
In my article, How to Prepare Content for AI, I introduced some basic steps to help you prime your organization’s content for an effective AI implementation: two of those steps – structuring and componentizing – are often misunderstood or skipped because they tend to be more difficult and time-intensive. While ‘slow down to speed up’ may not sound appealing, these steps are critical for certain kinds of content to achieve scalability and maximize your organization’s return on investment with AI.
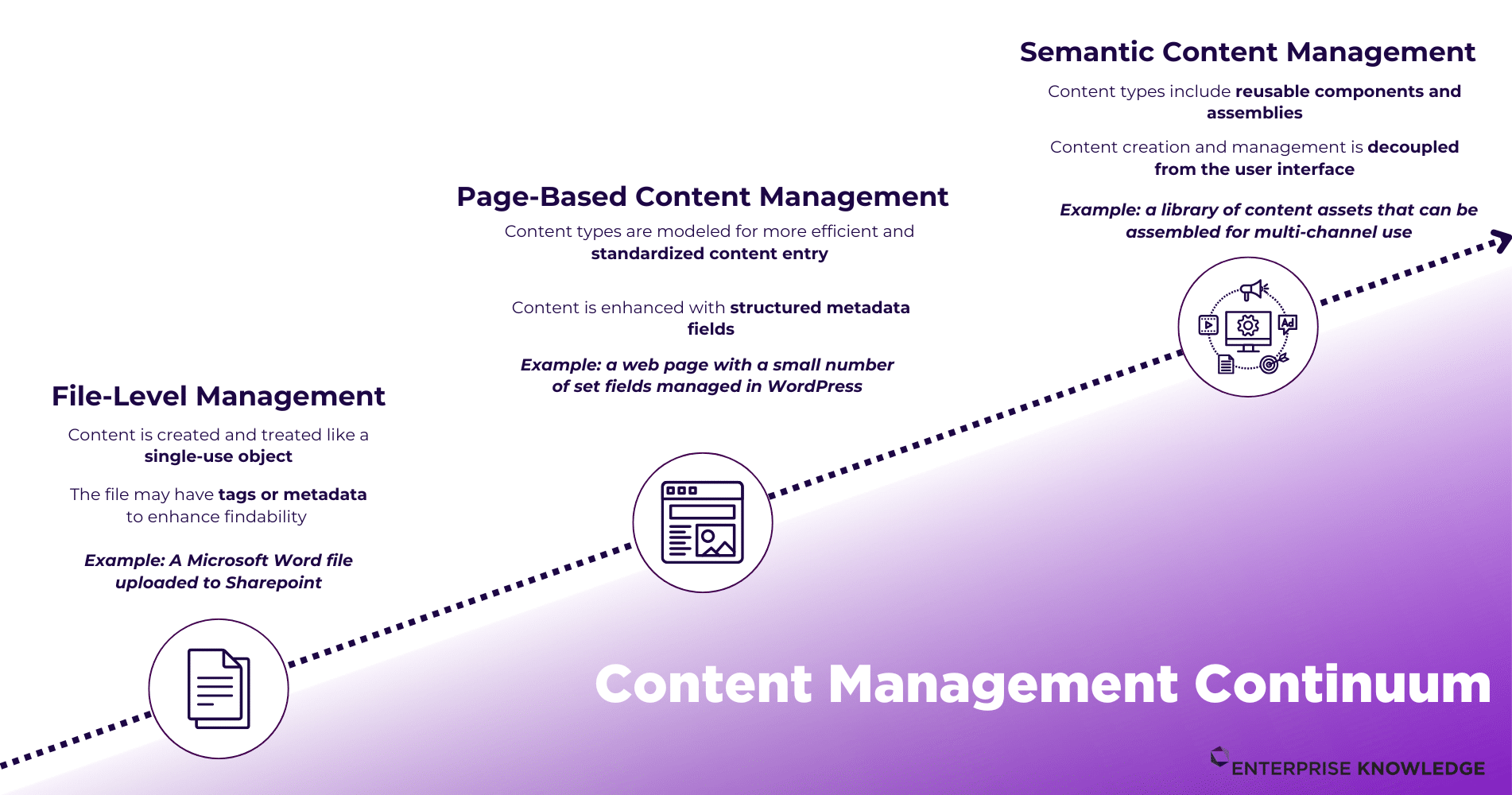
The Content Management Continuum
Before we jump in, we need to clarify that there are three major content management methods that exist on a continuum — File-Level Management, Page-Based Content Management, and Semantic Content Management.
