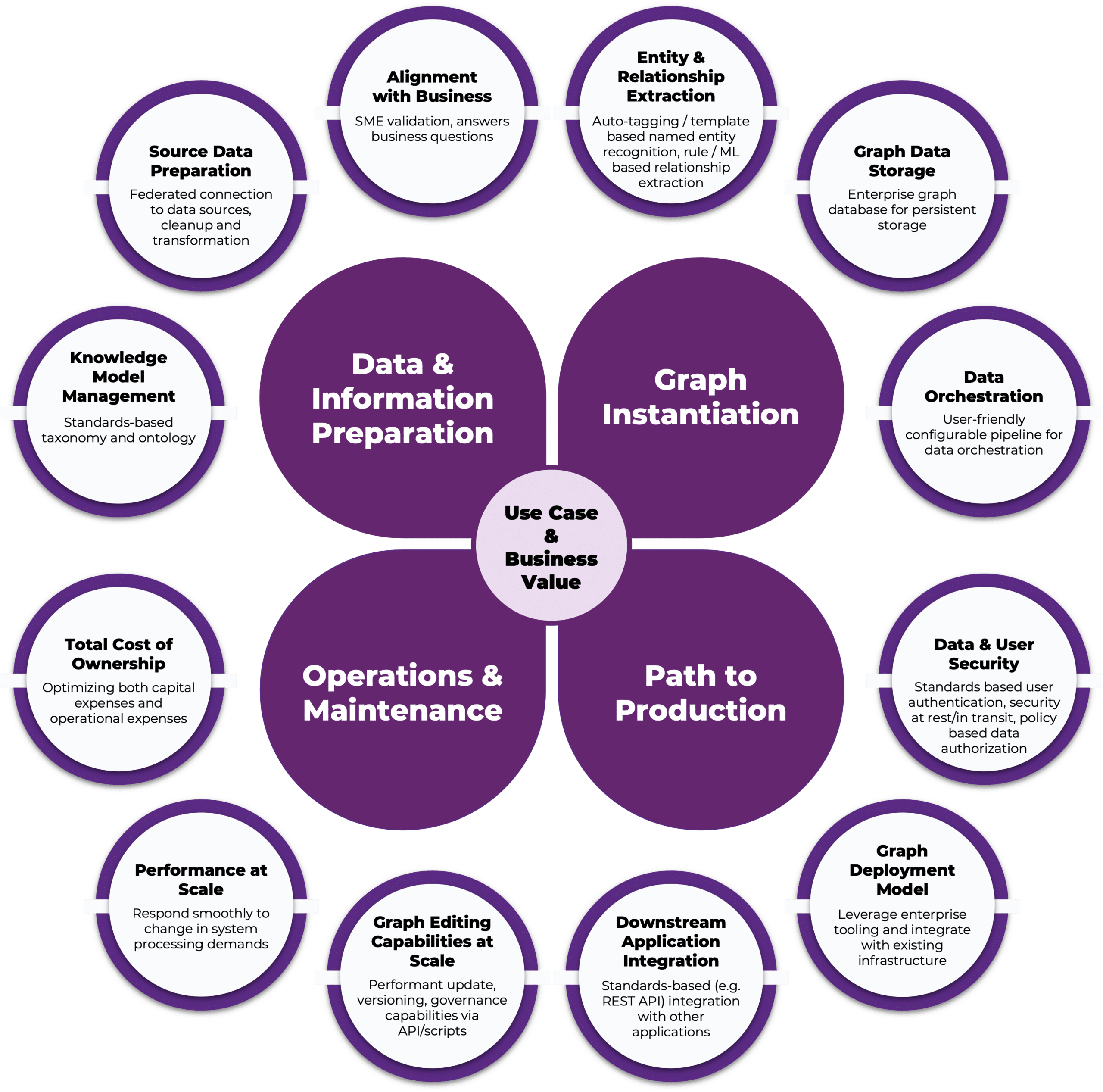
Use Cases and Business Value
Use cases and business value act as the North Star in any software development project, and graph implementation is no different. It is truly the primary indicator for scale, because if the use case does not resonate with the business user and makes a tangible impact, it will likely die out at the experimentation stage. As most enterprise AI initiatives generally follow the industry-standard CRISP-DM model that includes a business understanding stage, for a knowledge graph implementation initiative to enable enterprise AI use cases, they must also include target persona and end users, guiding principles and sponsors, technical use cases, data assets, process inputs and outputs, and business value and outcome. For inspiration on real-world AI use cases that EK has previously helped clients unlock through knowledge graph implementation, see this blog.