- File-Level Management results in final output of information in the form of a document or file; there is no codified structure that exists within the document, and it is meant to be consumed as a whole.
- Page-Based Content Management gives authors a blueprint or a template to construct a page of content. For example, a proposal probably includes fields for introduction, problem statement, company description, solution approach, and references. If end users are then looking for, “what solution did we propose to Company A?,” it’s much easier to open the published page and scan for the “Solution Approach” section rather than having to parse through the entire document.
- With Semantic Content Management, you are managing smaller content components that can be reused across multiple documents, files, or assemblies. In our previous example of proposals, the “Solution Approach,” rather than being a section of a page, would be managed as a component enriched with metadata that could be reused for other proposals. While there are standard ways to enrich content and extract meaning in a more automated fashion which can improve all methods on the content management continuum, componentization can require both substantial technical and human investment to realize the return on investment (ROI).
While an overall enterprise content strategy should exist, that does not mean that every piece of content is managed in the same way. A thorough and iterative content analysis should be performed to identify how different types of content should be managed. The strategies to prepare content for AI vary based upon where it sits on the continuum, however, here we’ll be primarily focused on the Semantic Content Management end of the continuum.
Why Structure Content?
If a driver is on the side of the road with an unknown light flashing on their dashboard, they’re not going to start at the beginning of the owner’s manual and read, “How to turn the car on.” They’re going to flip to the warning lights guide, determine which warning light it is that they’re seeing, and then flip to the appropriate section for that warning light. This example illustrates a fundamental need for all documentation and other types of technical writing. It’s rare that a consumer will read the manual cover to cover in one go – it’s meant to be consumed in smaller chunks that meet a need, and we facilitate that by structuring the content to easily meet those needs. Structuring content in this manner is the beginning of the continuum into semantic content management.
How Does Structured Content Improve AI and LLM Results?
While LLMs rely on a large amount of content (hence, large language models) and can make sense of unstructured text because of the amount of data they consume, when we structure documents, we facilitate even better understanding of the content by the machine. Perhaps even more crucial, once content is broken up, we’ve improved storage and made retrieval easier and more efficient. If all of an organization’s help documentation is written in the same structure, where the introduction indicates the main topic of the article and the body of the text is broken down into important pieces of information, the LLM model has a better indication of what may be useful for any given prompt and can hone in on the answer that the user is expecting. Furthermore, if structured documents are fed into a Generative AI (or GenAI) pipeline that has been designed to provide a summary based on the introduction of a document, then the unity in structure facilitates automated extraction, improving the efficiency and accuracy of the answers to given questions, as well as tailoring the response given to match the style from the ingested content.
Why Componentize Content?
As described earlier, when using the Semantic Content Management method, you are managing smaller content components that have been broken up from larger documents, pages or files. This process of breaking content down is called componentization, but why would you take the time to do that? Componentization facilitates reuse, which at a high level:
- Reduces the amount of copies that exist and the organizational burden to manage those copies
- Creates an explicit structure of relevancy that can be referenced by humans and computers alike
- Decreases organizational risk by introducing a single source of truth
- Facilitates rapid personalization and experimentation to improve engagement
- Easily transforms into a graph for semantically precise and contextualized retrieval of information
As explained above, content structure exists on a continuum from unstructured documents to dynamic content, and every organization has to decide what is right for them and for all of their pieces of content based on a well-thought-out content strategy. For our purposes in this blog, let’s assume that your content strategy demands at least some semantically managed, componentized content and discuss how componentization improves AI results.
How Does Semantic Content Management Improve AI and LLM Results?