Data and Information Preparation
If you are in some type of data ingestion or preparation role, it is likely that you have experienced some level of the “garbage in, garbage out” problem. Drawing a parallel with the data understanding and data preparation stages in the CRISP-DM model that traditional AI initiatives typically utilize, organizations must pay particular attention to the data and information preparation stage of any knowledge graph implementation project. As ChatGPT has recently shown the world, good data is key to superior AI models. Thus, for a knowledge graph to make data useful to the organization, it must first adequately represent the organization’s content in it which will only work if an organization employs good data preparation techniques. Therefore, EK recommends addressing the following components of the data and information preparation stage for knowledge graph projects:
Knowledge Model Management including taxonomy and ontology management
Core design components to knowledge graphs include ontologies and taxonomies. The ontology provides the graph instance with an interoperable schema to standardize, enrich, and reconcile source data, giving users and applications a unified and reliable view of data across disparate data sources. Taxonomies, on the other hand, are a proven means of describing content using controlled vocabularies in a way that resonates with the business; they can be used for content tagging and entity extraction as well as representing core metadata modeled in the graph. These standard knowledge organization approaches provide AI, specifically LLMs, with a unique ability to transform unstructured data into a well-formed knowledge graph. Alternatively, such a knowledge model can form the basis of fine-tuning a LLM to an organization’s own information.
Source Data Preparation including inventorying, data curation and mapping
As mentioned before, a successful AI solution relies on quality data. For that reason, it is imperative that the data used to train an AI model is accurate and up-to-date, especially if a knowledge graph is being used to fine-tune a general-purpose LLM. In which case, that graph must be a true representation of the domain information. Furthermore, a knowledge graph implementation driven by identifying and curating source data relevant to the use cases that can be ingested, transformed, and stored according to the knowledge model ensures reliable and explainable AI models. In turn, leveraging AI models to analyze existing data coupled with conducting user research to determine relevant facets of the content to the use case results in a symbiotic relationship between graphs and AI that also helps organizations optimize and scale their journey towards sustainable and explainable AI. Once the high level data sources are identified, it is important to conduct an AI-assisted detailed data mapping and analysis to ensure that there is evidence for the ontology or data model in the chosen data sets; if not, curate the missing data to support the use case. See here for a concrete example of mapping tabular data to a graph and how this process has enabled several recent partner organizations to power their recommendation engines and chatbots.
Alignment with Business
Any product or solution, AI is no exception, needs to solve a business problem in order to be successfully adopted. Knowledge graphs provide a well structured way of allowing an organization to encode the tacit knowledge and context of subject matter experts (SMEs). seeking iterative input and/or validation feedback from SMEs and end-users throughout the entire data preparation stage – ultimately, making it machine readable and consumable by downstream AI applications.
Graph Instantiation
An information extraction pipeline is the foundation of the graph instantiation stage in a knowledge graph project. The symbiotic relationship between graphs and AI holds true for this stage as well. AI-driven information extraction is a well-established process integrating cutting-edge fields of technologies that include optical character recognition, supervised machine learning, and natural language processing. Thus, it makes sense to leverage these approaches to instantiate a knowledge graph to power other AI applications. Specifically, for this stage, EK recommends considering the following components:
Entity and Relationship Extraction
This step identifies and classifies key elements from the dataset so that each extracted element can be mapped to a concept in the ontology. Next, ontological relationships can be assigned between any two such extracted concepts using both deterministic and probabilistic approaches. With the recent astronomical advances in LLM, knowledge graphs are increasingly being built using AI models, not just enabling AI use cases. EK recently completed a successful pilot for a European health organization where we used AI models on both sides of the knowledge graph; we used LLMs to instantiate the knowledge graph and used the graph database to power a graph neural network based recommendation engine.
Graph Storage
While both types of graph engines, i.e. Resource Description Framework (RDF) Graph and Labeled Property Graph (LPG), can be used to serve AI use cases, LPGs tend to be more suited for traditional AI use cases such as fraud detection, recommendation engines, and supply chain analysis. Unlike RDFs, however, LPGs follow proprietary structures which can lead to vendor lock-in. Additionally, RDFs can support inferencing at runtime meaning a RDF engine can analyze the relationships between two nodes and infer new relationships between them. According to this Forbes article, RDF engines with such advanced reasoning capabilities are considered to be the future of AI. EK has extensive experience working with both types of graph engines and can effectively recommend the appropriate engine for a given customer use case.
Data Orchestration
Data orchestration takes inaccessible and inconsistent data and makes it organized and usable in real-time. And, as mentioned before, because good data serves as the foundation for a successful AI project, a well-designed, robust, and scalable data pipeline should be the backbone of any graph data architecture to effectively manage, analyze, and contextualize the copious amount of data an organization may have and deliver faster insights for critical business problems as a result. To support effective DataOps, EK recommends choosing a platform that can run locally and scale easily (e.g., Apache Airflow). Once deployed, since such a pipeline will cover the data’s journey from collection to processing, storage and consumption, it is important to choose a data orchestration platform that has adequate governance and monitoring in place to effectively observe the data as it moves through each stage. This is especially important for monitoring data drifts, one of the top AI model quality issues organizations often have to deal with for deployed AI applications.