Why would you take the time to create components? First, on the human end, having a standard component for something as simple as an introduction or a footer improves content operations because you’re not having to hunt down the language used in other documents or running the risk of a copy/paste error. On the machine end, by indicating to the LLM that some particular component (e.g., the introduction or the footer) are the same “thing” across documents, we can simplify some of the automated workflows and extraction that occur while building the model. A standard component is important for consistency’s sake, but it also helps to indicate the component as something that’s perhaps not as relevant to the user, and that more time should be spent on the unique content. In the same way most search engines will not return “the” or “a” and indexes generally will not alphabetize using “the,” recognizing a standard introduction as one object decreases the machine load of having to intake the introduction every time.
What also is enabled by reusable components, however, is the ability to trace the network of information that can start to appear by the appearance of components across content assemblies. Perhaps you’ve written a help document about Feature A, but in using Feature A, the user also needs to use Feature B; rather than rewrite content about Feature B, you can reuse the components related to it. This then creates an explicit relationship between Feature A and Feature B and starts to facilitate the creation of a graph. When we start to model content in a semantic manner, we’re not creating models in a vacuum; they exist as part of a larger business ontology and knowledge model that work together to inform agile, dynamic, and scalable content.
Using these reusable components also decreases the risk of conflicting information in the digital experience, thereby reducing the risk of hallucinations. If in one help document you have written, “Feature A is accessible by all roles,” but then in another document it says, “you can only access Feature A if you have admin permissions,” there is now conflicting information that the LLM has to resolve through generative AI. It may be successful in being able to pull context elsewhere or make an “educated guess,” but the more contradictory information the LLM is fed, the more likely it is to have hallucinations and provide inaccurate or inappropriate responses.
The Human Element
We’ve all heard, “garbage in, garbage out.” The same adage can certainly be applied to AI, and generally if your organization is in the File Content Management end of the spectrum, it can be harder to maintain the content repository, thereby increasing the possibility of garbage existing that can then decrease the reliability of the model. It’s also important to note that it’s not just garbage that we have to be mindful of, but that an organization’s biases and quirks present in their content will also show up in LLM responses. In 2018 Safiya Noble wrote, “Algorithms of Oppression: How Search Engines Reinforce Racism.” If you’re on TikTok, you may be aware of the phrase, “I am responsible for my own algorithm,” a phrase commented when you’ve landed on one of the “weirder” videos that exist – the sum of the choices of what you’ve interacted with (and not interacted with!) brought you to the video you’re seeing now. Both of these concepts highlight the fact that AI and LLM output is highly contingent on their respective human input(s). It is not “random” or “neutral,” choices made by humans writing and constructing content influence how the LLM will respond. If your organization is operating in the Semantic Content Management sphere, you decrease the risk of “garbage” files that may exist, but you do have to be mindful of how content has been structured and who has authored the content. If your content components are missing style guides or proper governance, you run the risk of the model training on inconsistent content, thereby influencing the outputs. By doing a content audit you can circumvent this potential pitfall, and improve how your AI is being used.
The Context Element
If you’ve ever bought concert tickets, you may be familiar with the importance of a map or the context in which the ticket exists. Section 114, Row A of a stadium may be a great seat within the context of a basketball game, but could be an “obstructed view” at a Taylor Swift concert. The same is true for working with Legos – one Lego can serve many different purposes in the different sets or assemblies that exist. The almost 10,000 piece Titanic Lego set reuses much of the same bricks that you see in less complicated sets, and yet if you were to consume only the bricks and not their assembly you wouldn’t know how versatile a brick could be. This highlights the fact that AI and LLM output is improved when it “knows” the full context of a chunk of content, rather than extrapolating the context based on general knowledge it has picked up through other content it has ingested. By consuming both the component and the larger content object, as well as the metadata that enriches these two content objects, the model improves its comprehension of the content. By investing in semantic content management, and providing the LLM with a basis of context that it can train with, you are much more likely to receive a usable output from your AI investment.
Conclusion
When it comes to content and AI, there is no one-size-fits-all. Depending on your organizational needs and goals, your content could fall anywhere on the content management continuum. What is important is developing a foundational content strategy to thoughtfully and methodically manage your content in a way that meets your needs. If you’re interested in AI, structured and componentized content may be what your organization needs to improve your ROI and develop scalable, long-term success.
Need help making your investment in AI worthwhile, or defining your action plan for improving your content for AI? Check out our AI-ready Content Accelerator or contact us, we’d love to help!