Path to Production
With ChatGPT being the internet sensation of this decade, every organization is trying to determine how best to integrate LLMs into their existing business processes. At the same time, it is a well-known fact that the rate of AI project failure is around 70-80%. To avoid being part of the same statistic, organizations should consider grounding their in-house LLMs in facts retrieved from a well-defined knowledge graph. When first embarking on a knowledge graph journey, however, it is important to start small. EK recommends conducting a pilot in a test environment based on the business use case that has been prioritized and the dataset or content source selected. This would create a tangible, actionable starting point for working with reliable and trustworthy LLMs in the organization. Beyond a successful pilot, EK recommends taking into account the following factors when scaling the prototype into a Minimum Viable Product (MVP) solution:
Data and User Security
As good data is key to quality AI models, ensuring that training data has not been compromised or tampered in any way is crucial for every organization working on AI. Thus, EK recommends implementing data security and access controls for all components including knowledge graphs supporting the AI ecosystem according to industry best practices. For example, EK advocates opting for a graph engine with adequate support for securing data at rest via industry standard encryption algorithms and data in transit via SSL/TLS. For authentication, EK suggests opting for a graph engine that can integrate with an external identity provider. For authorization, engines with support for granular access control is always preferred.
Graph Deployment Model
For a knowledge graph to effectively support AI in production during its training and inference process, the DevOps pipeline managing graph updates must be integrated with the MLOps pipeline managing the training data, training process, model versioning, and model monitoring for the AI application. It must also take into account scaling needs for training a production AI model. Consequently, while graph pilots can be conducted on a single graph instance, for production deployments, EK recommends utilizing a highly available distributed architecture. Additionally, for an organization to effectively integrate the graph engine into its existing infrastructure, it must assess what existing processes and platforms can be utilized for deploying the graph database.
Integration with Downstream Applications
The content in the graph must be consumable by downstream applications such as AI models and other analytical applications to support various business use cases in the organization. To support such integrations, the chosen graph engine must have good API support both in terms of functionality and documentation. Most RDF engines, for example, support the SPARQL protocol via which a graph can be queried to enhance the performance of an LLM through in-context learning. Note that it is also possible to use an LLM to write a SPARQL query so that downstream business applications can interact with the knowledge graph via natural language.
Operations and Maintenance
Similar to any other software implementation, the MVP release will not be the end of an organization’s AI journey. Model monitoring is of utmost importance post deployment to determine when a model will need to be retrained to mitigate inaccuracies. For the knowledge graph backing such an AI model, this may result in large scale edits to the graph. Furthermore, as more types of content are added to the graph to support diverse consumers, an organization must take into account the following aspects of long-term maintenance of the graph:
Graph Editing Capabilities at Scale
An organization’s data will evolve over time, and such changes must be reflected in the graph to avoid data drift issues in the downstream AI models. EK recommends employing traditional optimization strategies such as batching, query tuning, parallel processing, and hardware scaling when making significant changes to the knowledge graph instance in production.
Performance at Scale
Training AI models is a complex and resource intensive task that requires powerful hardware and software resources. For a graph backed AI model, the training data is fetched from the graph. Hence, performance considerations for such a graph database should not be neglected. EK recommends that organizations investigate the following factors when settling on a production graph architecture: 1) extremely large amounts of data, 2) reasonable query time irrespective of content size, 3) support of concurrent consumers especially true with the AI model training process leveraging distributed computing resources, 4) support for high availability, 5) maximizing use of hardware configurations such as processor cores/hardware threads.
Total Cost of Ownership
Because AI use cases can be served without a knowledge graph, it is especially important to calculate the Total Cost of Ownership (TCO) for any knowledge graph that has been created to specifically support AI applications starting with the pilot stage and ending with the operations and maintenance stage. The TCO serves as a vital component of the overall Return on Investment (ROI) calculations because effective FinOps can result in the continued support for this infrastructure in the organization.
Closing
As organizations embark on their knowledge graph journey to enable AI-driven applications in the enterprise, it is crucial to look beyond the core capabilities of the graph engine itself and instead evaluate the associated tooling and process to create, scale and maintain the graph to ensure continued support of the AI application as the data and use case evolve over time. If you are just starting out with knowledge graphs or AI or both and are looking for some additional guidance on implementation, check out our additional thought leadership and real world case studies to learn more. Our expert graph engineers and AI consultants are also on standby if you need any support. Please contact us with any questions.